Hi,
I’m very interested in some OpenNMT features that tensorflow version has and I try to experiment with this version. I’m previously using OpenNMT-py and I tried to setup model in OpenNMT-tf as close to python version as possible.
I train my Chinese - Vietnamese model with 32k sentence pairs on train set, about 2k sentence pairs on dev and test set.
Sadly, when I’m using the default Rnnsmall autoconfig setting, the model get overfitted really quickly. I tried changing the params and use custom model with no success.
Whatever I tried, the model seems slowly increasing evaluation loss, sometimes immediately on the next evaluation after the first evaluation.
This is the best run I can get so far. I use BiRNN model with BLEU score of 30.87 on step 65k
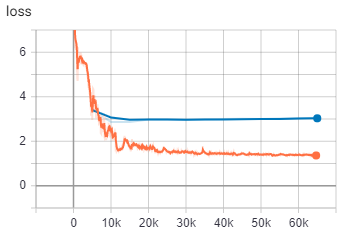
After step 15k, eval loss slowly increase so I stopped training eventually.
This is the config I use:
model_dir: model
data:
eval_features_file: cv.dev.cn
eval_labels_file: cv.dev.vn
source_words_vocabulary: src-vocab.txt
target_words_vocabulary: tgt-vocab.txt
train_features_file: cv.train.cn
train_labels_file: cv.train.vn
eval:
batch_size: 32
eval_delay: 0
exporters: last
infer:
batch_size: 32
bucket_width: 0
params:
average_loss_in_time: true
beam_width: 5
learning_rate: 2.0 # The scale constant.
clip_gradients: null
decay_step_duration: 8 # 1 decay step is 8 training steps.
decay_type: noam_decay_v2
decay_params:
model_dim: 512
warmup_steps: 2000 # (= 16000 training steps).
start_decay_steps: 0
label_smoothing: 0.1
length_penalty: 0
gradients_accum: 1
optimizer: AdamOptimizer
optimizer_params:
beta1: 0.9
beta2: 0.998
score:
batch_size: 64
train:
average_last_checkpoints: 8
batch_size: 4096
batch_type: tokens
keep_checkpoint_max: 8
maximum_features_length: 50
maximum_labels_length: 50
sample_buffer_size: -1
save_checkpoints_steps: 5000
save_summary_steps: 100
train_steps: 200000
This is my custom model
def model():
return onmt.models.SequenceToSequence(
source_inputter=onmt.inputters.WordEmbedder(
vocabulary_file_key="source_words_vocabulary",
embedding_size=512,
dtype=tf.float16
),
target_inputter=onmt.inputters.WordEmbedder(
vocabulary_file_key="target_words_vocabulary",
embedding_size=512,
dtype=tf.float16
),
encoder=onmt.encoders.BidirectionalRNNEncoder(
num_layers=2,
num_units=500,
reducer=onmt.layers.ConcatReducer(),
cell_class=tf.nn.rnn_cell.LSTMCell,
dropout=0.2,
residual_connections=False
),
decoder=onmt.decoders.AttentionalRNNDecoder(
num_layers=2,
num_units=500,
bridge=onmt.layers.CopyBridge(),
attention_mechanism_class=tf.contrib.seq2seq.LuongAttention,
cell_class=tf.contrib.rnn.LSTMCell,
dropout=0.2,
residual_connections=False))
Compared to OpenNMT-py, I got BLEU score of 37.83 with the following config
!CUDA_VISIBLE_DEVICES=0 python train.py -data data/test.atok.low -save_model demo_model -gpu_ranks 0 -optim adam -learning_rate 0.001 -encoder_type brnn \
-dropout 0.2 -word_vec_size 512 -train_steps 200000\
-batch_type tokens -normalization tokens \
-label_smoothing 0.1
I hope I can get some help, why the model on tensorflow get overfitted so easily and the translation quality is worse than the py version despite I tried setting them up as close to each other as possible?