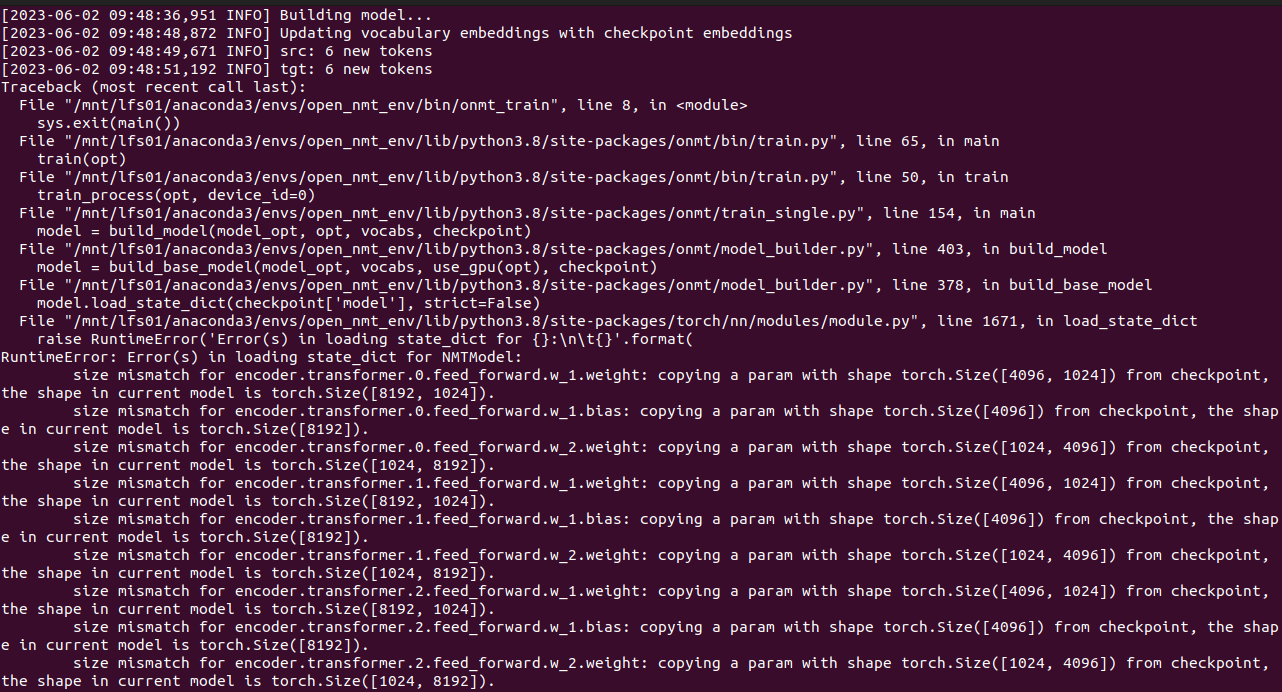
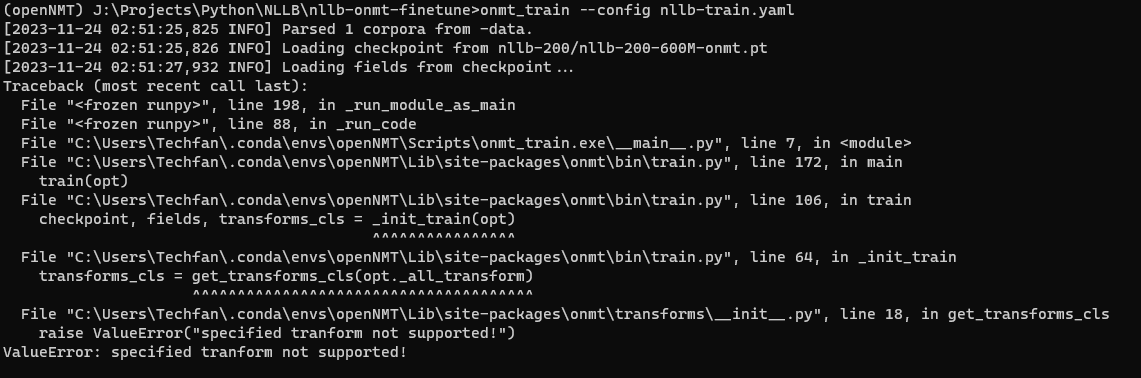
Hi @vince62s ,
Sorry for the late reply.
I had tried what you have suggested. Keeping same settings in train and inference config. Attaching the config files and log here.
nllb-train.yaml
share_vocab: true
src_vocab: "nllb-200/dictionary2.txt"
src_words_min_frequency: 1
src_vocab_size: 256212
tgt_vocab: "nllb-200/dictionary2.txt"
tgt_words_min_frequency: 1
tgt_vocab_size: 256212
vocab_size_multiple: 1
decoder_start_token: '</s>'
#### Subword
src_subword_model: "nllb-200/flores200_sacrebleu_tokenizer_spm2.model"
tgt_subword_model: "nllb-200/flores200_sacrebleu_tokenizer_spm2.model"
src_subword_nbest: 1
src_subword_alpha: 0.0
tgt_subword_nbest: 1
tgt_subword_alpha: 0.0
# Corpus opts:
data:
bible_data:
path_src: "bible_data/hin-har/src-train.hin"
path_tgt: "bible_data/hin-har/tgt-train.har"
transforms: [sentencepiece, prefix, suffix, filtertoolong]
weight: 10
src_prefix: "hin_Deva"
tgt_prefix: "har_Deva"
src_suffix: ""
tgt_suffix: ""
update_vocab: true
train_from: "nllb-200/nllb-200-600M-onmt.pt"
reset_optim: all
save_data: "nllb-200"
save_model: "nllb-200/2nllb-200-600M-onmt_2000_steps"
log_file: "nllb-200/nllb-200-600M-onmt.log"
keep_checkpoint: 50
save_checkpoint_steps: 2000
average_decay: 0.0005
seed: 1234
report_every: 10
train_steps: 2000
valid_steps: 100
# Batching
bucket_size: 262144
num_workers: 4
prefetch_factor: 400
world_size: 1
gpu_ranks: [0]
batch_type: "tokens"
batch_size: 384
valid_batch_size: 384
batch_size_multiple: 1
accum_count: [32, 32, 32]
accum_steps: [0, 15000, 30000]
# Optimization
model_dtype: "fp16"
optim: "sgd"
learning_rate: 30
warmup_steps: 100
decay_method: "noam"
adam_beta2: 0.98
max_grad_norm: 0
label_smoothing: 0.1
param_init: 0
param_init_glorot: true
normalization: "tokens"
# Model
override_opts: true
encoder_type: transformer
decoder_type: transformer
enc_layers: 24
dec_layers: 24
heads: 16
hidden_size: 1024
word_vec_size: 1024
transformer_ff: 4096
dropout_steps: [0, 15000, 30000]
dropout: [0.1, 0.1, 0.1]
attention_dropout: [0.1, 0.1, 0.1]
share_decoder_embeddings: true
share_embeddings: true
position_encoding: true
position_encoding_type: 'SinusoidalConcat'
nllb-inference.yaml:
transforms: [sentencepiece, prefix, suffix]
# nllb-200 specific prefixing and suffixing
src_prefix: "hin_Deva"
tgt_prefix: "har_Deva"
tgt_file_prefix: true
src_suffix: ""
tgt_suffix: ""
#### Subword
src_subword_model: "nllb-200/flores200_sacrebleu_tokenizer_spm2.model"
tgt_subword_model: "nllb-200/flores200_sacrebleu_tokenizer_spm2.model"
src_subword_nbest: 1
src_subword_alpha: 0.0
tgt_subword_nbest: 1
tgt_subword_alpha: 0.0
# Model info
model: "nllb-200/2nllb-200-600M-onmt_2000_steps_step_2000.pt"
# Inference
max_length: 512
gpu: 0
batch_type: tokens
batch_size: 2048
fp16:
beam_size: 5
report_time: true
Not able to post full training log as showing number of lines exceeded.
training log
[2023-06-21 16:46:48,871 INFO] Parsed 1 corpora from -data.
[2023-06-21 16:46:48,888 INFO] Loading checkpoint from nllb-200/nllb-200-600M-onmt.pt
[2023-06-21 16:47:06,693 WARNING] configured transforms is different from checkpoint: +{'sentencepiece', 'prefix', 'suffix'}
[2023-06-21 16:47:06,693 INFO] Get prefix for bible_data: {'src': 'hin_Deva', 'tgt': 'har_Deva'}
[2023-06-21 16:47:06,693 INFO] Get prefix for src infer:
[2023-06-21 16:47:06,693 INFO] Get prefix for tgt infer:
[2023-06-21 16:47:06,693 INFO] Get suffix for bible_data: {'src': '', 'tgt': ''}
[2023-06-21 16:47:06,693 INFO] Get suffix for src infer:
[2023-06-21 16:47:06,693 INFO] Get suffix for tgt infer:
[2023-06-21 16:47:06,693 INFO] Get special vocabs from Transforms: {'src': ['hin_Deva'], 'tgt': ['har_Deva']}.
[2023-06-21 16:47:07,110 INFO] Updating checkpoint vocabulary with new vocabulary
[2023-06-21 16:47:07,112 INFO] Get prefix for bible_data: {'src': 'hin_Deva', 'tgt': 'har_Deva'}
[2023-06-21 16:47:07,113 INFO] Get prefix for src infer:
[2023-06-21 16:47:07,114 INFO] Get prefix for tgt infer:
[2023-06-21 16:47:07,115 INFO] Get suffix for bible_data: {'src': '', 'tgt': ''}
[2023-06-21 16:47:07,117 INFO] Get suffix for src infer:
[2023-06-21 16:47:07,118 INFO] Get suffix for tgt infer:
[2023-06-21 16:47:07,120 INFO] Get special vocabs from Transforms: {'src': ['hin_Deva'], 'tgt': ['har_Deva']}.
[2023-06-21 16:47:07,575 INFO] Building model...
[2023-06-21 16:47:16,739 INFO] Updating vocabulary embeddings with checkpoint embeddings
[2023-06-21 16:47:17,551 INFO] src: 6 new tokens
[2023-06-21 16:47:19,140 INFO] tgt: 6 new tokens
[2023-06-21 16:47:26,729 INFO] NMTModel(
(encoder): TransformerEncoder(
(embeddings): Embeddings(
(make_embedding): Sequential(
(emb_luts): Elementwise(
(0): Embedding(256212, 1024, padding_idx=1)
)
(pe): PositionalEncoding()
)
(dropout): Dropout(p=0.1, inplace=False)
)
(transformer): ModuleList(
(0): TransformerEncoderLayer(
(self_attn): MultiHeadedAttention(
(linear_keys): Linear(in_features=1024, out_features=1024, bias=False)
(linear_values): Linear(in_features=1024, out_features=1024, bias=False)
(linear_query): Linear(in_features=1024, out_features=1024, bias=False)
(softmax): Softmax(dim=-1)
(dropout): Dropout(p=0.1, inplace=False)
(final_linear): Linear(in_features=1024, out_features=1024, bias=False)
)
(feed_forward): PositionwiseFeedForward(
(w_1): Linear(in_features=1024, out_features=4096, bias=True)
(w_2): Linear(in_features=4096, out_features=1024, bias=True)
(layer_norm): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(dropout_1): Dropout(p=0.1, inplace=False)
(dropout_2): Dropout(p=0.1, inplace=False)
)
(layer_norm): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(1): TransformerEncoderLayer(
(self_attn): MultiHeadedAttention(
(linear_keys): Linear(in_features=1024, out_features=1024, bias=False)
(linear_values): Linear(in_features=1024, out_features=1024, bias=False)
(linear_query): Linear(in_features=1024, out_features=1024, bias=False)
(softmax): Softmax(dim=-1)
(dropout): Dropout(p=0.1, inplace=False)
(final_linear): Linear(in_features=1024, out_features=1024, bias=False)
)
(feed_forward): PositionwiseFeedForward(
(w_1): Linear(in_features=1024, out_features=4096, bias=True)
(w_2): Linear(in_features=4096, out_features=1024, bias=True)
(layer_norm): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(dropout_1): Dropout(p=0.1, inplace=False)
(dropout_2): Dropout(p=0.1, inplace=False)
)
(layer_norm): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
.
.
.
(23): TransformerEncoderLayer(
(self_attn): MultiHeadedAttention(
(linear_keys): Linear(in_features=1024, out_features=1024, bias=False)
(linear_values): Linear(in_features=1024, out_features=1024, bias=False)
(linear_query): Linear(in_features=1024, out_features=1024, bias=False)
(softmax): Softmax(dim=-1)
(dropout): Dropout(p=0.1, inplace=False)
(final_linear): Linear(in_features=1024, out_features=1024, bias=False)
)
(feed_forward): PositionwiseFeedForward(
(w_1): Linear(in_features=1024, out_features=4096, bias=True)
(w_2): Linear(in_features=4096, out_features=1024, bias=True)
(layer_norm): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(dropout_1): Dropout(p=0.1, inplace=False)
(dropout_2): Dropout(p=0.1, inplace=False)
)
(layer_norm): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(layer_norm): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
)
(decoder): TransformerDecoder(
(embeddings): Embeddings(
(make_embedding): Sequential(
(emb_luts): Elementwise(
(0): Embedding(256212, 1024, padding_idx=1)
)
(pe): PositionalEncoding()
)
(dropout): Dropout(p=0.1, inplace=False)
)
(layer_norm): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(transformer_layers): ModuleList(
(0): TransformerDecoderLayer(
(self_attn): MultiHeadedAttention(
(linear_keys): Linear(in_features=1024, out_features=1024, bias=False)
(linear_values): Linear(in_features=1024, out_features=1024, bias=False)
(linear_query): Linear(in_features=1024, out_features=1024, bias=False)
(softmax): Softmax(dim=-1)
(dropout): Dropout(p=0.1, inplace=False)
(final_linear): Linear(in_features=1024, out_features=1024, bias=False)
)
(feed_forward): PositionwiseFeedForward(
(w_1): Linear(in_features=1024, out_features=4096, bias=True)
(w_2): Linear(in_features=4096, out_features=1024, bias=True)
(layer_norm): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(dropout_1): Dropout(p=0.1, inplace=False)
(dropout_2): Dropout(p=0.1, inplace=False)
)
(layer_norm_1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(drop): Dropout(p=0.1, inplace=False)
(context_attn): MultiHeadedAttention(
(linear_keys): Linear(in_features=1024, out_features=1024, bias=False)
(linear_values): Linear(in_features=1024, out_features=1024, bias=False)
(linear_query): Linear(in_features=1024, out_features=1024, bias=False)
(softmax): Softmax(dim=-1)
(dropout): Dropout(p=0.1, inplace=False)
(final_linear): Linear(in_features=1024, out_features=1024, bias=False)
)
(layer_norm_2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
)
(1): TransformerDecoderLayer(
(self_attn): MultiHeadedAttention(
(linear_keys): Linear(in_features=1024, out_features=1024, bias=False)
(linear_values): Linear(in_features=1024, out_features=1024, bias=False)
(linear_query): Linear(in_features=1024, out_features=1024, bias=False)
(softmax): Softmax(dim=-1)
(dropout): Dropout(p=0.1, inplace=False)
(final_linear): Linear(in_features=1024, out_features=1024, bias=False)
)
(feed_forward): PositionwiseFeedForward(
(w_1): Linear(in_features=1024, out_features=4096, bias=True)
(w_2): Linear(in_features=4096, out_features=1024, bias=True)
(layer_norm): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(dropout_1): Dropout(p=0.1, inplace=False)
(dropout_2): Dropout(p=0.1, inplace=False)
)
(layer_norm_1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(drop): Dropout(p=0.1, inplace=False)
(context_attn): MultiHeadedAttention(
(linear_keys): Linear(in_features=1024, out_features=1024, bias=False)
(linear_values): Linear(in_features=1024, out_features=1024, bias=False)
(linear_query): Linear(in_features=1024, out_features=1024, bias=False)
(softmax): Softmax(dim=-1)
(dropout): Dropout(p=0.1, inplace=False)
(final_linear): Linear(in_features=1024, out_features=1024, bias=False)
)
(layer_norm_2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
)
.
.
.
(23): TransformerDecoderLayer(
(self_attn): MultiHeadedAttention(
(linear_keys): Linear(in_features=1024, out_features=1024, bias=False)
(linear_values): Linear(in_features=1024, out_features=1024, bias=False)
(linear_query): Linear(in_features=1024, out_features=1024, bias=False)
(softmax): Softmax(dim=-1)
(dropout): Dropout(p=0.1, inplace=False)
(final_linear): Linear(in_features=1024, out_features=1024, bias=False)
)
(feed_forward): PositionwiseFeedForward(
(w_1): Linear(in_features=1024, out_features=4096, bias=True)
(w_2): Linear(in_features=4096, out_features=1024, bias=True)
(layer_norm): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(dropout_1): Dropout(p=0.1, inplace=False)
(dropout_2): Dropout(p=0.1, inplace=False)
)
(layer_norm_1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(drop): Dropout(p=0.1, inplace=False)
(context_attn): MultiHeadedAttention(
(linear_keys): Linear(in_features=1024, out_features=1024, bias=False)
(linear_values): Linear(in_features=1024, out_features=1024, bias=False)
(linear_query): Linear(in_features=1024, out_features=1024, bias=False)
(softmax): Softmax(dim=-1)
(dropout): Dropout(p=0.1, inplace=False)
(final_linear): Linear(in_features=1024, out_features=1024, bias=False)
)
(layer_norm_2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
)
)
)
(generator): Linear(in_features=1024, out_features=256212, bias=True)
)
[2023-06-21 16:47:26,736 INFO] encoder: 564574208
[2023-06-21 16:47:26,736 INFO] decoder: 403181780
[2023-06-21 16:47:26,736 INFO] * number of parameters: 967755988
[2023-06-21 16:47:26,736 INFO] * src vocab size = 256212
[2023-06-21 16:47:26,736 INFO] * tgt vocab size = 256212
[2023-06-21 16:47:26,823 INFO] Get prefix for bible_data: {'src': 'hin_Deva', 'tgt': 'har_Deva'}
[2023-06-21 16:47:26,823 INFO] Get prefix for src infer:
[2023-06-21 16:47:26,823 INFO] Get prefix for tgt infer:
[2023-06-21 16:47:26,823 INFO] Get suffix for bible_data: {'src': '', 'tgt': ''}
[2023-06-21 16:47:26,823 INFO] Get suffix for src infer:
[2023-06-21 16:47:26,823 INFO] Get suffix for tgt infer:
[2023-06-21 16:47:26,866 INFO] Get prefix for bible_data: {'src': 'hin_Deva', 'tgt': 'har_Deva'}
[2023-06-21 16:47:26,866 INFO] Get prefix for src infer:
[2023-06-21 16:47:26,866 INFO] Get prefix for tgt infer:
[2023-06-21 16:47:26,866 INFO] Get suffix for bible_data: {'src': '', 'tgt': ''}
[2023-06-21 16:47:26,866 INFO] Get suffix for src infer:
[2023-06-21 16:47:26,866 INFO] Get suffix for tgt infer:
[2023-06-21 16:47:26,893 INFO] Starting training on GPU: [0]
[2023-06-21 16:47:26,893 INFO] Start training loop without validation...
[2023-06-21 16:47:26,893 INFO] Scoring with: TransformPipe()
[2023-06-21 16:49:08,263 INFO] Step 10/ 2000; acc: 3.1; ppl: 45189.8; xent: 10.7; lr: 0.01031; sents: 2484; bsz: 244/ 348/ 8; 770/1098 tok/s; 101 sec;
[2023-06-21 16:49:49,802 INFO] Step 20/ 2000; acc: 9.7; ppl: 1709.6; xent: 7.4; lr: 0.01969; sents: 2300; bsz: 242/ 348/ 7; 1868/2683 tok/s; 143 sec;
[2023-06-21 16:50:31,358 INFO] Step 30/ 2000; acc: 15.2; ppl: 722.0; xent: 6.6; lr: 0.02906; sents: 2189; bsz: 239/ 346/ 7; 1844/2662 tok/s; 184 sec;
[2023-06-21 16:51:13,050 INFO] Step 40/ 2000; acc: 19.3; ppl: 463.1; xent: 6.1; lr: 0.03844; sents: 2295; bsz: 242/ 348/ 7; 1859/2674 tok/s; 226 sec;
[2023-06-21 16:51:54,659 INFO] Step 50/ 2000; acc: 22.0; ppl: 337.4; xent: 5.8; lr: 0.04781; sents: 2148; bsz: 239/ 348/ 7; 1841/2675 tok/s; 268 sec;
[2023-06-21 16:52:36,455 INFO] Step 60/ 2000; acc: 24.5; ppl: 263.4; xent: 5.6; lr: 0.05719; sents: 2297; bsz: 243/ 348/ 7; 1863/2668 tok/s; 310 sec;
[2023-06-21 16:53:18,253 INFO] Step 70/ 2000; acc: 27.8; ppl: 217.8; xent: 5.4; lr: 0.06656; sents: 2343; bsz: 244/ 348/ 7; 1865/2664 tok/s; 351 sec;
[2023-06-21 16:54:00,225 INFO] Step 80/ 2000; acc: 29.9; ppl: 188.5; xent: 5.2; lr: 0.07594; sents: 2361; bsz: 245/ 351/ 7; 1867/2677 tok/s; 393 sec;
[2023-06-21 16:54:42,041 INFO] Step 90/ 2000; acc: 31.1; ppl: 169.5; xent: 5.1; lr: 0.08531; sents: 2132; bsz: 240/ 348/ 7; 1840/2663 tok/s; 435 sec;
[2023-06-21 16:55:23,932 INFO] Step 100/ 2000; acc: 33.6; ppl: 145.6; xent: 5.0; lr: 0.09328; sents: 2342; bsz: 244/ 347/ 7; 1862/2652 tok/s; 477 sec;
[2023-06-21 16:55:23,932 INFO] Train perplexity: 544.799
[2023-06-21 16:55:23,932 INFO] Train accuracy: 21.6312
[2023-06-21 16:55:23,932 INFO] Sentences processed: 22891
[2023-06-21 16:55:23,932 INFO] Average bsz: 242/ 348/ 7
.
.
.
[2023-06-21 19:01:25,673 INFO] Step 1910/ 2000; acc: 57.2; ppl: 36.1; xent: 3.6; lr: 0.02145; sents: 2147; bsz: 239/ 347/ 7; 1849/2683 tok/s; 8039 sec;
[2023-06-21 19:02:07,077 INFO] Step 1920/ 2000; acc: 57.6; ppl: 35.6; xent: 3.6; lr: 0.02139; sents: 2325; bsz: 243/ 348/ 7; 1881/2693 tok/s; 8080 sec;
[2023-06-21 19:02:48,975 INFO] Step 1930/ 2000; acc: 57.9; ppl: 35.1; xent: 3.6; lr: 0.02133; sents: 2345; bsz: 244/ 349/ 7; 1863/2666 tok/s; 8122 sec;
[2023-06-21 19:03:30,707 INFO] Step 1940/ 2000; acc: 57.5; ppl: 35.7; xent: 3.6; lr: 0.02128; sents: 2259; bsz: 242/ 347/ 7; 1855/2664 tok/s; 8164 sec;
[2023-06-21 19:04:12,552 INFO] Step 1950/ 2000; acc: 57.4; ppl: 36.1; xent: 3.6; lr: 0.02122; sents: 2257; bsz: 241/ 346/ 7; 1841/2648 tok/s; 8206 sec;
[2023-06-21 19:04:54,544 INFO] Step 1960/ 2000; acc: 56.9; ppl: 36.6; xent: 3.6; lr: 0.02117; sents: 2339; bsz: 244/ 349/ 7; 1859/2657 tok/s; 8248 sec;
[2023-06-21 19:05:36,495 INFO] Step 1970/ 2000; acc: 57.8; ppl: 35.1; xent: 3.6; lr: 0.02112; sents: 2364; bsz: 246/ 350/ 7; 1874/2672 tok/s; 8290 sec;
[2023-06-21 19:06:18,303 INFO] Step 1980/ 2000; acc: 57.4; ppl: 35.8; xent: 3.6; lr: 0.02106; sents: 2236; bsz: 241/ 348/ 7; 1842/2660 tok/s; 8331 sec;
[2023-06-21 19:07:00,243 INFO] Step 1990/ 2000; acc: 58.1; ppl: 34.6; xent: 3.5; lr: 0.02101; sents: 2503; bsz: 246/ 350/ 8; 1880/2671 tok/s; 8373 sec;
[2023-06-21 19:07:42,084 INFO] Step 2000/ 2000; acc: 57.6; ppl: 35.3; xent: 3.6; lr: 0.02096; sents: 2268; bsz: 242/ 349/ 7; 1852/2667 tok/s; 8415 sec;
[2023-06-21 19:07:42,084 INFO] Train perplexity: 53.5222
[2023-06-21 19:07:42,085 INFO] Train accuracy: 50.8492
[2023-06-21 19:07:42,085 INFO] Sentences processed: 463366
[2023-06-21 19:07:42,085 INFO] Average bsz: 243/ 349/ 7
[2023-06-21 19:07:42,194 INFO] Saving checkpoint nllb-200/2nllb-200-600M-onmt_2000_steps_step_2000.pt
Thanks for your time!