Hi ,
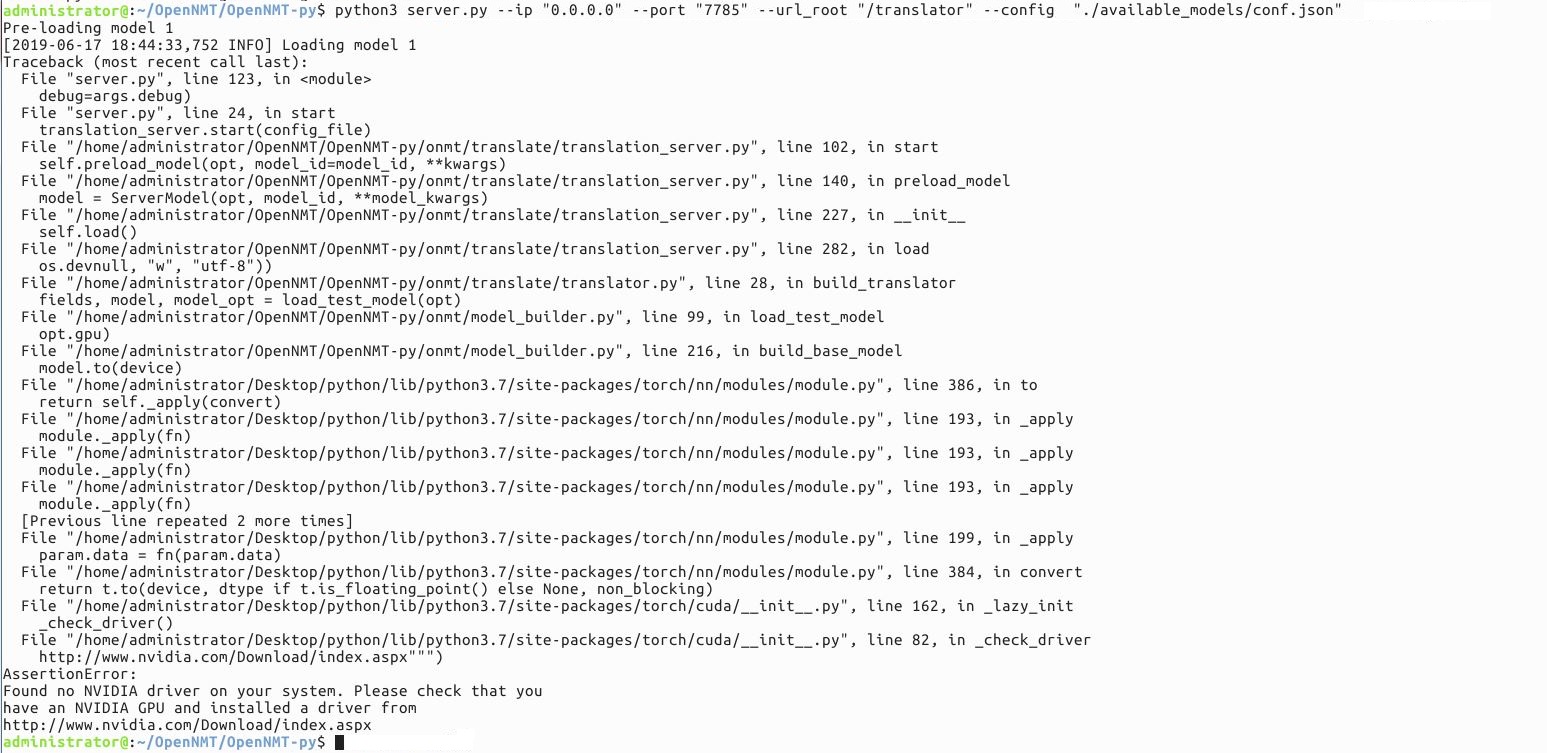
Thanks a lot for all the support. GPU error and other errors are resolved now. Presently I am facing the following error message:
administrator@:~/OpenNMT/OpenNMT-py$ python3 server.py --ip “0.0.0.0” --port “7785” --url_root “/translator” --config "./available_models/conf.json"
Pre-loading model 1
[2019-06-18 11:38:25,863 INFO] Loading model 1
[2019-06-18 11:38:32,824 INFO] Loading tokenizer
Traceback (most recent call last):
** File “server.py”, line 123, in **
** debug=args.debug)**
** File “server.py”, line 24, in start**
** translation_server.start(config_file)**
** File “/home/administrator/OpenNMT/OpenNMT-py/onmt/translate/translation_server.py”, line 102, in start**
** self.preload_model(opt, model_id=model_id, kwargs)
** File “/home/administrator/OpenNMT/OpenNMT-py/onmt/translate/translation_server.py”, line 140, in preload_model**
** model = ServerModel(opt, model_id, model_kwargs)
** File “/home/administrator/OpenNMT/OpenNMT-py/onmt/translate/translation_server.py”, line 227, in init**
** self.load()**
** File “/home/administrator/OpenNMT/OpenNMT-py/onmt/translate/translation_server.py”, line 320, in load**
** tokenizer_params)
TypeError: init(): incompatible constructor arguments. The following argument types are supported:
** 1. pyonmttok.Tokenizer(mode: str, bpe_model_path: str=’’, bpe_vocab_path: str=’’, bpe_vocab_threshold: int=50, vocabulary_path: str=’’, vocabulary_threshold: int=0, sp_model_path: str=’’, sp_nbest_size: int=0, sp_alpha: float=0.1, joiner: str=‘■’, joiner_annotate: bool=False, joiner_new: bool=False, spacer_annotate: bool=False, spacer_new: bool=False, case_feature: bool=False, case_markup: bool=False, no_substitution: bool=False, preserve_placeholders: bool=False, preserve_segmented_tokens: bool=False, segment_case: bool=False, segment_numbers: bool=False, segment_alphabet_change: bool=False, segment_alphabet: list=[])**
Invoked with: ‘conservative’; kwargs: no_substitution=False, joiner_annotate=True, joiner_new=False, case_markup=True, preserver_placeholders=True, preserver_segmented_tokens=True, segment_case=True, segment_numbers=True, segment_alphabet_change=False
administrator@:~/OpenNMT/OpenNMT-py$
Could you please assist me in resolving this issue ?
Thank you,
Kishor.