Hi,
I have a question regarding to sentence length when translating with a Transformer model.
I’ve successfully trained a model with about 4M of parallel sentences which lengths are distributed between 0 and 60 tokens. Most of them are < 20. When I apply the trained model to a test set with similar lengths, the model performs quite good. By the way, both source and target languages have nearly similar sentence lengths.
However, when I apply the model to another text which sentences lengths go from 0 to 300 tokens (most of them between 0-125 tokens) the translation quality degrades so much. In one hand, it degrades due to the fact the this text is out of domain, and on the other hand I have noticed that the model tends to drop the final parts of the longest sentences. Sentences which lengths are above 70 or 80 are always cut off into sentences of 60 tokens. I upload the length histograms
to ilustrate this behaviour.
Source length histogram:
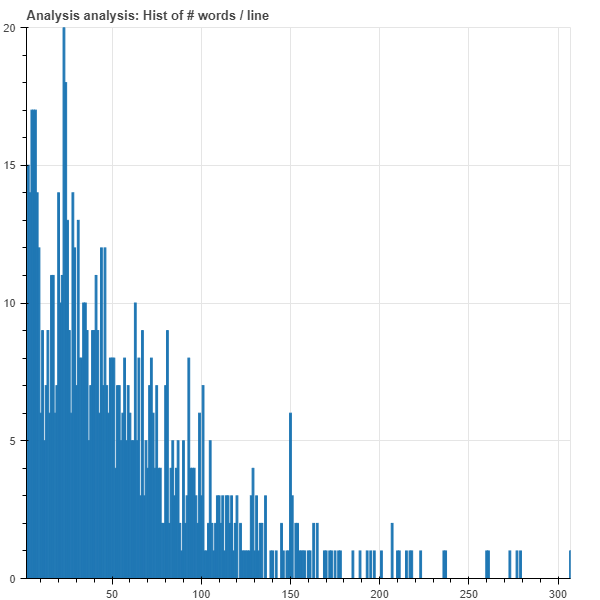
Translated length histogram:
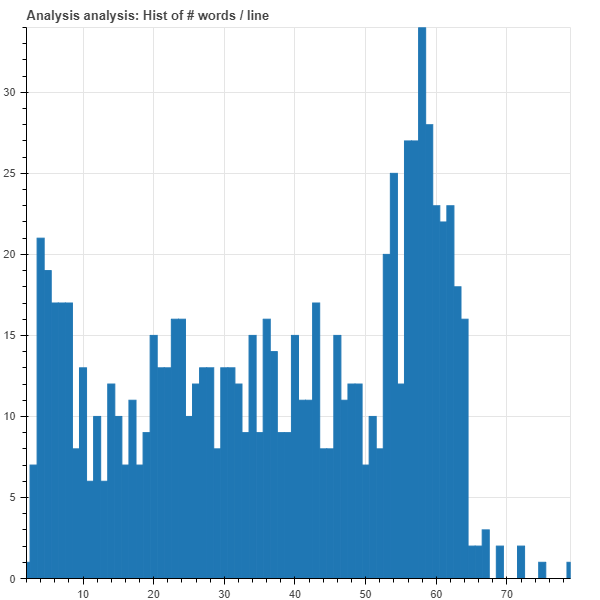
I have some doubts related to this behaviour:
- First of all, is this the expected behaviour?
- If this is expected, the why is it happening? Diving into the problem, I found these things:
- I know beam search can reach the end of the sentence before it really happens, so I have used a length penaly of 0.6. No coverage penaly was used since I read it is no common when using Transformer. I am planning to increase the length penaly to 0.9-1.0 since it seems to improve the BLEU.
- I am using a batch size of 50 in inference. Is batch size related to this? By the way, is there any relationship between batch size and translation quality during inference or is it just related to memory consumption?
- Are there any requirements in the model configuration? I am using the defaults max_decoding_length=0 and min_decoding_length=250 and keep max_length_features_training and max_length_label_training to null when training.
- Is it due to my training data length distribution?
- Is this a common problem when using the Transformer? Does it happen due to the attention mechanism?
- What are some possible solutions to this problem?
- I cannot collect parallel data of this length, but I got monolingual data in the target language with similar length distribution. Can it be used in some way?
- I read in this forum that a solution could be to split the sentences into smaller parts although it degrades a bit the translation quality. Will be better to use a sliding window instead?
Thank you so much for your time, any tips will be really appreciated.
Regards,
Ana