Hello,
I was wondering if there is some specifics about the XML tags in general ?
is there something done at tokenization step ? later ?
is it just tokenized as real text (separate < tags >) ?
Thanks
Hello,
I was wondering if there is some specifics about the XML tags in general ?
is there something done at tokenization step ? later ?
is it just tokenized as real text (separate < tags >) ?
Thanks
Hi, I would suggest to use tokenize.lua with -joiner_annotate option that will separate xml-characters [<>"] and will mark them to correctly generates valid XML tags.
Hello,
I trained a model by ~500,000 sentences (en-US -> es-ES), I compared the translated result between Microsoft Bing Translator and NMT server I deployed by the trained model.
For plain text, Bing Translator and NMT generate the similar translation, it looks good.
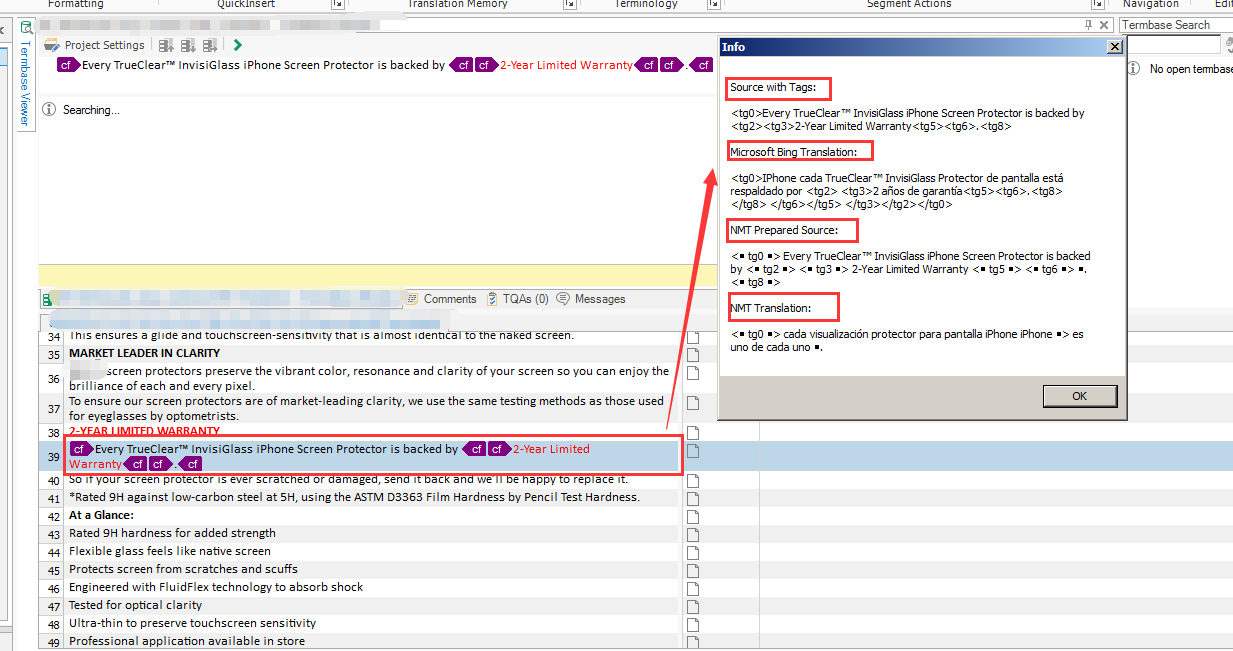
For strings with Tags (e.g: <tag0>, <tag1>…), Bing can keep the Tags as untranslated in translation in proper position what we expect. NMT can’t return the similar result. See the screenshot for detail.
Note: In the attached screenshot, cf tags shown in SDL Trados Studio, I extract such tags and convert them by unique tag number tag0, tag1… in order to get the source in plain text which can feed for NMT server. NMT Prepared Source: is the source in plain text I converted after Tokenization for feeding NMT server.
In order to keep the Tags same as Source when calling NMT Server, I attached a phrase table with below syntax and enable -phrase_table option, but it doesn’t work.
<tag0>|||<tag0>
tag0|||tag0
<tag1>|||<tag1>
tag1|||tag1
…
My question is: How to let NMT keep such tags as same as Source? If the Train procedure can resolve this or any other alternative solution?
Thanks.
did you detokenize the output ?
Thanks for your input. The detokenize shouldn’t affect the testing result. As you can see that, the NMT translation before detokenization just contain one tag where Source contains 6. The detokenization procedure won’t create additional tags/content, right?
@liluhao1982 Have you been able to solve the issue? I have tried to pass XML tags as is (without converting them to dummy tags like you) and the < symbol came out as <unk> and attribute names got translated. I actually ran two incremental ENDE trainings and the model with clean data was 54.11 BLEU and the model with tagged corpus was 23.83 BLEU. 
As I see it, XML handling has the same issues as the ones mentioned in this thread: Restoring of source formatting. A proper solution requires file filters in the client-side, anything else in the MT system itself would be just a rough workaround. The only practical use of internal XML handling I can think of is for passing information to the system, like Moses does for providing alternate or additional translations for words or phrases besides the ones found in the phrase tables.
It is not resolved my side.
It seems that initially I misread your issue and now I’m in the same position as you guys… I’m trying to handle tags in the Trados plugin and there is no way to achieve that. The custom tags (, etc) are always messing up with the translatable text returned from OpenNMT.
AFAIK Microsoft’s and Google’s systems can handle tags so it would be very useful if OpenNMT could do that too. Actually, I think it’s essential in order to integrate seamlessly with CAT tools.
Guys,
This issue is faced by many users, not only with Onmt but any MT system.
Some people tried to work around it, search for M4LOC.
Anyway, there are only 2 ways of trying to fix this:
Either you consider tags as regular tokens, and you trust the NN to learn properly how to plae them around some inline sub-segments, or you have to handle tags with rules BEFORE (ie prrepocessing) and AFTER (post processing).
Either way is not 100% accurate or perfect. you have to decide, and to do some homework.
But this cannot really be handled at the ONMT level.
Good luck.
I think none of these solution is applicable, please correct me if I’m wrong:
It doesn’t make much sense to train models with tags because (a) there can never be enough tags in the training corpus and (b) the placement of tags in new text sent for translation is arbitrary and highly unlikely to match anything in the trained model. Even if it worked, it would be a really noisy and messy solution.
This could be done only if there was alignment information returned from OpenNMT.
for point 1)
There is a new feature in ONMT tokenization to protect some specific placeholders.
If you replace tags with placeholders it is a workable solution.
But otherwise yes, always better to have a corpus that reflect the actual data (tags in data needed)
for point 2)
two choices: you sub segment at each tag position, not ideal I agree. Or you work with the attention info from ONMT.
Not the easiest.
Thanks for the pointers @vince62s. It seems the attention info is the cleanest method, I will give it a try once I have spare time.
I’m currently reviewing a document in memoQ translated by ONMT via our memoQ plugin. The inline tags are stripped out before each segment goes to the MT server but with memoQ’s F9 feature it’s pretty straightfoward to replace them during review.
Hi @anderleich,
I’ve done some work a few months back but got buried under a load of other work and left it aside. Getting started wasn’t that difficult, but fine-tuning and correcting misalignments is. I’ll keep you posted in this thread for any further progress.
Hello Community
I am very grateful for OpenNMT and all the features it offers. After having set up OpenNMT in combination with the REST Server and Trados PlugIn I am wondering, how to archive a decent tag placement. Is there any solution or direction you could point me to?  Unfortunately documents without tags are really rare in Trados documents.
Unfortunately documents without tags are really rare in Trados documents.
Best regards, Kai
Hi @Kai,
Currently you have to place tags manually in Trados. Hopefully I’ll be able to work on this feature next week and I’ll post in the forums when ready.