I ran with your script, but the Perplexity suddenly began to grow, and then I stopped and ran -continue, but it soon became big again.Do you know the reasons?
Is there an easy way to explore a pretrained model – for example getting the model configuration (number of layers for encoder, decoder, bidirectional or not) as well as weights of all the Linear layers for Encoder, Decoder and Attention? Thanks for the help in advance.
You may to take a look at the release_model.lua script.
Model configurations can be displayed with a simple:
print(checkpoint.options)
and the function releaseModel traverses parts of model (e.g. the encoder). With some print statements you should be able to get a sense on what is going on.
Hello newbie here, is this method doable in OpenNMT-TF in Windows 7 x64 in some way? I am working to train a 5-way NMT model with BPE. I already installed OpenNMT-tf and Tensorflow. Also, I was able to train an english to german model to test if opennmt is properly installed in my system and monitored it using Tensorboard. But I am currently stuck in tokenization when using OpenNMTTokenizer. I am experiencing error saying "--tokenizer: invalid choice: 'OpenNMTTokenizer’. I compiled OpenNMT-Tokenizer without boost, gtest and sentencepiece. For the meantime, I am using Moses’ tokenizer.perl. Thank you. 
Hello,
On Windows, you should manually install the Python wrapper of the tokenizer to use it within OpenNMT-tf. See:
However, it might simpler to install Boost and compile the Tokenizer with its clients (cli/tokenize and cli/detokenize). Then you can prepare the corpus before feeding them to OpenNMT-tf.
I’ve already compiled boost in my system with a toolset=gcc. However cmake could not find boost even i set the root and lib using this command:
cmake -DBOOST_ROOT=C:\boost-install\include\boost-1_66\boost -DBOOST_LIBRARYDIR=C:\boost-install\lib -G "MinGW Makefiles" -DCMAKE_BUILD_TYPE=Release
My ...\boost-1_66\boost contains a bunch of folders and .hpp files while ...\lib folder contains .a files.
Try with:
-DBOOST_INCLUDEDIR=C:\boost-install\include\boost-1_66 -DBOOST_LIBRARYDIR=C:\boost-install\lib
Hello, I managed to compile the tokenizer and detokenizer with boost using MinGW Destro. (MinGW with a lot of built-in libraries including boost). Now, I do have question related to this topic. I have 4 parallel corpora that are translated and aligned to each other (ie. train.{en,tgl,bik,ceb}) unlike the dataset used in this thread which has individual alignment/data for each pair (ie. train-{src}{tgt}.{es,fr,it,pt,ro}). How will I add language tokens to my data in this kind of case? Thank you.
Hello,
Good question! In the set-up proposed in this tutorial, you do need to specify the target language in the source sentence - that will be used to trigger the target language decoding. And you can do the same here, just sampling pair source/target and annotating them (you do need in any case to sample pairs for the training since you cannot train the 4 translation simultaneously.
However, another approach would be to inject the target language token as the forced-first token of the decoded sentence - this will make your encoder totally agnostic of the target language. If you want I can give you some entrypoint in the code for doing such experiment.
Best
Jean
Hi Jean, thank you for the reply.
I am using OpenNMT-tf. I made a script that duplicates 4 corpus (train.{eng,tgl,bik,ceb}) and name it with (train.engbik.eng, train.engceb.eng, train.engtgl.eng … train.tgleng.tgl). I tokenized the training data without additional parameters, trained a bpe model with a size of 32000 using the tokenized training data, tokenized the valid,test, and training data using parameters: case_feature, joiner_annotate, and bpe_model. Accordingly, I added language token “s//__opt_src_${src} __opt_tgt_${tgt} /” to test, valid and train. After preparing the data, I build 2 vocabularies, one for source (train-multi.src.tok) and another for the target (train-multi.tgt.tok) with a size of 50000, then I started to train the model using 2 layers, 512 RNN size, bidirectional RNN encoder, Attention RNN decoder and 600 word embedding size. On the 40,2000th step I tried to test it and translate a tokenized(.tok) test file (test-engtgl.eng) with a source language (english) and target (tagalog). However, the translation output is the same as the language of the test file but the language tokens were replaced as “<unk><unk>”. Is this completely normal?
Data, configuration files, and scripts that I used can be found here. Thank you.
Do you have detailed steps/scripts to do the “extraction of bitext” and “alignment”. Curious if you used any third party alignment tools ? I’m trying to replicate this for other language families.
Appreciate any help. Thanks !
I thinks it’s just about looking up each French sentence and checking if it is also present in the FRES, FRIT, FRPT, and FRRO corpus. If yes, then 5 parallel translations are found.
Thanks @guillaumekln That’s makes it way simpler.
I’m guessing if you did not have any parallel data then you can use something like Bitext Mining to get close to a parallel corpus.
Here’s my 2 cents on replicating this in OpenNMT-tf with results.
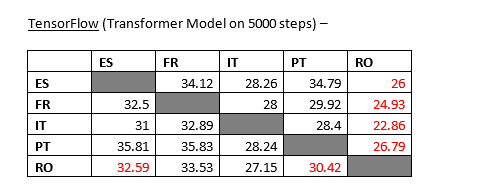
Training :
Activate the environment – (optional)
source activate tensorflow_p36
Building the vocabulary from tokenized training files –
onmt-build-vocab --size 50000 --save_vocab /home/ubuntu/multi-lingual_modeling/multi_tokenized/src_vocab_50k.txt /home/ubuntu/multi-lingual_modeling/multi_tokenized/train-multi-src.tok
onmt-build-vocab --size 50000 --save_vocab /home/ubuntu/multi-lingual_modeling/multi_tokenized/tgt_vocab_50k.txt /home/ubuntu/multi-lingual_modeling/multi_tokenized/train-multi-tgt.tok
Run the training (Transformer model) –
nohup onmt-main train_and_eval --model_type Transformer --config config_run_da_nfpa.yml --auto_config --num_gpus 1 2>&1 | tee multi_rnn_testrun1.log
Inference :
cp /home/ubuntu/multi-lingual_modeling/multi_tokenized/test-multi-*.tok /home/ubuntu/multi-lingual_modeling/multi_tokenized/inference_data/
cd /home/ubuntu/multi-lingual_modeling/multi_tokenized/inference_data
Split and rename all inference language files –
split -l 500 test-multi-src.tok
mv xaa test.src.es.fr.es
mv xab test.src.es.it.es
... (Rename all the remaining segments correspondingly)
split -l 500 test-multi-tgt.tok
mv xab test.tgt.es.fr.fr
mv xab test.tgt.es.it.it
... (Rename all the remaining segments correspondingly)
Run the below two commands for all the language pairs (20 times) –
onmt-main infer --config multi-lingual_modeling/config_run_da_nfpa.yml --features_file /home/ubuntu/multi-lingual_modeling/multi_tokenized/inference_data/test.src.es.it.es --predictions_file /home/ubuntu/multi-lingual_modeling/multi_tokenized/inference_data/infer_result.src.es.it.it --auto_config
perl OpenNMT-tf/third_party/multi-bleu.perl /home/ubuntu/multi-lingual_modeling/multi_tokenized/inference_data/infer_result.src.es.it.it < /home/ubuntu/multi-lingual_modeling/multi_tokenized/inference_data/test.tgt.es.it.it
Config File (config_run_da_nfpa.yml):
model_dir: /home/ubuntu/multi-lingual_modeling/opennmt-tf_run1
data:
train_features_file: /home/ubuntu/multi-lingual_modeling/multi_tokenized/train-multi-src.tok
train_labels_file: /home/ubuntu/multi-lingual_modeling/multi_tokenized/train-multi-tgt.tok
eval_features_file: /home/ubuntu/multi-lingual_modeling/multi_tokenized/valid-multi-src.tok
eval_labels_file: /home/ubuntu/multi-lingual_modeling/multi_tokenized/valid-multi-tgt.tok
source_words_vocabulary: /home/ubuntu/multi-lingual_modeling/multi_tokenized/src_vocab_50k.txt
target_words_vocabulary: /home/ubuntu/multi-lingual_modeling/multi_tokenized/tgt_vocab_50k.txt
params:
replace_unknown_target: true
train:
save_checkpoints_steps: 1000
keep_checkpoint_max: 3
save_summary_steps: 1000
train_steps: 5000
batch_size: 3072
eval:
eval_delay: 1800
external_evaluators: [BLEU,BLEU-detok]
Thanks !
4 Likes