Multi-Way Neural Machine Translation Model
Following (Toward Multilingual Neural Machine Translation with Universal Encoder and Decoder, Thanh-Le Ha 2016) and (Google’s Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation, Johnson 2016), this tutorial shows how to train a multi-source and multi-target NMT model.
We have chosen here Spanish, Italian, French, Portuguese and Romanian: all 5 languages are part of the same “Romance” language family (we could have extended to Catalan) - these languages are very close and are sharing a lot of properties and even vocabulary. The goal is therefore to train a model translating from any of these 5 languages to any of the target languages (20 language pairs).
For the first experiment, we have extracted from Europarl, GlobalVoices and TedTalk corpus, 200,000 fully aligned sentences (each sentence has its translation in the 4 other languages) - the source corpus are available from here.
Considering proximity between the languages, we are using a common BPE between all languages (see Neural Machine Translation of Rare Words with Subword Units, Senrich 2016) - this allows to reduce the size of the vocabulary and handle translation of rare words.
We provide the corpus selection here containing the 2x20 training files (train-xxyy.{xx,yy}), 20 validation files (valid-xxyy.{xx,yy}), and 20 test files (test-xxyy.{xx,yy}). You can skip corpus preparation and directly get tokenized corpus from here.
Training BPE model
- First tokenization of the corpus to learn BPE (we only take training corpus) with a 32K vocabulary:
for f in ${DATA}/train*.?? ; do echo "--- tokenize $f for BPE" ; th tools/tokenize.lua < $f > $f.rawtok ; done
- Training of BPE model using script provided by Senrich here:
cat ${DATA}/train*.rawtok | python learn_bpe.py -s 32000 > ${DATA}/esfritptro.bpe32000
Tokenization with the BPE model
- We retokenize the complete corpus (train, valid, test) using the BPE model, and inserting the tokenization annotations:
for f in ${DATA}/*-????.?? ; do echo "--- tokenize $f" ; th tools/tokenize.lua -joiner_annotate -bpe_model ${DATA}/esfritptro.bpe32000 < $f > $f.tok ; done
the corpus looks like that:
- (Spanish) Pens■ amos que tal vez es una mez■ c■ la de factores ■.
- (French) Nous pensons que c ■’■ est peut-être une combin■ aison de facteurs ■.
Adding language token
The trick in the training of a multiway system is for a given sentence pair, to pass information to the NN about source and target language so that we can control the target language during translation. There are multiple ways to do that, here we add tokens in the source sentence marking the source and target sentence language. We could omit marking of the source language token and the model will automatically learn to identify the language (see below).
Practically, we are doing that by adding at the beginning of each sentence the following tokens: __opt_src_xx __opt_tgt_yy as following:
for src in es fr it pt ro ; do
for tgt in es fr it pt ro ; do
perl -i.bak -pe "s//__opt_src_${src} __opt_tgt_${tgt} /" *-${src}${tgt}.${src}.tok
done
done
Each sentence pair is now looking like:
- (Spanish) __opt_src_es __opt_tgt_fr Pens■ amos que tal vez es una mez■ c■ la de factores ■.
- (French) Nous pensons que c ■’■ est peut-être une combin■ aison de facteurs ■.
Training
- Final preparation step is to gather the training corpus together:
for src in es fr it pt ro ; do
for tgt in es fr it pt ro ; do
cat ${DATA}/train-${src}${tgt}.${src}.tok >> ${DATA}/train-multi.src.tok
cat ${DATA}/train-${src}${tgt}.${tgt}.tok >> ${DATA}/train-multi.tgt.tok
done
done
- And prepare a random 2000 files for the validation:
for src in es fr it pt ro ; do
for tgt in es fr it pt ro ; do
cat ${DATA}/valid-${src}${tgt}.${src}.tok >> ${DATA}/valid-multi.src.tok
cat ${DATA}/valid-${src}${tgt}.${tgt}.tok >> ${DATA}/valid-multi.tgt.tok
done
done
paste ${DATA}/valid-multi.src.tok ${DATA}/valid-multi.tgt.tok | shuf > ${DATA}/valid-multi.srctgt.tok
head -2000 ${DATA}/valid-multi.srctgt.tok | cut -f1 > ${DATA}/valid-multi2000.src.tok
head -2000 ${DATA}/valid-multi.srctgt.tok | cut -f2 > ${DATA}/valid-multi2000.tgt.tok
- Preprocess and Train
Here we simply train a model using brnn, 4 layers, 1000 for RNN size, bidirectional RNN, and 600 word embedding size:
th preprocess.lua -train_src ${DATA}/train-multi.src.tok -train_tgt ${DATA}/train-multi.tgt.tok \
-valid_src ${DATA}/valid-multi2000.src.tok -valid_tgt ${DATA}/valid-multi2000.tgt.tok\
-save_data ${DATA}/esfritptro-multi
th train.lua -layers 4 -rnn_size 1000 -brnn -word_vec_size 600 -data ${DATA}/esfritptro-multi-train.t7 \
-save_model ${DATA}/onmt_esfritptro-4-1000-600 -gpuid 1
Evaluating the model and comparing with single trainings
The following table gives the score of each single language pair and the second number compares with the score on the same language pair with a model trained only with the language pair data (200000 each).
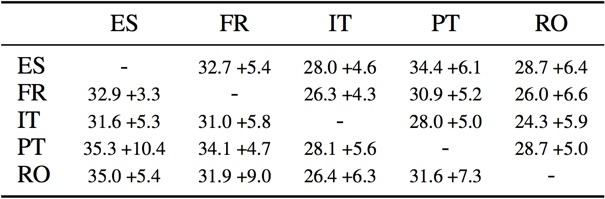
It is interesting to see that the multi-way model is systematically performing better than each of the individual system trained with the same data. Here since the corpus is fully aligned, the training does not provide any single new source or target sentence for a given language pair, so the systematic gain is coming from the “rules” learnt/consolidated from/with other languages.
 …
…