Hi! I’ve tried to export a trained model in different formats (“ctranslate2”, “ctranslate2_int8”, “ctranslate2_int16”, “ctranslate2_float16”). Models were trained on the same training and validation data. Training data is an english-russian corpus of 3,6M rows. All the models were trained with exactly the same params (only changed export_format), with 36 000 steps. The results I’ve got is a bit confusing - larger (in terms of size in Mb) models are worse on test data in comparison to a base model (export_format = “ctranslate2_int8”). I’ve been thinking that the exporting a model in other format than “ctranslate2_int8” should perform better. The question is - Does a model exported in, say, “ctranslate2” should nesseserly perform better than a model exported in “ctranslate2_int8”. Do I have correct results? Here is the table with my results.
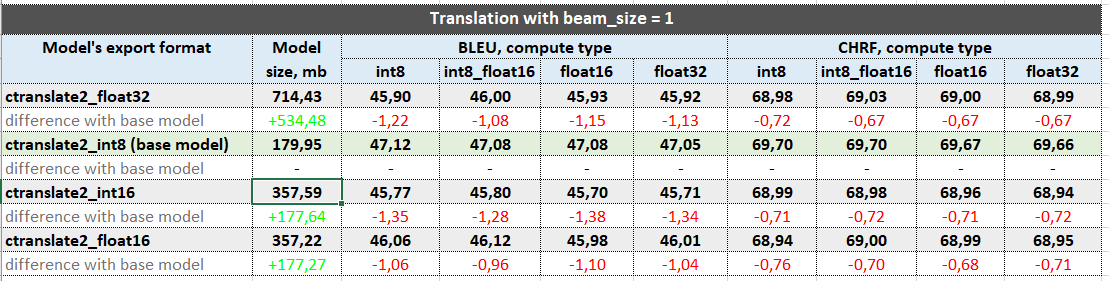
Thanks for help or any suggestions!