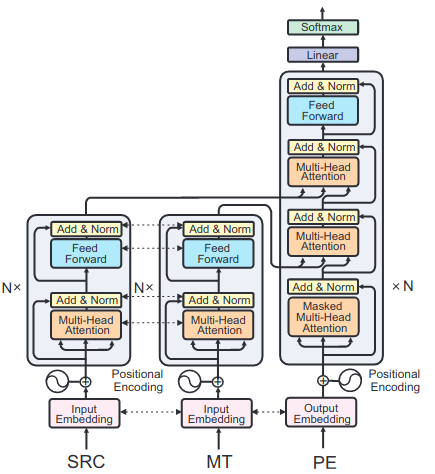
Hi
We are interested in using the dual source transformer for our research. Going through the code, it seems that for the different input sides, a different embedding is created. That is what I expect. However, I would like to have one of these input embeddings shared with the target embedding. So basically having one source text as input (in1), one target text as input (in2), and another target text as output (out1), so that the "target"s (in2, out1) have shared embedding space. Is that possible?
It seems that share_embeddings only takes one value so I don’t think it is possible to force different behaviour for the different inputs.
In addition, I do not quite understand the (very brief) explanation of EmbeddingsSharingLevel. Does SOURCE_TARGET_INPUT mean that the source and target words are in the same embedding space? (One vocabulary to rule them all.) If so, I am not sure what TARGET means (“share target word embeddings and softmax weights”): share with what? What is meant with sharing here? If you could elaborate on the meaning of these levels, I’d be grateful.
Hereby I would also like to request a port of the multi-source transformer to the PyTorch version.