- Create project directory:
$ mkdir wmt15-ende
$ cd wmt15-ende
$ wget "https://s3.amazonaws.com/opennmt-trainingdata/wmt15-de-en.tgz"
Résolution de s3.amazonaws.com (s3.amazonaws.com)… 54.231.121.18
Connexion à s3.amazonaws.com (s3.amazonaws.com)|54.231.121.18|:443… connecté.
requête HTTP transmise, en attente de la réponse… 200 OK
Taille : 473813197 (452M) [application/x-compressed]
Enregistre : «wmt15-de-en.tgz»
100%[==============================================================>] 473 813 197 3,59MB/s ds 2m 2s
2016-12-23 17:04:31 (3,71 MB/s) - «wmt15-de-en.tgz» enregistré [473813197/473813197]
$ tar xzf wmt15-de-en.tgz
$ git clone https://github.com/OpenNMT/OpenNMT.git
Clonage dans 'OpenNMT'...
remote: Counting objects: 6117, done.
remote: Compressing objects: 100% (47/47), done.
remote: Total 6117 (delta 19), reused 0 (delta 0), pack-reused 6070
Réception d'objets: 100% (6117/6117), 14.21 MiB | 664.00 KiB/s, fait.
Résolution des deltas: 100% (4101/4101), fait.
$ cd OpenNMT
$ luarocks install tds
$ for f in ../wmt15-de-en/*.?? ; do th tools/tokenize.lua < $f > $f.tok ; done
Tokenization completed in 382.013 seconds - 2399123 sentences
Tokenization completed in 348.492 seconds - 2399123 sentences
Tokenization completed in 385.031 seconds - 1920209 sentences
Tokenization completed in 304.141 seconds - 1920209 sentences
Tokenization completed in 40.293 seconds - 216190 sentences
Tokenization completed in 32.668 seconds - 216190 sentences
Tokenization completed in 0.434 seconds - 3000 sentences
Tokenization completed in 0.417 seconds - 3000 sentences
- Concatenate commoncrawl, europarl and news-commentary:
$ for l in en de ; do cat ../wmt15-de-en/commoncrawl.de-en.$l.tok ../wmt15-de-en/europarl-v7.de-en.$l.tok ../wmt15-de-en/news-commentary-v10.de-en.$l.tok > ../wmt15-de-en/wmt15-all-de-en.$l.tok ; done
$ th preprocess.lua -train_src ../wmt15-de-en/wmt15-all-de-en.en.tok -train_tgt ../wmt15-de-en/wmt15-all-de-en.de.tok -valid_src ../wmt15-de-en/newstest2013.en.tok -valid_tgt ../wmt15-de-en/newstest2013.de.tok -save_data ../wmt15-de-en/wmt15-all-en-de
Building source vocabulary...
Created dictionary of size 50004 (pruned from 1110036)
Building target vocabulary...
Created dictionary of size 50004 (pruned from 2158804)
... 100000 sentences prepared
... 200000 sentences prepared
... 300000 sentences prepared
... 400000 sentences prepared
... 500000 sentences prepared
[...]
... 4100000 sentences prepared
... 4200000 sentences prepared
... 4300000 sentences prepared
... 4400000 sentences prepared
... 4500000 sentences prepared
... shuffling sentences
... sorting sentences by size
Prepared 4143915 sentences (391607 ignored due to length == 0 or > 50)
Preparing validation data...
... shuffling sentences
... sorting sentences by size
Prepared 2891 sentences (109 ignored due to length == 0 or > 50)
Saving source vocabulary to '../wmt15-de-en/wmt15-all-en-de.src.dict'...
Saving target vocabulary to '../wmt15-de-en/wmt15-all-en-de.tgt.dict'...
Saving data to '../wmt15-de-en/wmt15-all-en-de-train.t7'...
- Launch the training on the first GPU (check which GPU is available using
nvidia-smi)
th train.lua -data ../wmt15-de-en/wmt15-all-en-de-train.t7 -save_model ../wmt15-de-en/wmt15-all-en-de -gpuid 1
Loading data from '../data/wmt15-de-en/wmt15-all-en-de-train.t7'...
* vocabulary size: source = 50004; target = 50004
* additional features: source = 0; target = 0
* maximum sequence length: source = 50; target = 51
* number of training sentences: 4143915
* maximum batch size: 64
Building model...
* using input feeding
Initializing parameters...
* number of parameters: 84814004
Preparing memory optimization...
* sharing 69% of output/gradInput tensors memory between clones
Start training...
Epoch 1 ; Iteration 50/64773 ; Learning rate 1.0000 ; Source tokens/s 166 ; Perplexity 186592.55
[...]
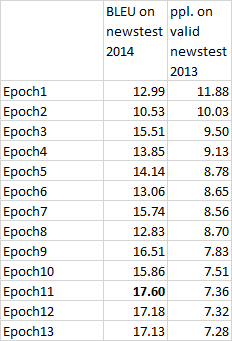
- Wait… (about 2 days on a server with recent GPU card)