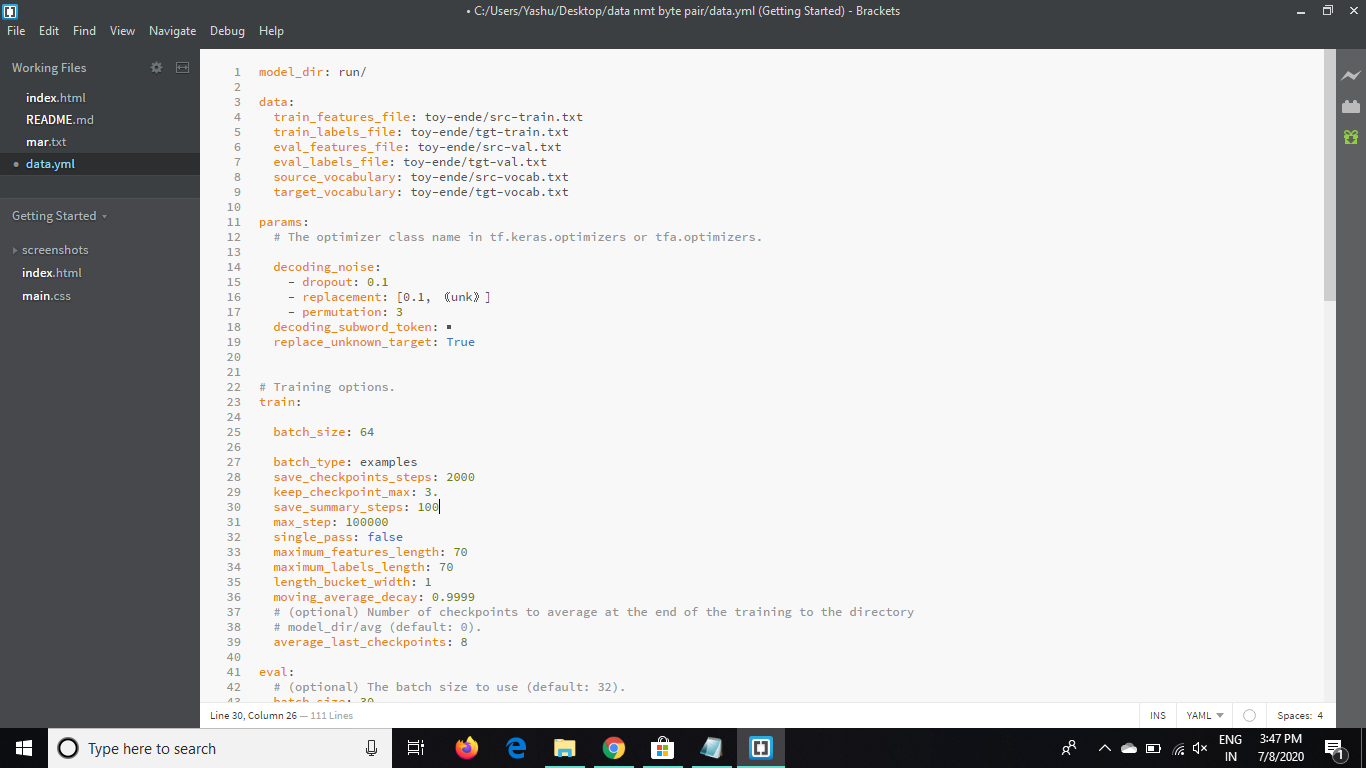
I am using this command
onmt-main --model_type Transformer --auto_config --config /content/data.yml train --num_gpus 1
Training takes lot of time in start as from from last 2 hours not a single step has been processed . I am using runtype gpu on colab .
Am i doing something wrong . I have also attached the config i am using and the data after applying the bpe.
Please have a look
Why did you change the batch size and batch type? --auto_config assumes a “tokens” batch type so the default gradient accumulation is incorrect.
You should either remove the parameters batch_size and batch_type, or disable gradient accumulation:
train:
effective_batch_size: null
Ok thanks i will check with new setting . Please have a look any changes requires please let me know as i am learning this framework .Please have a look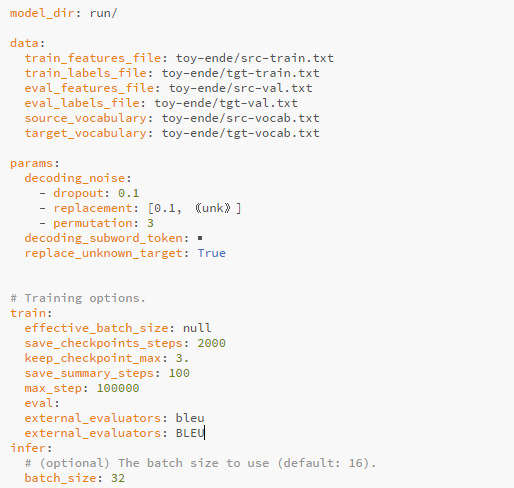
If you are getting started, you should just configure model_dir and data, as presented in the Quickstart.
thanks one last question .how to do the inference for one single query instead of file .As i am not geting the command for inference for single query
For File translation
!onmt-main --config /content/data.yml --auto_config infer --features_file toy-ende/src-test.txt --predictions_file toy-ende/pred.txt
Please tell me how to do the inference for single query or sentence . using command
Please tell me how to do the inference for single query or sentence . using command
This is not possible with onmt-main.
If you want to serve the model, we already mentionned it here: