Hi OpenNMT’ers,
We’ve had a lot of fun running the software against the sample data you provided using both GPU (via Ubuntu Desktop v16x) and CPU (on MacOS Sierra) processors (noting the VAST DIFFERENCE in performance) and are looking to now attempt a much larger corpus. Next week, we’ll try a full cross-linked GPU environment with a beefed up processor and plenty of RAM. Thanks for putting this out into open source!
So my question, the pre-process step requires a validation data set for source and target, and I was wondering where I could learn more about this data set, and how I might go about preparing it before we kick off a multi-million segment training. I’ve looked through the documentation, but can’t seem to find this. I know from SMT, we use similar data sets to “hold back” from training in order to validate the trained engines - but not sure in this case.
You will find some useful information about training, validation and test sets in this page:
tl;dr: the validation data is a set of sentences used to evaluate the convergence of the training. The model that achieves the lowest perplexity on this dataset is considered the best.
In practice, you usually start with a single corpus of parallel sentences and cut it in 3 parts:
~2000 validation sentences*
~2000 test sentences*
the rest as training sentences
* reasonable sizes are between 2000 and 5000 sentences I would say.
To complete Guillaume answer - in our trainings, we are taking validation set as close as possible to the training data.
It is different from the SMT world, where you have “tuning” set (aka devtest) which is supposed to be close to the “testing” set and is used to better tune the parameter after training to optimize the score for the test set.
In NMT world, the validation is there to measure that the training is not starting to overfit the training data but does not have any direct impact on the training.
Finally size-wise - we are generally taking only 2000-10000 sentences in the validation set - even if training is 10M.
In fact, it’s really not the good criterion (to stop the training). The good practise is to go till the convergence, whatever the perplexity on the validation set.
I have an example, just here, where the validation is decreasing, then increasing, then again decreasing :
The overfitting is not a question of time in the convergence process, but rather a problem of size of the network, considering all results when all full convergences are obtained. You get overfitting when your network has too much freedom degrees…
The validation set must be used to decide of the size of a network, not to decide when stopping a training.
I did not mention when to stop the training based on the validation score. I simply said that after training N epochs, you pick the model that has achieved the lowest validation perplexity.
This was a practical advise in the scope of OpenNMT.
I think that the validation perplexity is strictly a no interest for a single training. Its only interest is to compare several trainings, with several network structures.
Last point to add to the thread (I think we should aggregate and turn it into some kind of documentation), the learning rate changes based on the validation ppl - when it starts increasing (or each epoch after -start_decay_at) then learning rate decays, which explains the up-and-down in the ppl that Etienne is showing. (but strangely @Etienne38: the learning rate in your log still display 1 about epoch 15 which is odd)
The fact that the validation value is going up and down has nothing to do with the learning rate. These fluctuations are of no real interest in the analyse of a single learning process.
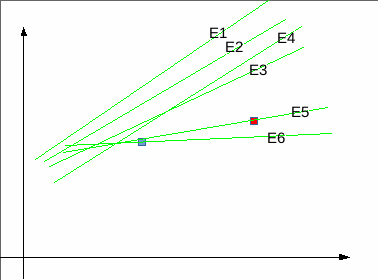
Here is a extremely simplified sample. Suppose your are trying to learn a linear model over a single learning blue point, having a single red validation point. It’s the usual case of deep neural networks : you have too much freedom degrees for the number of samples you have. You have an infinite number of perfect solutions, overfitting your single point, doing whatever they want on the validation red point.
So, now, have a look at the training curve, for epoch E1 to E6. On all epochs, the learning error is decreasing, while the model is much more efficient on the learning blue point. From E1 to E3, the validation value is decreasing on the red point. On E4, it’s increasing. On E5 it’s even an exact validation match. The final E6 is again a decreasing.
This validation evaluation, during the training, has no interest, because you don’t know what will be the next model in the next epoch, and you don’t know where are the other red points to be sure that your validation set is really pertinent for the whole curve you are searching.
The only interesting consideration is that final errors done on the validation points, when convergence are reached on many tested network structures, is certainly a good evaluation of the way your model have a size for a good optimization of the bias-variance tradoff.
I am not saying there is something to do: my point is on what is implemented on OpenNMT: when PPL goes up, learning rate by design decays (but as you say you can decide to cancel decay which is then a question of good practice)
I’ve a question concerning the validation set size in your experiment described in “Domain Control for Neural Machine Translation.”
You mention four different training configurations. The first includes six in-domain NMT
models. Each model is trained using its corresponding domain data set. The validation set is 2k lines per domain.
Then you describe Join network, Token network and Feature network configurations where all the training data is concatenated. Did you also concatenate all validation sets resulting in 12k tuning data? Or are the test sets you mention, “only” the sets to test a model after it’s trained? If yes, what then is the validation set size of the data used during training the joint models?
For the Join network, Token network and Feature network configurations, all the in-domain training data are concatenated but we didn’t concatenate all the corresponding validation sets; we randomly selected a part of each set (250 lines for each domain = 1500 lines for the validation set).
The different configurations are evaluated on predefined in-domain test sets.
One last question concerning validation data. As far as I understand, validation data is only used to avoid overfitting?
What if i trained various models on the same training data but used different validation sets from the same domain and then used the ensemble of those models for decoding? Let’s say I build five models based on WMT. They all have the same training data, but for validation I use News2016, News2015, …2014, …2013, …2012 respectively. If I understand correctly, this wouldn’t make much difference because the training data remains the same?