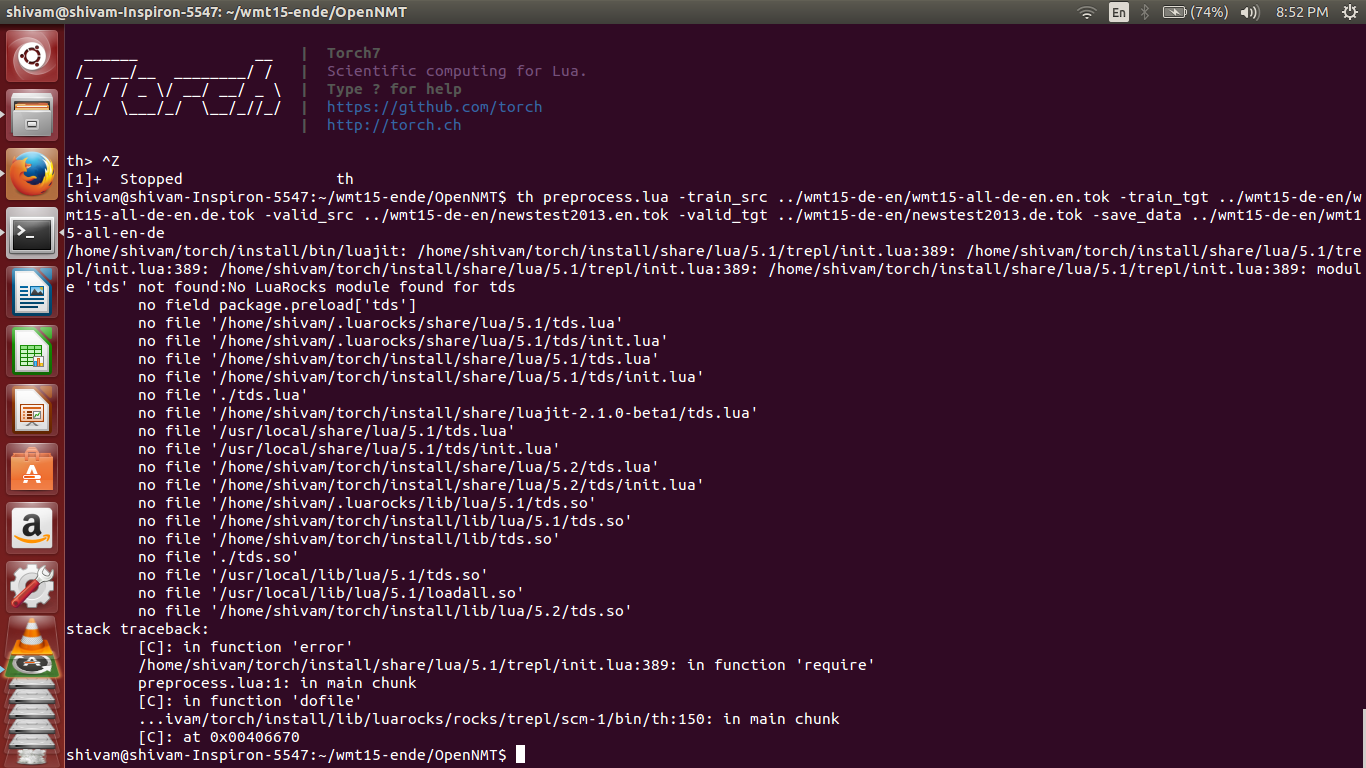
I am having error while running the preprocess command
You need to install the tds package:
luarocks install tds

If you don’t have a GPU you can’t use the -gpuid 1 option.
So any alternate i can use t run this?
Instead of:
th train.lua -data ../wmt15-de-en/wmt15-all-en-de-train.t7 -save_model ../wmt15-de-en/wmt15-all-en-de -gpuid 1
use:
th train.lua -data ../wmt15-de-en/wmt15-all-en-de-train.t7 -save_model ../wmt15-de-en/wmt15-all-en-de
and be patient.
how much days it will take to complete ?
The tutorial mentions 2 days on a GPU. You can at least multiply this number by 10 on a CPU.
1 Like
@shivamkalia Although it says two days on a GPU, after I prepped the corpora and obtained the 4 million segment base (note I also tokenized the corpus with -case_feature and -joiner_annotate options) my GPU based computer (NVIDIA GTX 1060) is at the middle of the 6th epoch, and will run for at least 6 days. On a CPU, a much smaller corpus (like 1,7 mln) was going to build all 13 epochs in some 90 days.
Bottomline: if you want to use NMT seriously, buy an NVIDIA card, install Linux, and enjoy. Well, I am still performing some tests on a Linux virtual machine, but these are only to get accustomed to Linux and OpenNMT in general.
@jean.senellart @guillaumekln I am currently running a 4M segment corpus OpenNMT training (all 4 concat WMT15 corpora) and made a test on some smaller corpus of around 77K segments to see if the results I can obtain with BPE tokenization + case feature + joiner_annotate are better than with default tokenization options. Here are the steps I took to create the model (same as the currently running big ENDE training):
> cd ~/OpenNMT
> sudo cat './endeproj/train_src.txt' './endeproj/train_tgt.txt' > ./endeproj/trainall.txt
> for f in ./endeproj/trainall.txt ; do echo "--- tokenize $f for BPE" ; th tools/tokenize.lua < $f > $f.tok ; done
> th tools/learn_bpe.lua -size 32000 -save_bpe ./endeproj/trainall.txt.tok.bpe < ./endeproj/trainall.txt.tok
> for f in ./endeproj/*.txt ;do echo "--- tokenize $f" ; th tools/tokenize.lua -joiner_annotate true -case_feature true -bpe_model ./endeproj/trainall.txt.tok.bpe < $f > $f.tok ; done
> mkdir ./endeproj/endeproj_model
> th preprocess.lua -train_src './endeproj/train_src.txt.tok' -train_tgt './endeproj/train_tgt.txt.tok' -valid_src './endeproj/tune_src.txt.tok' -valid_tgt './endeproj/tune_tgt.txt.tok' -save_data ./endeproj/endeproj_model/endeproj_model
> th train.lua -layers 4 -rnn_size 1000 -brnn -word_vec_size 600 -data ./endeproj/endeproj_model/endeproj_model-train.t7 -save_model ./endeproj/endeproj_model/endeproj_model/ende_nmt_model -gpuid 1
It was run on a GPU. Then I used the same corpus (sam tuning/testing) to build a model using default tokenization on a CPU virtual machine, using the following steps:
> for f in ./endecpu/*.txt ;do echo "--- tokenize $f" ; th tools/tokenize.lua < $f > $f.tok ; done
> mkdir ./endecpu/endeproj_model
> th preprocess.lua -train_src ./endecpu/training_Proj_Mst_Prm_sgl_ende._srcs.txt.tok -train_tgt ./endecpu/training_Proj_Mst_Prm_sgl_ende._tgts.txt.tok -valid_tgt ./endecpu/tuning_Proj_Mst_Prm_sgl_ende._tgts.txt.tok -valid_src ./endecpu/tuning_Proj_Mst_Prm_sgl_ende._srcs.txt.tok -save_data ./endecpu/endeproj_model/endeproj_start
> th train.lua -data ./endecpu/endeproj_model/endeproj_start-train.t7 -save_model ./endecpu/endeproj_model/ende_crm_nmt_model_cpu
Basically, the tokenization was different. NOTE I used tools/learn_bpe.lua script.
Then, I translated a test chunk with the best epoch (it was Epoch 13 in both), and got a substantial difference in BLEU and Edit Distance:
BPE / Case / Joiner Tok. Model: 39.38 BLEU
Default Tok. Model: 49.23 BLEU
Do you have an idea what is wrong? Does it mean a corpus of less than 100K segments should not be trained with the options mentioned here? If not, how to correlate the best options with corpus size? Can there be an issue in the LUA learn bpe script? Is that an effect of joiner_annotate with case_feature?
Hi,
When evaluating the “BPE / Case / Joiner Tok.” model, did you also apply the custom tokenization on the test data?
@guillaumekln Yes, when checking the BLEU of the BPE/Case/Joiner models, I used a tokenized test corpus. See for f in ./endeproj/*.txt ;do echo "--- tokenize $f" ; th tools/tokenize.lua -joiner_annotate true -case_feature true -bpe_model ./endeproj/trainall.txt.tok.bpe < $f > $f.tok ; done, this prepped all the .TXT files (train/test/tune) and translation was run with the following command:
for f in ~/OpenNMT/endeproj/endeproj_model/endeproj_ende_nmt_model_epoch*.t7
do
th translate.lua -model $f -src ~/OpenNMT/endeproj/endeproj_model/trans/tst_src.txt.tok -output ~/OpenNMT/endeproj/endeproj_model/trans/${f##*/}_MT.txt;
echo ~/OpenNMT/endeproj/endeproj_model/trans/${f##*/}_MT.txt >> ~/OpenNMT/endeproj/endeproj_model/trans/BLEU_scores.txt;
perl benchmark/3rdParty/multi-bleu.perl ~/OpenNMT/endeproj/endeproj_model/trans/test_tgt.txt.tok < ~/OpenNMT/endeproj/endeproj_model/trans/${f##*/}_MT.txt >> ~/OpenNMT/endeproj/endeproj_model/trans/BLEU_scores.txt;
done
This is how I check which epoch yields the best quality (maybe there is a better script, but I do not know where to get one).
I just wonder if the parameters for the training depend greatly on the corpus size. If not, then I do not understand this score discrepancy.
The scores are not exactly comparable as the tokenization is different. I would suggest to:
- detokenize the output
- retokenize the detokenized output and the original reference using the default options
- compute the BLEU score on the files generated in 2.
@jean.senellart @guillaumekln Ok, I re-tokenized the detokenized BPE/joiner/case model translated file with default tokenization options. I see the Edit Distance is now twice as better.
I am sorry, I had to edit the post since I found out I used default train.lua params (and thus, I did not use -layers 4 -rnn_size 1000 -brnn -word_vec_size 600 when checking default tokenization options). So, the actual results are:

These results tell me that @vince62s is correct and the training options I used (those from ENDE WMT16 training scenario) are not a good choice for the 80K segment model. It also proves that BPE and -joiner_annotate are improving our Edit Distance results (-3.7% vs. -1.81%). What I do not understand is why BPE + -joiner_annotate and -case_feature yield the worst score. Why does -case_feature worsen BLEU so much?
are these results on 4M segments or 100K segements.
you cannot use a 4x1000 network for 100K segments, this will overfit very rapidly.
@vince62s I found the “culprit”: I compared the wrong models. I updated the post above. Now, I am really curious why -case_feature worsens BLEU score so much. @jean.senellart says:
And it turns out it is not a good idea… Or I am missing something.
First of all, again, looking at results on a 4x1000 network for 80K sentences does not really make any sense.
How did you score your 40s numbers ? valid set outside from training set ?
This has to be really in-domain.
Anyhow, yes I think you missed a step.
If you want to user BPE and case feature, the best thing to do is to build the BPE model on lowercased data.
Look at the -lc option.
Cheers.
@vince62s @jean.senellart Ok, I’ve studied the Overfitting topic on Coursera (Deep Machine Learning course) and see what you mean. The capacity of the network is so big that it learns correct and spurious regularities. That adds more questions that I cannot find answers now:
- How can I choose the best network architecture given the size of the corpus for training? Is that approx. 1M segments (=lines) x 1000 units?
- What should be the optimal number of units per layer? In the ENDE WMT16 exercise, 4 layers with 1000 units each were set - why not a single layer with 4000 units?
(And to answer how I calculated the scores, I partitioned the corpus beforehand into training / tuning / testing chunks and training was used for training and tuning was used for validation. Testing chunk was a set of completely unseen data, as before partitioning, I de-duped the corpus thoroughly. However, these texts come from a single customer, and must be “in-domain”, or similar to the training and tuning sets. That is the goal: to make a model that can translate certain customer’s contents the way it used to be translated).
Now, coming back to BPE and -case_feature: I tried to do 2 things.
1) I did not turn the corpus for BPE model learning to lowercase, I just used -bpe_case_insensitive when tokenizing train/validation (tuning) corpora
cat ${fldr}/train_src.txt ${fldr}/train_tgt.txt > ${fldr}/trainall; \ # concat src and tgt
for f in ${fldr}/trainall ; do echo "--- tokenize $f for BPE" ; th tools/tokenize.lua < $f > $f.tok ; done; \ # tokenize with default options
th tools/learn_bpe.lua -size 32000 -save_bpe ${fldr}/trainall.tok.bpe < ${fldr}/trainall.tok; \ # learnt BPE model
for f in ${fldr}/*.txt ;do echo "--- tokenize $f with BPE/joiner" ; th tools/tokenize.lua -case_feature true -joiner_annotate true -bpe_case_insensitive -bpe_model ${fldr}/trainall.tok.bpe < $f > $f.tok ; done; \ # Tokenized train/test with the BPE model using -bpe_case_insensitive option
2) I turned the corpus for BPE model training to lowercase with sed, and then
cat ${fldr}/train_src.txt ${fldr}/train_tgt.txt > ${fldr}/trainall; \ # concat src and tgt
sed -i 's/.*/\L&/' ${fldr}/trainall; \ # turned the combined corpus to lower case
for f in ${fldr}/trainall ; do echo "--- tokenize $f for BPE" ; th tools/tokenize.lua < $f > $f.tok ; done; \ # Tokenized the corpus for BPE model with default options
th tools/learn_bpe.lua -size 32000 -save_bpe ${fldr}/trainall.tok.bpe < ${fldr}/trainall.tok; \ # Learnt the BPE model
for f in ${fldr}/*.txt ;do echo "--- tokenize $f with BPE/joiner" ; th tools/tokenize.lua -case_feature true -joiner_annotate true -bpe_case_insensitive -bpe_model ${fldr}/trainall.tok.bpe < $f > $f.tok ; done; \ # Tokenized the train/tune/test corpora with the BPE model and -bpe_case_insensitive option
The first one yielded BLEU = 39.38 (let’s forget if it is good or bad, it is just to compare with the baseline, which is 49.23
with default tokenization), and the second one yielded BLEU = 34.49.
If you can help spot the error in my logic, I will be very grateful.
Neural Network is unfortunately not an exact science …it’s more like medecine  you have to experiment, experiment experiment.
you have to experiment, experiment experiment.
Regarding the size of the network, for 1M segment, 2x500 is fine.
If you train a 4x1000 network, I would say you need at least 5M segments, probably more. But again you need to experiment.
Regarding the question is 4x1000 comparable to 4000, no for 2 reasons:
You don’t have the same number of parameters, and also with more layers (obviously in this case 4) you will model better the non linearities.
Back to your BLEU scores, difficult to say based on what you provide.
Did you compute BLEU on tokenized BPE subword ? on detokenized then mt-eval process ?
Again if you used 4x1000 with a few hundred thousand segments, it is not relevant.
Try to retrain this small corpus with a small network and compare apples to apples.
NB: I think (not sure) that with learn_bpe.lua the -bpe_case_insensitive is irrelevant.
cheers.
@vince62s Thank you for some concrete feedback. I see now the relationship between number of units and the number of parameters. Back to my BLEU scores, these figures come from translating the test chunks (tokenized as the training and tuning chunks) with several epochs (I used to translate with all 13, now, I only translate with 10-13).
Here is my script:
cp ${fldr}/test_src.txt.tok ${fldr}/models/trans/test_src.txt.tok; \ # Copy tokenized source file to test folder
cp ${fldr}/test_tgt.txt.tok ${fldr}/models/trans/test_tgt.txt.tok; \ # Copy tokenized human translated file to test folder
for f in ${fldr}/models/${prefix}_epoch1?_*.t7; do th translate.lua -model $f -src ${fldr}/models/trans/test_src.txt.tok -output ${fldr}/models/trans/${f##*/}_MT.txt -gpuid 1; echo ${fldr}/models/trans/${f##*/}_MT.txt >> ${fldr}/models/trans/${prefix}_bleu_scores.log; perl benchmark/3rdParty/multi-bleu.perl ${fldr}/models/trans/test_tgt.txt.tok < ${fldr}/models/trans/${f##*/}_MT.txt >> ${fldr}/models/trans/${prefix}_bleu_scores.log; done; \ # Translate src file with Epochs 10-13, run BLEU calculation and save to a log
for f in ${fldr}/models/trans/*.txt ; do echo "--- Detokenize $f" ; th tools/detokenize.lua -case_feature < $f > $f.detok ; done; \ # Detokenize the text files (they are all MT translated files)
for f in ${fldr}/models/trans/${prefix}_epoch*.detok ;do echo "--- re-tokenize $f with default" ; th tools/tokenize.lua < $f > $f.retok ; done; # Retokenize the detokenized files for Edit Distance analysis
IMHO, the amount of BLEU is not relevant because it is in line with the Edit Distance I run on the translated test chunks that I first detokenize and then re-tokenize with default tokenization settings.
The current issue is that I am not sure I udnerstand how to use BPE together with -case_feature, and whether to forget about it, and just use BPE (as is) with just -joiner_annotate.