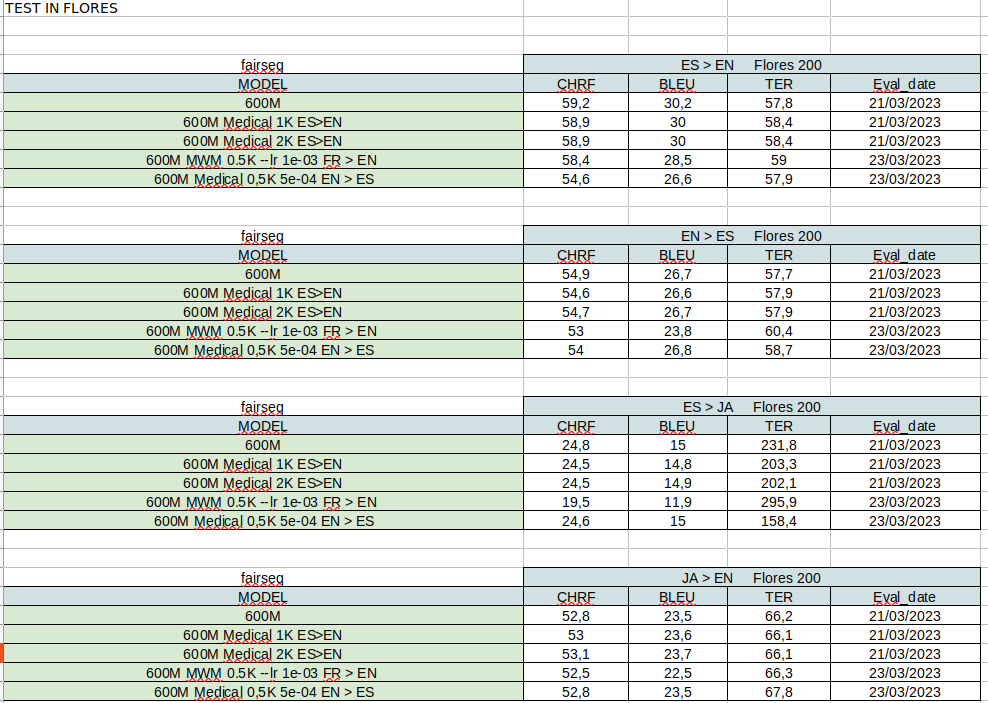
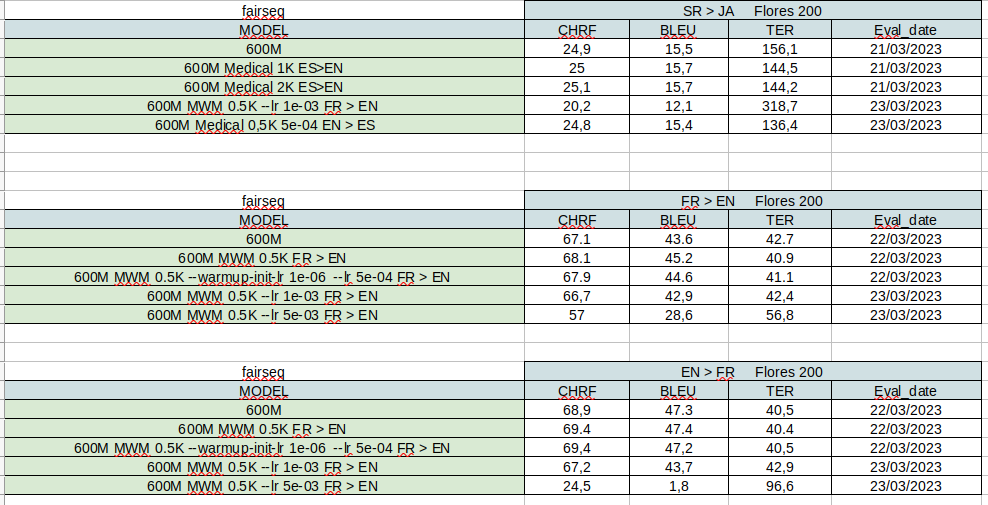
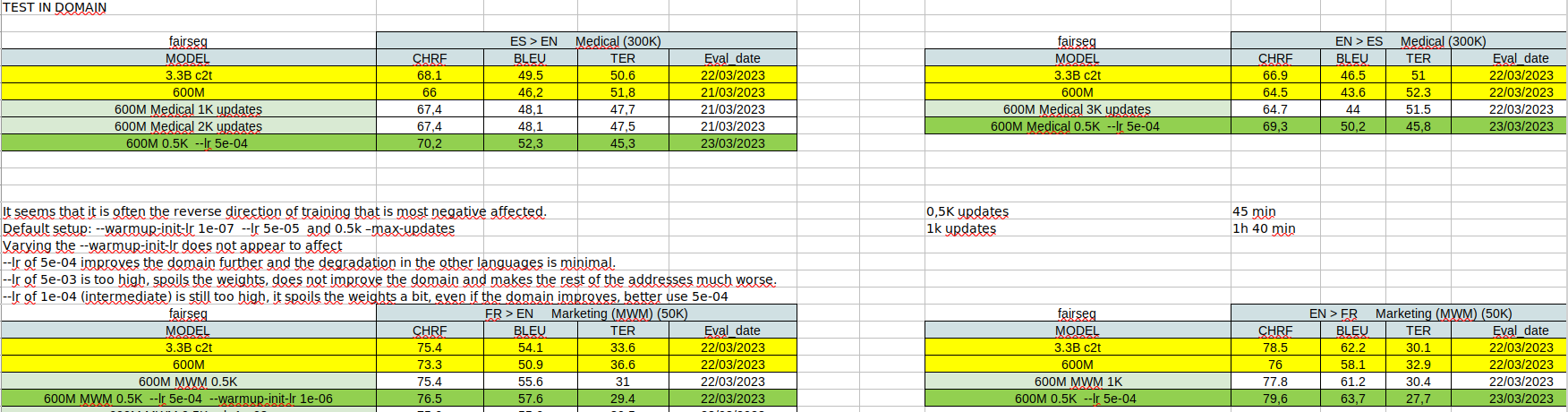
As mentioned in other posts NLLB-200 has been great for language coverage, close to SOTA for some pairs but quite poor on some others.
One very specific issue is that the dictionary is incomplete for Chinese (Han characters), there are at least 26 very common characters missing.
In this tutorial, we will explain how to fine tune and even update the vocabulary.
First, let’s look at the issue.
As a reminder, we need a specific config file to run inference in OpenNMT-py. Let’s name this config file nllb-inference.yaml.
transforms: [sentencepiece, prefix, suffix]
# nllb-200 specific prefixing and suffixing
src_prefix: "eng_Latn"
tgt_prefix: "zho_Hans"
tgt_file_prefix: true
src_suffix: "</s>"
tgt_suffix: ""
#### Subword
src_subword_model: "/nllb-200/flores200_sacrebleu_tokenizer_spm.model"
tgt_subword_model: "/nllb-200/flores200_sacrebleu_tokenizer_spm.model"
src_subword_nbest: 1
src_subword_alpha: 0.0
tgt_subword_nbest: 1
tgt_subword_alpha: 0.0
# Model info
model: "/nllb-200/nllb-200-1.3Bdst-onmt.pt"
# Inference
max_length: 512
gpu: 0
batch_type: tokens
batch_size: 2048
fp16:
beam_size: 5
report_time: true
So one prerequisite is that you download the SentencePiece model and the converted checkpoint from our S3 server.
Then you can run:
python3 ~/OpenNMT-py/translate.py --config nllb-inference.yaml -src /en-zh/testsets/newstest2019-enzh-src.en -output newstest2019-enzh-hyp.zh
Next we score:
sacrebleu /en-zh/testsets/newstest2019-enzh-ref.zh -m bleu -l en-zh -i newstest2019-enzh-hyp.zh
BLEU: 23
This is quite poor, for several reasons:
- As said before some characters are missing in the vocabulary and the SP model
- We used the 1.3B (distilled model) which is not as good as 3.3B or 54B
As a reference, SOTA is 42 and Online tools are (were at WMT19) in the range of 30-32.
Let’s curate this !
Step 1: We need to adapt the dictionary and the SentencePiece model.
When training or finetuning we need a vocab file, in the case of NLLB-200 we adapted the dictionary.txt file available on our S3 server. We added the first 4 tokens which are in different order compared to OpenNMT-py default. The beginning of the file looks like:
<s> 1
<blank> 1
</s> 1
<unk> 1
an 1
▁n 1
▁m 1
and the end of the file looks like:
ydd_Hebr 1
yor_Latn 1
yue_Hant 1
zho_Hans 1
zho_Hant 1
zul_Latn 1
<pad1> 1
<pad2> 1
<pad3> 1
there are 256206 lines.
So now we need to add the 26 missing Chinese characters, we just modify the end of the vocab file as follow:
ydd_Hebr 1
yor_Latn 1
yue_Hant 1
zho_Hans 1
zho_Hant 1
zul_Latn 1
饱 1
畅 1
湍 1
滩 1
岭 1
舱 1
诩 1
阔 1
荫 1
鸽 1
勋 1
鸡 1
鹰 1
裙 1
艳 1
哦 1
毋庸 1
稻 1
蔗 1
熔 1
亥 1
裤 1
氢 1
《 1
》 1
… 1
<pad1> 1
<pad2> 1
<pad3> 1
But one big issue is that the SentencePiece model does NOT contain those characters and it is not very straight forward to modify a SentencePiece model in place without retraining.
Here is the magic:
from unicodedata2 import *
from collections import Counter
from tqdm import tqdm
import sentencepiece as spm
import sentencepiece_model_pb2 as model
tok_exclusion = ['<s>', '<blank>', '</s>', '<unk>', 'ace_Arab', 'ace_Latn', 'acm_Arab', 'acq_Arab', 'aeb_Arab', 'afr_Latn', 'ajp_Arab', 'aka_Latn', 'amh_Ethi', 'apc_Arab', 'arb_Arab', 'ars_Arab', 'ary_Arab', 'arz_Arab', 'asm_Beng', 'ast_Latn', 'awa_Deva', 'ayr_Latn', 'azb_Arab', 'azj_Latn', 'bak_Cyrl', 'bam_Latn', 'ban_Latn', 'bel_Cyrl', 'bem_Latn', 'ben_Beng', 'bho_Deva', 'bjn_Arab', 'bjn_Latn', 'bod_Tibt', 'bos_Latn', 'bug_Latn', 'bul_Cyrl', 'cat_Latn', 'ceb_Latn', 'ces_Latn', 'cjk_Latn', 'ckb_Arab', 'crh_Latn', 'cym_Latn', 'dan_Latn', 'deu_Latn', 'dik_Latn', 'dyu_Latn', 'dzo_Tibt', 'ell_Grek', 'eng_Latn', 'epo_Latn', 'est_Latn', 'eus_Latn', 'ewe_Latn', 'fao_Latn', 'pes_Arab', 'fij_Latn', 'fin_Latn', 'fon_Latn', 'fra_Latn', 'fur_Latn', 'fuv_Latn', 'gla_Latn', 'gle_Latn', 'glg_Latn', 'grn_Latn', 'guj_Gujr', 'hat_Latn', 'hau_Latn', 'heb_Hebr', 'hin_Deva', 'hne_Deva', 'hrv_Latn', 'hun_Latn', 'hye_Armn', 'ibo_Latn', 'ilo_Latn', 'ind_Latn', 'isl_Latn', 'ita_Latn', 'jav_Latn', 'jpn_Jpan', 'kab_Latn', 'kac_Latn', 'kam_Latn', 'kan_Knda', 'kas_Arab', 'kas_Deva', 'kat_Geor', 'knc_Arab', 'knc_Latn', 'kaz_Cyrl', 'kbp_Latn', 'kea_Latn', 'khm_Khmr', 'kik_Latn', 'kin_Latn', 'kir_Cyrl', 'kmb_Latn', 'kon_Latn', 'kor_Hang', 'kmr_Latn', 'lao_Laoo', 'lvs_Latn', 'lij_Latn', 'lim_Latn', 'lin_Latn', 'lit_Latn', 'lmo_Latn', 'ltg_Latn', 'ltz_Latn', 'lua_Latn', 'lug_Latn', 'luo_Latn', 'lus_Latn', 'mag_Deva', 'mai_Deva', 'mal_Mlym', 'mar_Deva', 'min_Latn', 'mkd_Cyrl', 'plt_Latn', 'mlt_Latn', 'mni_Beng', 'khk_Cyrl', 'mos_Latn', 'mri_Latn', 'zsm_Latn', 'mya_Mymr', 'nld_Latn', 'nno_Latn', 'nob_Latn', 'npi_Deva', 'nso_Latn', 'nus_Latn', 'nya_Latn', 'oci_Latn', 'gaz_Latn', 'ory_Orya', 'pag_Latn', 'pan_Guru', 'pap_Latn', 'pol_Latn', 'por_Latn', 'prs_Arab', 'pbt_Arab', 'quy_Latn', 'ron_Latn', 'run_Latn', 'rus_Cyrl', 'sag_Latn', 'san_Deva', 'sat_Beng', 'scn_Latn', 'shn_Mymr', 'sin_Sinh', 'slk_Latn', 'slv_Latn', 'smo_Latn', 'sna_Latn', 'snd_Arab', 'som_Latn', 'sot_Latn', 'spa_Latn', 'als_Latn', 'srd_Latn', 'srp_Cyrl', 'ssw_Latn', 'sun_Latn', 'swe_Latn', 'swh_Latn', 'szl_Latn', 'tam_Taml', 'tat_Cyrl', 'tel_Telu', 'tgk_Cyrl', 'tgl_Latn', 'tha_Thai', 'tir_Ethi', 'taq_Latn', 'taq_Tfng', 'tpi_Latn', 'tsn_Latn', 'tso_Latn', 'tuk_Latn', 'tum_Latn', 'tur_Latn', 'twi_Latn', 'tzm_Tfng', 'uig_Arab', 'ukr_Cyrl', 'umb_Latn', 'urd_Arab', 'uzn_Latn', 'vec_Latn', 'vie_Latn', 'war_Latn', 'wol_Latn', 'xho_Latn', 'ydd_Hebr', 'yor_Latn', 'yue_Hant', 'zho_Hans', 'zho_Hant', 'zul_Latn', '<pad1>', '<pad2>', '<pad3>', '<inv>']
newdict2 = []
with open('/nllb-200/dictionary2.txt', 'r', encoding='utf-8') as f:
for line in f:
token = line.strip().split()[0]
newdict2.append(token)
serializedStr=open('/nllb-200/flores200_sacrebleu_tokenizer_spm.model', 'rb').read()
m=model.ModelProto()
m.ParseFromString(serializedStr)
curdict = []
for i in tqdm(range(len(m.pieces) - 1, 2, -1)):
curdict.append(m.pieces[i].piece)
if m.pieces[i].piece not in newdict2:
hex_string = "".join("{:02x}".format(ord(c)) for c in m.pieces[i].piece)
print("Removing: ", hex_string, " from spm model, not in dict. Index: ", i)
m.pieces.pop(i)
for tok in tqdm(newdict2):
if (tok not in curdict) and (tok not in tok_exclusion):
print("Adding: ", tok, " to spm model")
newtoken = m.SentencePiece()
newtoken.piece = tok
newtoken.score = 0
m.pieces.append(newtoken)
print(len(m.pieces))
with open('/nllb-200/flores200_sacrebleu_tokenizer_spm2.model', 'wb') as f:
f.write(m.SerializeToString())
Without going into too much details, the first tqdm loop will remove from the SPM model tokens that are not in the dictionary.txt file (this step is not necessary but it was a sanity check) and the second tqdm loop will add tokens that are in the dictionary.txt file in the SPM model, given that we don’t want the language tokens nor special tokens in the spm model.
Now let’s finetune !
To finetune NLLB-200, we need a yaml config file that require those sections:
share_vocab: true
src_vocab: "/nllb-200/dictionary2.txt"
src_words_min_frequency: 1
src_vocab_size: 256232
tgt_vocab: "/nllb-200/dictionary2.txt"
tgt_words_min_frequency: 1
tgt_vocab_size: 256232
vocab_size_multiple: 1
decoder_start_token: '</s>'
#### Subword
src_subword_model: "/nllb-200/flores200_sacrebleu_tokenizer_spm2.model"
tgt_subword_model: "/nllb-200/flores200_sacrebleu_tokenizer_spm2.model"
src_subword_nbest: 1
src_subword_alpha: 0.0
tgt_subword_nbest: 1
tgt_subword_alpha: 0.0
# Corpus opts:
data:
cc-matrix-enzh:
path_src: "/en-zh/cc-matrix-enzh-0to30M.en"
path_tgt: "/en-zh/cc-matrix-enzh-0to30M.zh"
transforms: [sentencepiece, prefix, suffix, filtertoolong]
weight: 10
src_prefix: "</s> eng_Latn"
tgt_prefix: "zho_Hans"
src_suffix: ""
tgt_suffix: ""
update_vocab: true
train_from: "/nllb-200/nllb-200-1.3Bdst-onmt.pt"
reset_optim: all
save_data: "/nllb-200"
save_model: "/nllb-200/nllb-200-1.3B-onmt"
log_file: "/nllb-200/nllb-200-1.3B-onmt.log"
keep_checkpoint: 50
save_checkpoint_steps: 100
average_decay: 0.0005
seed: 1234
report_every: 10
train_steps: 2000
valid_steps: 100
# Batching
bucket_size: 262144
num_workers: 4
prefetch_factor: 400
world_size: 1
gpu_ranks: [0]
batch_type: "tokens"
batch_size: 384
valid_batch_size: 384
batch_size_multiple: 1
accum_count: [32, 32, 32]
accum_steps: [0, 15000, 30000]
# Optimization
model_dtype: "fp16"
optim: "sgd"
learning_rate: 30
warmup_steps: 100
decay_method: "noam"
adam_beta2: 0.98
max_grad_norm: 0
label_smoothing: 0.1
param_init: 0
param_init_glorot: true
normalization: "tokens"
# Model
override_opts: true
encoder_type: transformer
decoder_type: transformer
enc_layers: 24
dec_layers: 24
heads: 16
hidden_size: 1024
word_vec_size: 1024
transformer_ff: 8192
add_qkvbias: true
add_ffnbias: true
dropout_steps: [0, 15000, 30000]
dropout: [0.1, 0.1, 0.1]
attention_dropout: [0.1, 0.1, 0.1]
share_decoder_embeddings: true
share_embeddings: true
position_encoding: true
position_encoding_type: 'SinusoidalConcat'
Add as many datasets as you want ( I used cc-matrix, paracrawl and new-commentary for this test),
then run:
python3 train.py --config /nllb-200/nllb-train.yaml
If your training accuracy / ppl is off even for the first steps, then somehting is wrong with your config.
We use SGD because on a RTX 4090 (24GB) Adam would not fit with this 1.3B model.
Then we score after 2000 steps:
sacrebleu /en-zh/testsets/newstest2019-enzh-ref.zh -m bleu -l en-zh -i newstest2019-enzh-hyp.zh
{
"name": "BLEU",
"score": 29.2,
"signature": "nrefs:1|case:mixed|eff:no|tok:zh|smooth:exp|version:2.0.0",
"verbose_score": "63.8/40.2/26.0/17.6 (BP = 0.886 ratio = 0.892 hyp_len = 71982 ref_len = 80666)",
"nrefs": "1",
"case": "mixed",
"eff": "no",
"tok": "zh",
"smooth": "exp",
"version": "2.0.0"
}
Not bad !
I did the same with EN-DE and was able to improve the BLEU score of NT2019 from 41.3 to 42.7 for a SOTA of about 45. I tested that the model did not lose (actually it gained on the the EN-FR test set…)
Bear in mind that with a 24GB RTX card you cannot fit the 3.3B model until we implement some kind of trick like LoRa or FSDP.
This tuto can be used to finetune any kind of language, add a new language, curate some missing characters.
Enjoy !