By request of @Etienne38 we now have a tool for extracting embeddings from the system.
th tools/extract_embeddings.lua -model model.t7
It will produce two files src_embeddings.txt and tgt_embeddings.txt.
Each list is of the standard format:
<word> <val1> <val2> <val3> ....
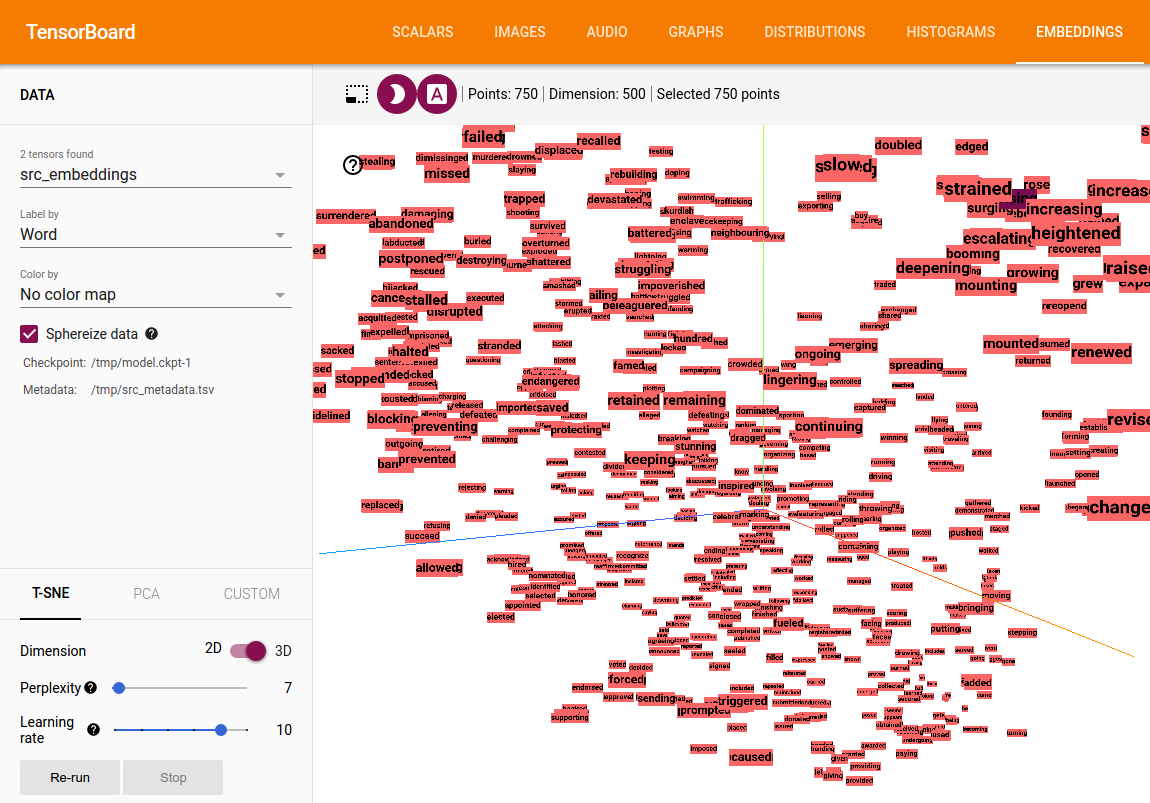
One neat aspect of this is that you can use standard visualization tools to view the embeddings. For instance here is an example where we use TensorBoard to show a 3D t-SNE embedding of all the verbs from the source side of our summarization model (https://s3.amazonaws.com/opennmt-models/textsum_epoch7_14.69_release.t7)
Here is the tensorflow code that I used (after pip install tensorflow and running extract_embeddings.lua)
import tensorflow as tf
import numpy as np
import sys, os
import nltk
def read_vecs(filename):
words = []
values = []
for l in open(filename):
t = l.split(" ")
words.append(t[0])
values.append([float(a) for a in t[1:]])
return words, np.array(values)
def write_metadata(filename, words):
with open(filename, 'w') as w:
for word in words:
w.write(word + "\t" + nltk.pos_tag([word])[0][1][:2] + "\n")
src_words, src_values = read_vecs(sys.argv[1] + "/src_embeddings.txt")
tgt_words, tgt_values = read_vecs(sys.argv[1] + "/tgt_embeddings.txt")
tf.reset_default_graph()
src_embedding_var = tf.Variable(src_values, name="src_embeddings")
tgt_embedding_var = tf.Variable(tgt_values, name="tgt_embeddings")
init = tf.global_variables_initializer()
with tf.Session() as session:
session.run(init)
saver = tf.train.Saver()
saver.save(session, "/tmp/model.ckpt", 1)
write_metadata("/tmp/src_metadata.tsv", src_words)
write_metadata("/tmp/tgt_metadata.tsv", tgt_words)
from tensorflow.contrib.tensorboard.plugins import projector
summary_writer = tf.summary.FileWriter("/tmp/")
config = projector.ProjectorConfig()
embedding = config.embeddings.add()
embedding.tensor_name = src_embedding_var.name
embedding.metadata_path = '/tmp/src_metadata.tsv'
embedding = config.embeddings.add()
embedding.tensor_name = tgt_embedding_var.name
embedding.metadata_path = '/tmp/tgt_metadata.tsv'
projector.visualize_embeddings(summary_writer, config)
os.system("tensorboard --log=/tmp/")

 !
!

