I’m experimenting ZH->EN translation. My first model seems to put the uppercased letter on the second word of the sentence, rather than the first.
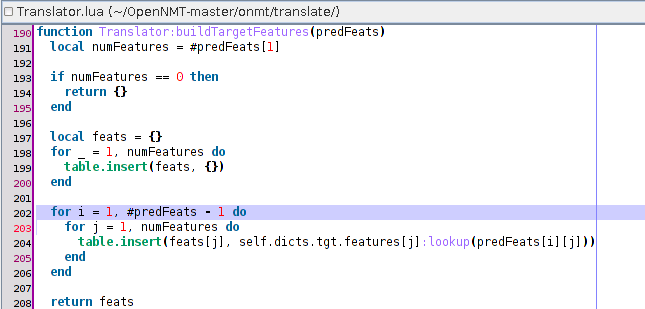
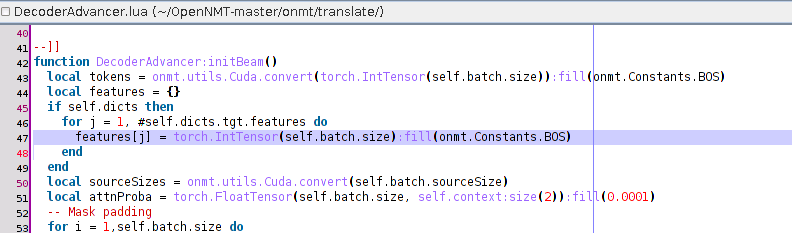
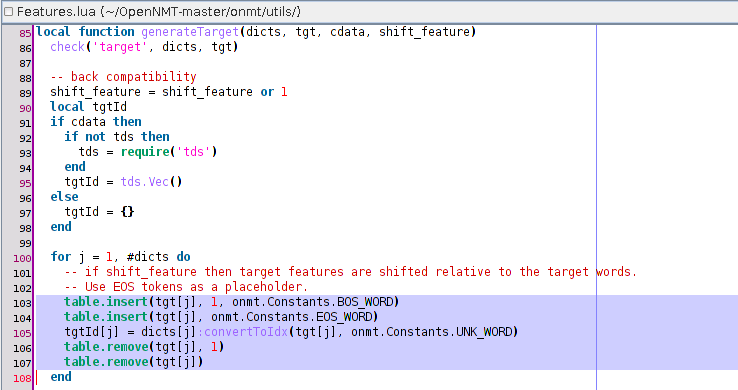
Of course I’m using the no-feature-shifting patch. But, it is installed on both the training and the translating code. I just double-checked it. I didn’t experiment this uppercase problem with other languages.
Is this a common known behaviour of this ZH->EN translation with ONMT ? Or, do I need to investigate more about the no-feature-shifting patch ?
It was a combination of two bugs in my own code, doing a bad job on ZH specific entries when dealing with upper/lowercased chars (of course, not well handled for the specific ZH language).