I am using the approach given in “Simple-Opennmt-py-Rest server”
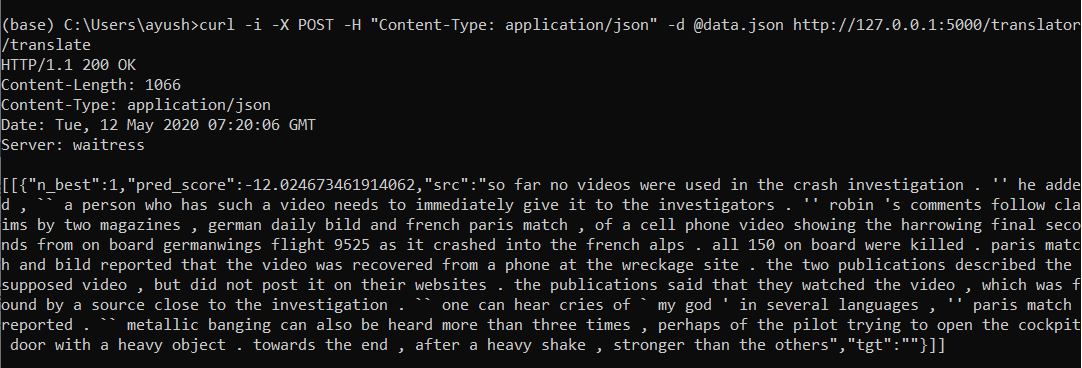
As shown in image when I run the given command:-curl -i -X POST -H “Content-Type: application/json” -d @data.json http://127.0.0.1:5000/translator/translate
I get the following output:-[[{“n_best”:1,“pred_score”:-12.024673461914062,“src”:“so far no videos were used in the crash investigation . ‘’ he added , a person who has such a video needs to immediately give it to the investigators . '' robin 's comments follow claims by two magazines , german daily bild and french paris match , of a cell phone video showing the harrowing final seconds from on board germanwings flight 9525 as it crashed into the french alps . all 150 on board were killed . paris match and bild reported that the video was recovered from a phone at the wreckage site . the two publications described the supposed video , but did not post it on their websites . the publications said that they watched the video , which was found by a source close to the investigation . one can hear cries of ` my god ’ in several languages , ‘’ paris match reported . `` metallic banging can also be heard more than three times , perhaps of the pilot trying to open the cockpit door with a heavy object . towards the end , after a heavy shake , stronger than the others”,“tgt”:""}]]
As shown in above output the tgt or the summarized document is empty.The src is the input text given by me.
How can I get the summarized file in the tgt?What I an doing wrong?
What Tokenizer should I use in conf.json in available_models folder?
Please help ASAP.