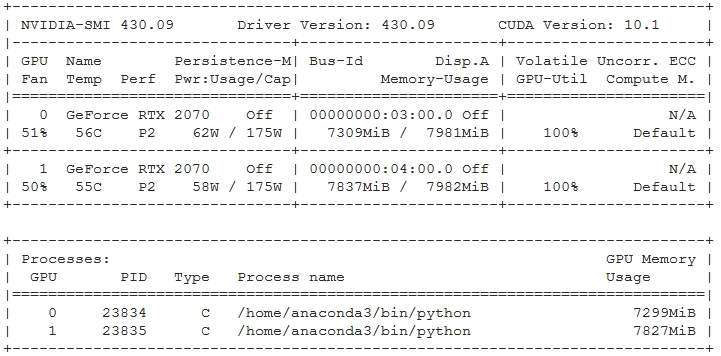
but this training will get stuck at 257100 steps.
and then I use ctrl+c quit the training, and continue with -train_from ; then it will get stuck at 507100 steps.
when it’s stucked. nvidia-smi display like (GPU-Util all 100%):
I’ve dealt with this as well, but have not found a solution. Some info in case someone has time:
Using the same bitext data, it does not happen with versions of OpenNMT/Pytorch from February. On the current stable pytorch + master onmt this occurs.
It is not caused by a particular training example. After the first time getting stuck, I rearranged my train.xx.pt files and the training got stuck on the same step but using different data.
It seems to be deadlocked in gettime() (see stack trace below). The closest issue I can find is https://github.com/NVIDIA/nccl/issues/48 which blames it in the NCCL version. If it’s the same issue, it should be fixed in NCCL 2.1. I have a lower version but work on a cluster, so I cannot test if that works.
(gdb) bt
#0 0x00007ffc215056c2 in clock_gettime ()
#1 0x00007f57f3bbe96d in clock_gettime () from /lib64/libc.so.6
#2 0x00007f57d6033b1e in ?? () from /usr/lib64/nvidia/libcuda.so.1
#3 0x00007f57d60c8b93 in ?? () from /usr/lib64/nvidia/libcuda.so.1
#4 0x00007f57d60e7c09 in ?? () from /usr/lib64/nvidia/libcuda.so.1
#5 0x00007f57d60113a6 in ?? () from /usr/lib64/nvidia/libcuda.so.1
#6 0x00007f57d5f2a48e in ?? () from /usr/lib64/nvidia/libcuda.so.1
#7 0x00007f57d5f2cfe6 in ?? () from /usr/lib64/nvidia/libcuda.so.1
#8 0x00007f57d6079e02 in cuMemcpyDtoHAsync_v2 () from /usr/lib64/nvidia/libcuda.so.1
#9 0x00007f57dae8b4bf in ?? () from /path/to/conda/lib/python3.6/site-packages/torch/lib/libcudart-f7fdd8d7.so.9.0
#10 0x00007f57dae68573 in ?? () from /path/to/conda/lib/python3.6/site-packages/torch/lib/libcudart-f7fdd8d7.so.9.0
#11 0x00007f57daea1d86 in cudaMemcpyAsync () from /path/to/conda/lib/python3.6/site-packages/torch/lib/libcudart-f7fdd8d7.so.9.0
#12 0x00007f573d3b9233 in at::native::_local_scalar_dense_cuda(at::Tensor const&)::{lambda()#1}::operator()() const ()
from /path/to/conda/lib/python3.6/site-packages/torch/lib/libcaffe2_gpu.so
#13 0x00007f573d3bbbb7 in at::native::_local_scalar_dense_cuda(at::Tensor const&) () from /path/to/conda/lib/python3.6/site-packages/torch/lib/libcaffe2_gpu.so
#14 0x00007f573c3f0902 in at::CUDAType::_local_scalar_dense(at::Tensor const&) const () from /path/to/conda/lib/python3.6/site-packages/torch/lib/libcaffe2_gpu.so
#15 0x00007f57db6d8685 in torch::autograd::VariableType::_local_scalar_dense(at::Tensor const&) const ()
from /path/to/conda/lib/python3.6/site-packages/torch/lib/libtorch.so.1
#16 0x00007f57ddaef92a in at::native::item(at::Tensor const&) () from /path/to/conda/lib/python3.6/site-packages/torch/lib/libcaffe2.so
#17 0x00007f57dddf9e15 in at::TypeDefault::item(at::Tensor const&) const () from /path/to/conda/lib/python3.6/site-packages/torch/lib/libcaffe2.so
#18 0x00007f57db8d2418 in torch::autograd::VariableType::item(at::Tensor const&) const () from /path/to/conda/lib/python3.6/site-packages/torch/lib/libtorch.so.1
#19 0x00007f57e7c701f6 in torch::autograd::dispatch_to_CDouble(at::Tensor const&) () from /path/to/conda/lib/python3.6/site-packages/torch/lib/libtorch_python.so
#20 0x00007f57e7c70646 in torch::autograd::THPVariable_item(_object*, _object*) () from /path/to/conda/lib/python3.6/site-packages/torch/lib/libtorch_python.so
#21 0x000055f1b7bd279a in _PyCFunction_FastCallDict ()
#22 0x000055f1b7c61acc in call_function ()
#23 0x000055f1b7c844ba in _PyEval_EvalFrameDefault ()
...
#58 0x000055f1b7c85279 in _PyEval_EvalFrameDefault ()
#59 0x000055f1b7c5ca39 in PyEval_EvalCodeEx ()
For what it’s worth, I found that the latest version of pytorch fixes this. When installing pytorch via pip or conda, a lot of the cuda stuff comes precompiled. It must be a big in the earlier versions of cuda code that gets used by OpenNMT-py’s newer producer/consumer strategy.