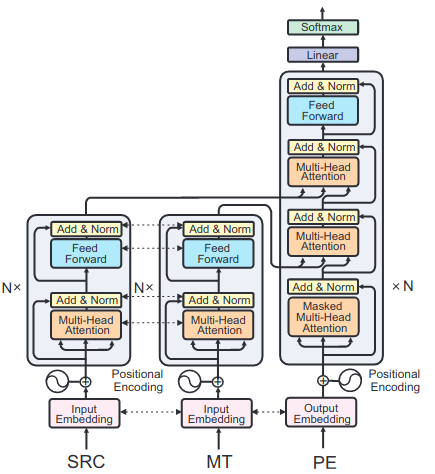
When running inference, I am getting the following warning. I think this is related to tying the in2 and target embeddings. Is it harmful in any way?
WARNING:tensorflow:Inconsistent references when loading the checkpoint into this object graph. Either the Trackable object references in the Python program have changed in an incompatible way, or the checkpoint was generated in an incompatible program.
Two checkpoint references resolved to different objects (<tf.Variable 'dual_source_transformer_1/embedding:0' shape=(29302, 512) dtype=float32, numpy=
array([[ 0.00684818, 0.00364716, -0.01369294, ..., -0.0140352 ,
0.00345916, 0.00921109],
[-0.0389531 , -0.01416353, -0.02679272, ..., -0.01685427,
-0.02278348, -0.10971494],
[ 0.01376689, 0.01407808, 0.01040961, ..., -0.00610482,
0.00784335, -0.0126047 ],
...,
[ 0.01562562, -0.04909495, 0.02456149, ..., -0.01563725,
-0.00244068, -0.01827662],
[-0.04773009, -0.06443136, -0.05259109, ..., -0.02209991,
-0.00625305, -0.09353954],
[-0.00408842, 0.00796524, -0.00671746, ..., 0.00455097,
-0.00271277, -0.00612399]], dtype=float32)> and <tf.Variable 'dual_source_transformer_1/embedding:0' shape=(29302, 512) dtype=float32, numpy=
array([[ 0.00684818, 0.00364716, -0.01369294, ..., -0.0140352 ,
0.00345916, 0.00921109],
[-0.0389531 , -0.01416353, -0.02679272, ..., -0.01685427,
-0.02278348, -0.10971494],
[ 0.01376689, 0.01407808, 0.01040961, ..., -0.00610482,
0.00784335, -0.0126047 ],
...,
[ 0.01562562, -0.04909495, 0.02456149, ..., -0.01563725,
-0.00244068, -0.01827662],
[-0.04773009, -0.06443136, -0.05259109, ..., -0.02209991,
-0.00625305, -0.09353954],
[-0.00408842, 0.00796524, -0.00671746, ..., 0.00455097,
-0.00271277, -0.00612399]], dtype=float32)>).