Is there a documentation explaining how are working the word-vec parts of ONMT ? Is there some parameters that can be tuned ?
What exactly would you like to know? How they are trained?
What kind of architecture ? What kind of training ? How many words in the window ? What is the training rate ?.. all that can help to understand how the vectorisation is built, and how to tune it.

It’s actually a simple lookup table that is randomly initialized and updated with the gradients coming from the recurrent network at each timestep.
This explain why (since we now have the possibility to extract the embeddings) I didn’t find words grouped together by similar senses… as for a word2vec result…
1 Like
Hi @Etienne38 - why do you think so? on the graph extracted by @srush here: New Feature: Embeddings and Visualization - we can see lot of close meaning gathering. (for instance, preventing, blocking, stopping, …)
In my own experiments, I got few similar words grouped with some others, but always heavily melt with words having nothing to do with them. I’m currently making an experiment with word2vec, to see what comes with it.
In my observations, ONMT is producing this kind of distribution. For a given word, the top 100 nearest contains very few related words, mixed with a lot of unrelated ones. Best cos-dist is often around or under 0.5.
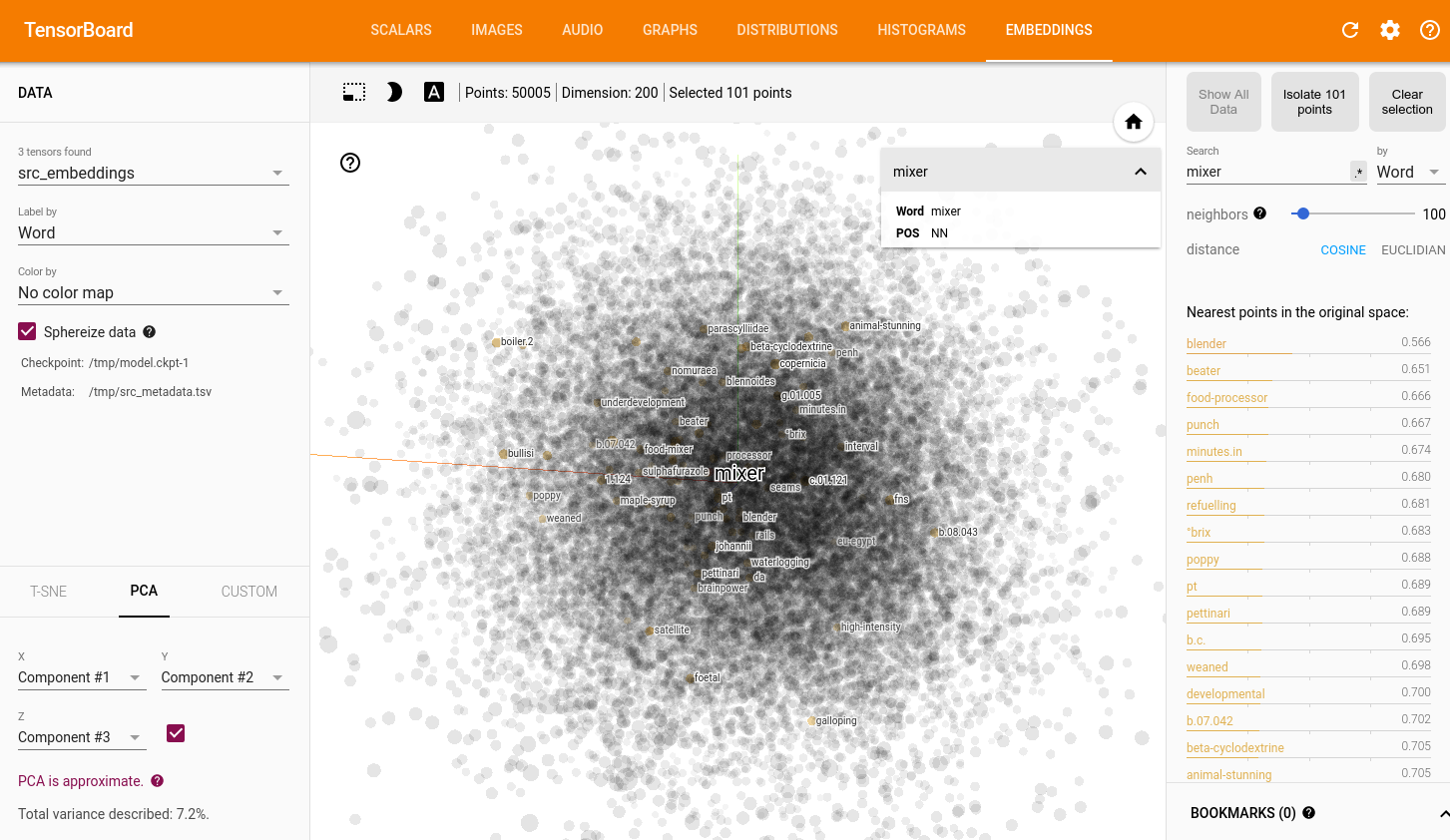
Word2vec is producing this kind of distribution. For a given word, the top 100 nearest contains a lot of related words, mixed with very few unrelated ones. Best cos-dist is often around 0.2, and top 100 are mainly over 0.5.
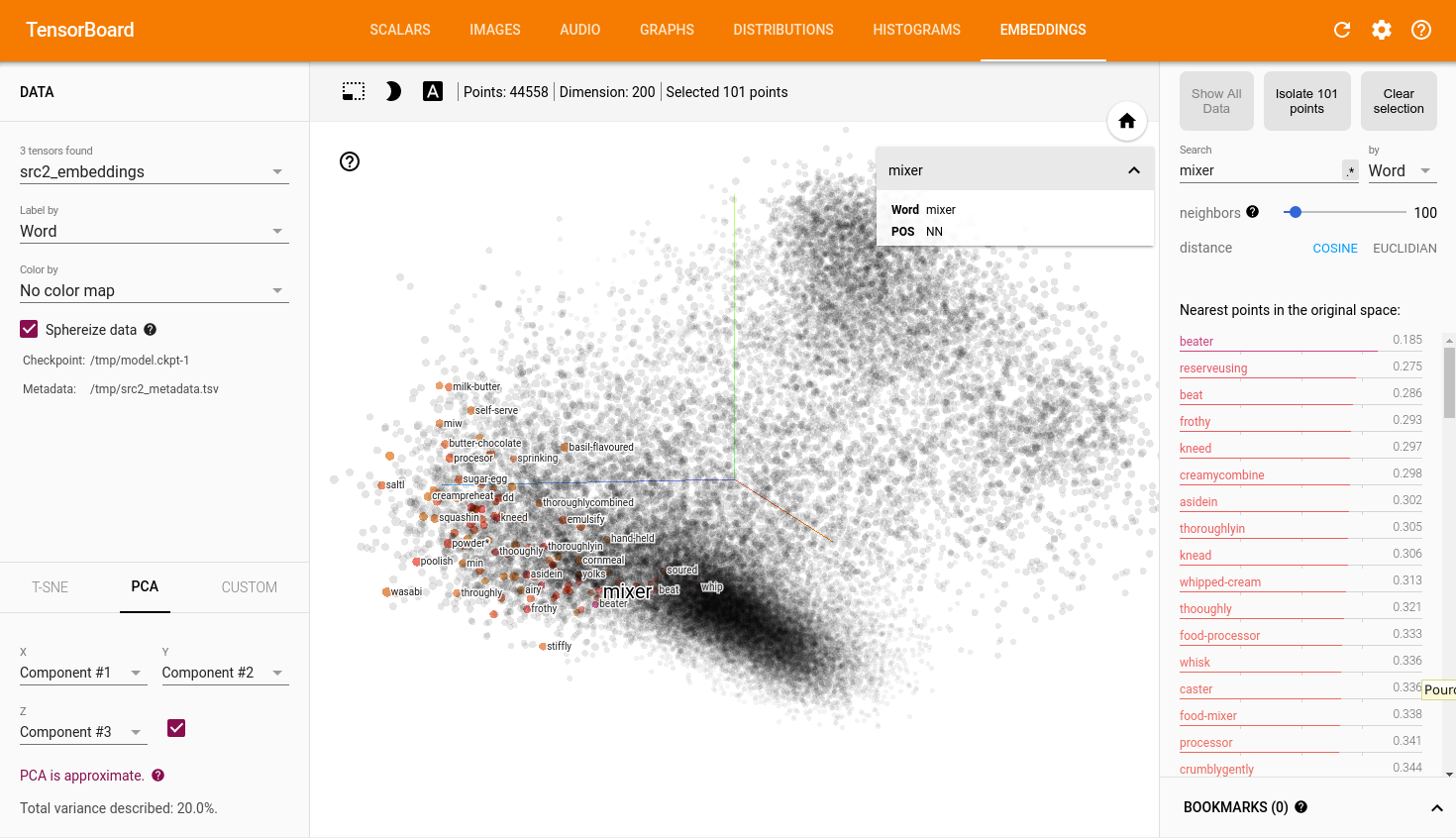
interesting! the embedding optimization is clearly different than skipgram since the goal is optimize translation. it would be very interesting to see how is a pre-trained word-embedding after onmt training.
During the 2 first epochs, ONMT is bluring w2v distribution, keeping its main global aspect. But, in fact, in this very first part of the learning, the network is fed with random values, and is searching its first draft state. Updates in the vec layers are not really pertinent.
I will now try to run 2 epochs with fixed w2v embeddings, and then, restart the learning from epoch 3 with changing embeddings. The way ONMT will change the w2v distribution, after having reached its first draft, will be more pertinent.
1 Like