I’m going through an opennmt tutorial: Quickstart — OpenNMT-py documentation
I successfully generated the vocab lists. Then I ran
onmt_train -config toy_en_de.yaml
I saw ‘The first 10 tokens of the vocabs are:[’‘, ‘’, ‘’, ‘’, ‘the\t12670\r’, ‘,\t9710\r’, ‘.\t9647\r’, ‘of\t6634\r’, ‘and\t5787\r’, ‘to\t5610\r’]’ and I’m not sure if I should be worried.
For training, my config file looks like this:
save_data: run
# Prevent overwriting existing files in the folder
#overwrite: False
# Vocabulary files that were just created
src_vocab: toy-ende/vocab.src
tgt_vocab: toy-ende/vocab.tgt
# Corpus opts:
data:
corpus_1:
path_src: toy-ende/src-train.txt
path_tgt: toy-ende/tgt-train.txt
valid:
path_src: toy-ende/src-val.txt
path_tgt: toy-ende/tgt-val.txt
# Train on a single GPU
world_size: 1
gpu_ranks: [0]
# Where to save the checkpoints
save_model: run/model
save_checkpoint_steps: 500
train_steps: 1000
valid_steps: 500
I’m using windows.
After training for 1000 steps, I ran
onmt_translate -model run/model_step_1000.pt -src toy-ende/src-mytest.txt -output run/pred_1000.txt -gpu 0 -verbose
I’ve shortened the test file to 4 sentences, and the first sentence in the test file is the same as the first sentence in the training data. This is what I got:
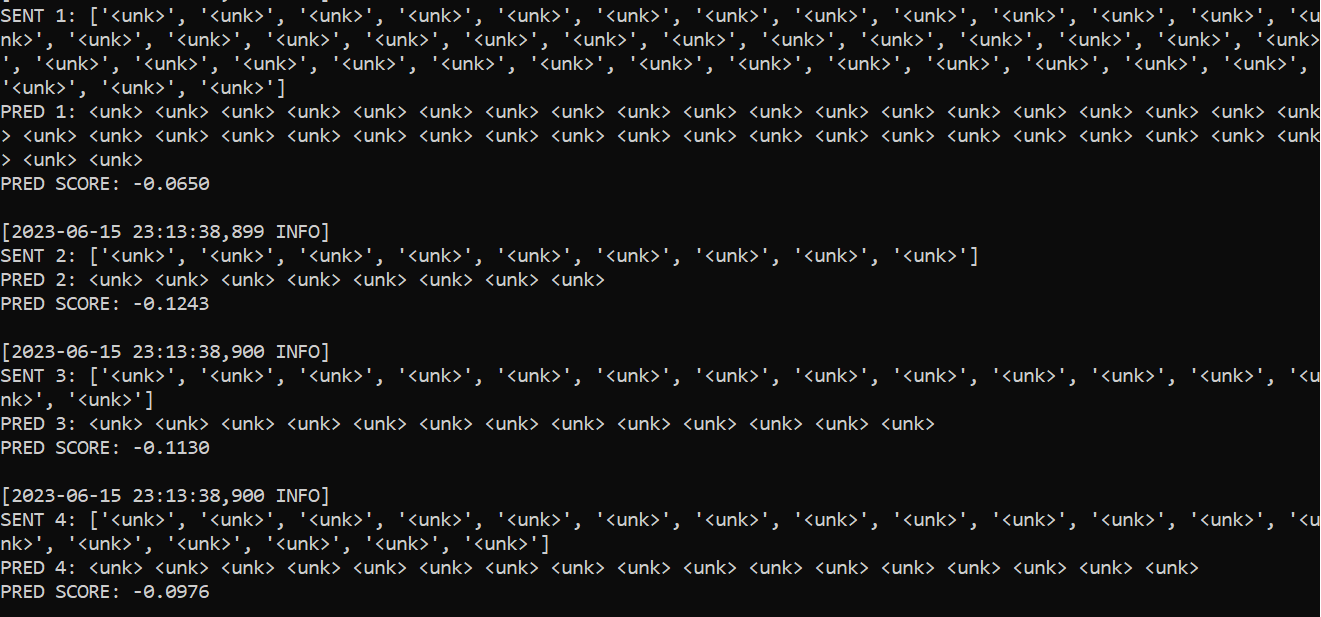
I expect at least the first sentence (from the source file) should be recognized correctly. What can I do?