is ‘–gpu-ranks’ option for using gpu for OpenNMT-py? (so if i want to use 1 gpu for training, should i set it --gpu-ranks 1? I am asking this because when I do CUDA_VISIBLE_DEVICES=“0”, it doesn’t use GPU)
does OpenNMT-py automatically do early-stopping? if not, should i set --early_stopping as 0 or whatever? also how do I set --early_stopping_criteria? There’s no information about this option.
You need to set both -world_size which is a count, and -gpu_ranks which is an index.
Here is an example command for training on one GPU: CUDA_VISIBLE_DEVICES=0 python3 train.py -data data/demo -save_model demo-model -world_size 1 -gpu_ranks 0
As for early Early Stopping, returning to its code and it is pull request, one can learn much.
Basically, the arguments, can be something like this: -early_stopping 4 -early_stopping_criteria accuracy ppl
If you are training for 100,000 steps (-train_steps default) and validating every 10,000 steps (-valid_steps default), then you have 10 validation steps. So you can select the -early_stopping to happen if there is no improve for 4 validations. The default is 0 which means “do not use it”.
Looking into the code, by default, -early_stopping_criteria is set to use both “Accuracy” and “PPL” (DEFAULT_SCORERS). So unless you want to change this, you do not need to set the argument, and if you set them as the example above, it is still okay. On the other hand, to use -early_stopping_criteria, you must set -early_stopping to a number greater than 0.
hi yasmin moslem, thank you so much for the quick reply!
If I want to use 3 gpus, should the command be like ‘CUDA_VISIBLE_DEVICES=“0,1,2” python3 train.py -data data/demo -save_model demo-model -world_size 3 -gpu_ranks 0,1,2’ ?
I am not sure about how to set -gpu_ranks in this case. Thanks!
Hi yasmin,
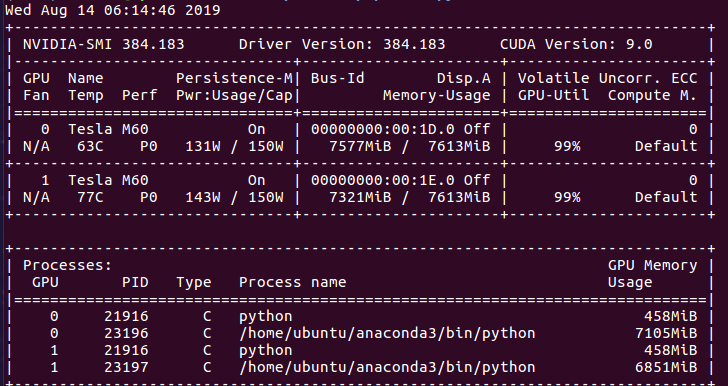
One thing I could not understand.Suppose training process on 1 gpu takes around 8gb of gpu memory.And if I have 2 gpus each of size 7.5gb and I use world_size 2 and gpu_ranks 0 1. Then in this case shouldn’t the memory load be distributed over two gpus? That is around 7.5 gb on 1 gpu and remaining on 2nd gpu? Kindly suggest @ymoslem@vince62s@guillaumekln
@vince62s For me it is getting out of memory in both the case even if i use 2 gpu or 1. What should be the solution for me other than reducing batch size??
world_size = number of GPU (potentially on several nodes)
gpu_ranks = 0 1 designate the ranking of GPU of this node in the total ecosystem
in your case 1 node 2 GPU, use world_size 2, gpu_ranks 0 1
no choice, reduce the batch_size, or use a smaller network.
I am using world_size 2, gpu_ranks 0 1 only, you can see the above image from nvidia-smi.
Reducing batch size might affect my translation quality, so I was looking if thing could be done