Rishi
August 3, 2020, 8:52pm
1
I used the SentencePiece model as a tokenizer. When I encoded src text file using SPM encoder, everything is fine.
Command:
While using translation command on the model, few lines translated as empty, and it’s not that those sentences are small 1 word, phrases. These sentences were complete sentences.
Command:
I am trying English-French Machine Translation on the Europarl dataset.
Can you show an example input (tolenized) that gives you an empty translation?
Rishi
August 3, 2020, 10:10pm
3
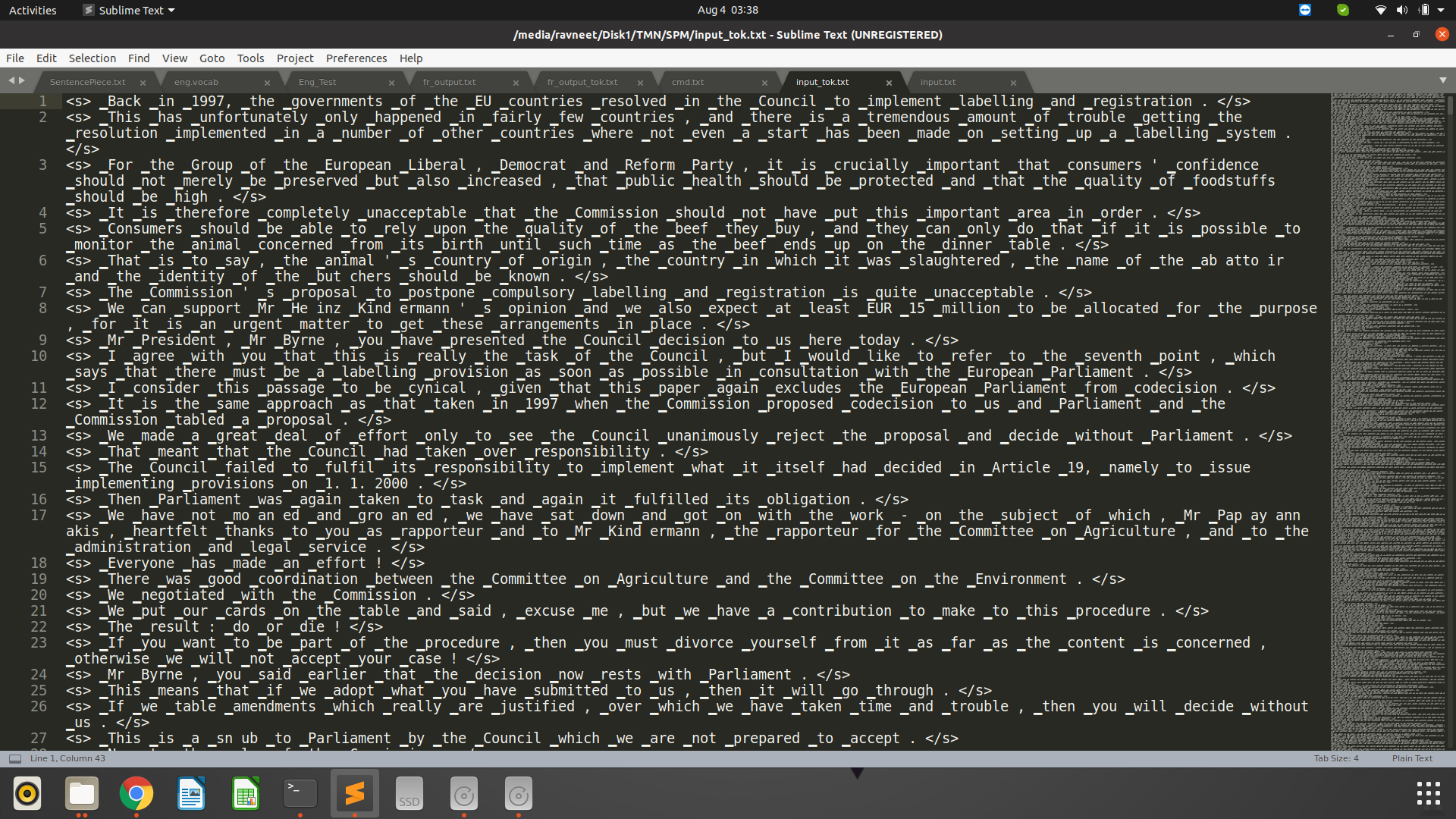
@BramVanroy Here is the input file after tokenization.
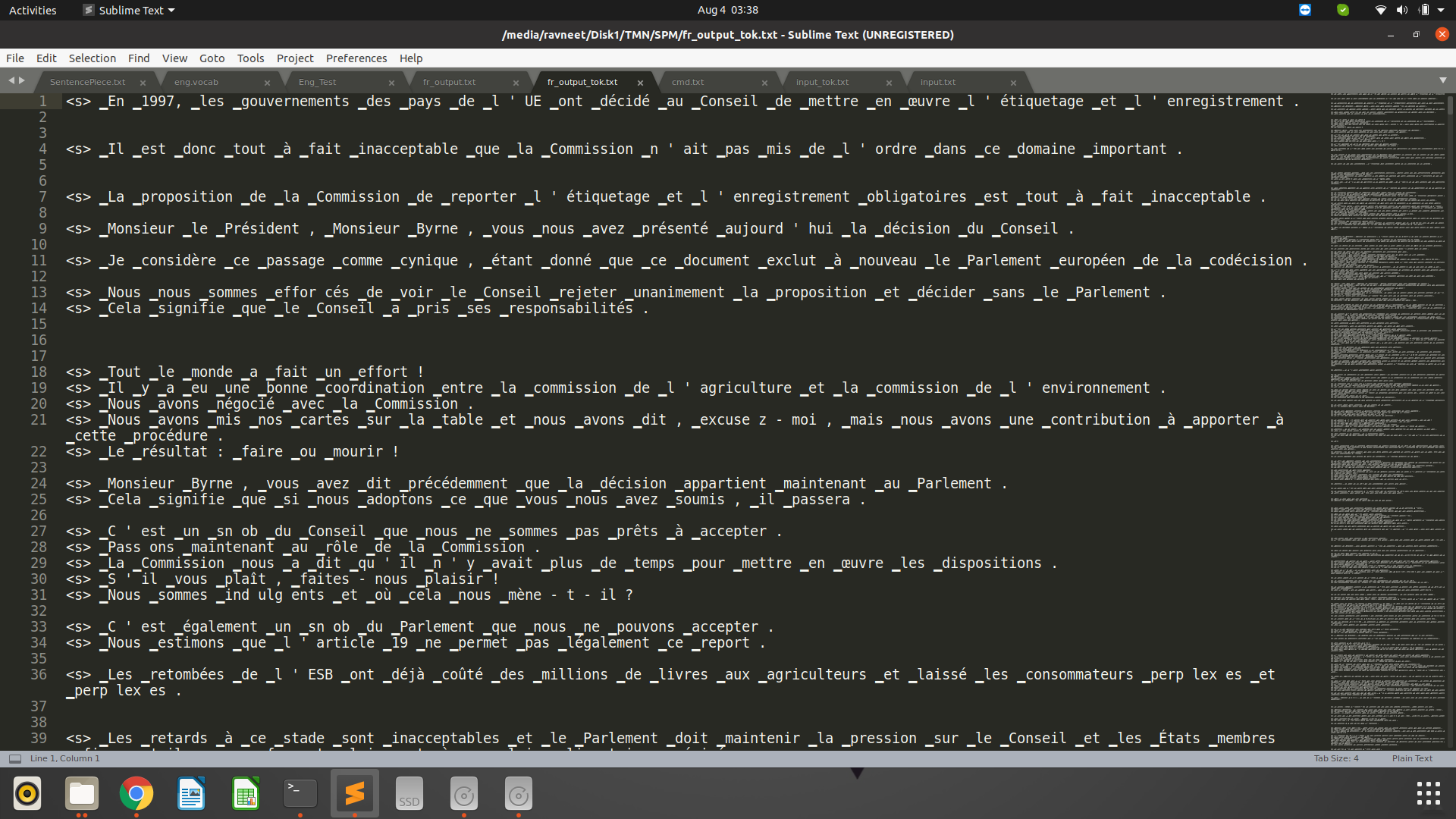
And this is output, after translation.
@guillaumekln please help.
Rishi:
–extra_options=bos:eos
I suggest to not use these options when training with OpenNMT-py. The framework already injects these tokens in the data.
anderleich
September 8, 2020, 8:25am
5
Hi,
ardate
February 2, 2022, 11:17am
6
Hi everyone,
Thanks,
Hi,
When no length penalty or normalization are applied, the empty output can have a better score than any other predictions.
There are multiple solutions in OpenNMT-py:
Set a minimum decoding length: -min_length 1
Set a length penalty: -length_penalty wu -alpha 0.1
ardate
February 2, 2022, 4:39pm
8
Thanks for your reply Guillaume!
Just as extra information for anyone who might check this thread in the future I will also share my experience with both configurations:
The issue was solved with -min_length 1 and the BLEU scores were as expected.
I still had some blank lines (no predictions) with the length penalty (wu, alpha=0.1).
Regarding the length penalty, I probably used a bad value for -alpha. You can also try other values like 0.6 (the default in Tensor2Tensor).
But -min_length is probably the easiest solution here.
1 Like