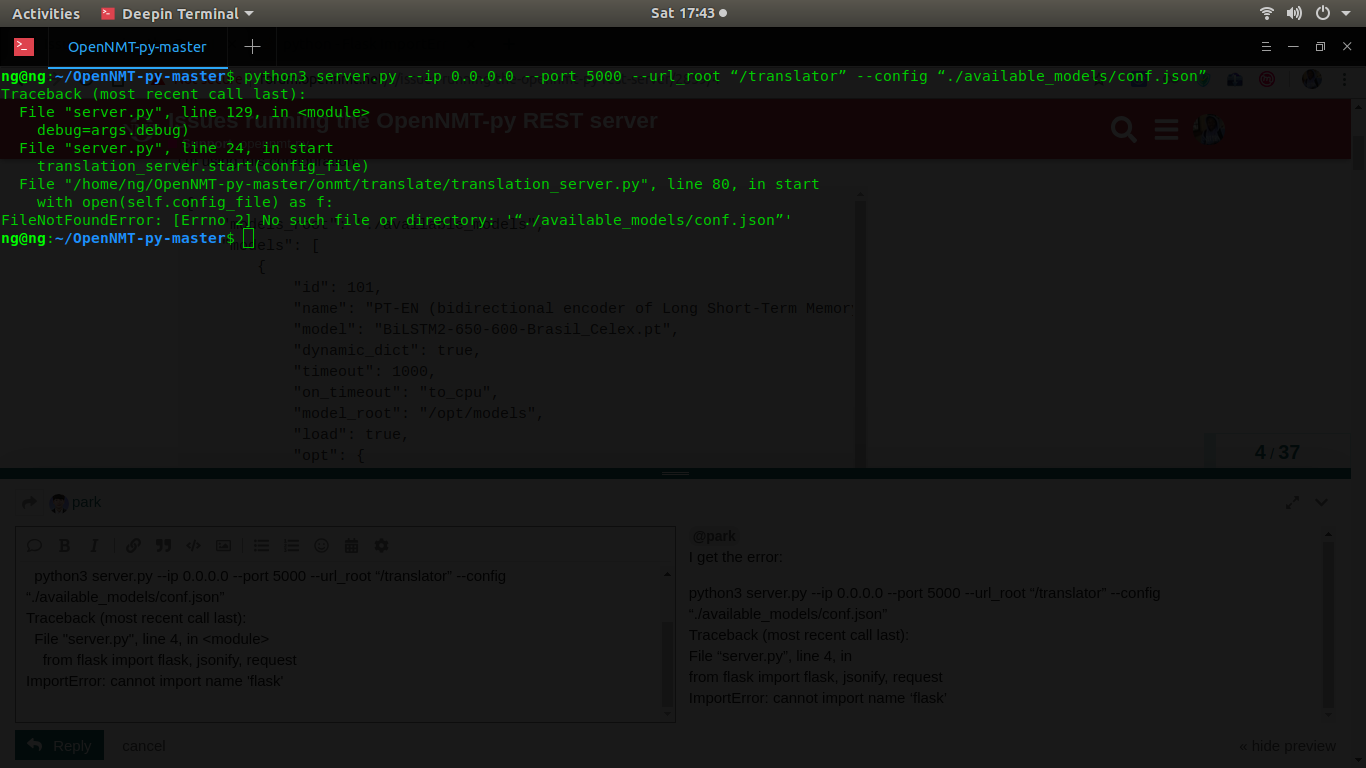
Hi ,
git pull and restarting the server.py did not help. I changed the parameters in conf.json as follows:
conf.json file:
{
“models_root”: “./available_models”,
“models”: [
{
“id”: 1,
“model”: “iwslt-brnn2.s131_acc_62.71_ppl_7.74_e20.pt”,
“timeout”: 600,
“on_timeout”: “to_cpu”,
“load”: true,
“opt”: {
“gpu”: -1,
“beam_size”: 5
},
“tokenizer”: {
“type”: “pyonmttok”,
“mode”: “str”,
“params”: {
“bpe_model_path”:"",
“vocabulary_path”:"",
“vocabulary_threshold”:0,
“sp_model_path”:"",
“sp_nbest_size”:0,
“sp_alpha”:0.1,
“joiner”:“■”,
“joiner_annotate”:false,
“joiner_new”:false,
“spacer_annotate”:false,
“spacer_new”:false,
“case_feature”:false,
“case_markup”:false,
“no_substitution”:false,
“preserve_placeholders”:false,
“preserve_segmented_tokens”:false,
“segment_case”:false,
“segment_numbers”:false,
“segment_alphabet_change”:false,
“segment_alphabet”:[]
}
}
},{
“model”: “model_0.light.pt”,
“timeout”: -1,
“on_timeout”: “unload”,
“model_root”: “…/other_models”,
“opt”: {
“batch_size”: 1,
“beam_size”: 10
}
}
]
}
the above conf parameters I got from the below link :
With the above changes I am getting the following error message:
administrator@:~/OpenNMT/OpenNMT-py$ python3 server.py --ip “0.0.0.0” --port “7785” --url_root “/translator” --config "./available_models/conf.json"
Pre-loading model 1
[2019-06-18 12:10:12,621 INFO] Loading model 1
[2019-06-18 12:10:19,179 INFO] Loading tokenizer
Traceback (most recent call last):
** File “server.py”, line 123, in **
** debug=args.debug)**
** File “server.py”, line 24, in start**
** translation_server.start(config_file)**
** File “/home/administrator/OpenNMT/OpenNMT-py/onmt/translate/translation_server.py”, line 102, in start**
** self.preload_model(opt, model_id=model_id, kwargs)
** File “/home/administrator/OpenNMT/OpenNMT-py/onmt/translate/translation_server.py”, line 140, in preload_model**
** model = ServerModel(opt, model_id, model_kwargs)
** File “/home/administrator/OpenNMT/OpenNMT-py/onmt/translate/translation_server.py”, line 227, in init**
** self.load()**
** File “/home/administrator/OpenNMT/OpenNMT-py/onmt/translate/translation_server.py”, line 319, in load**
** tokenizer = pyonmttok.Tokenizer(mode, tokenizer_params)
RuntimeError: basic_filebuf::underflow error reading the file: iostream error
administrator@:~/OpenNMT/OpenNMT-py$
Please assist me in resolving this issues as early as possible ?
Thank You,
Kishor.