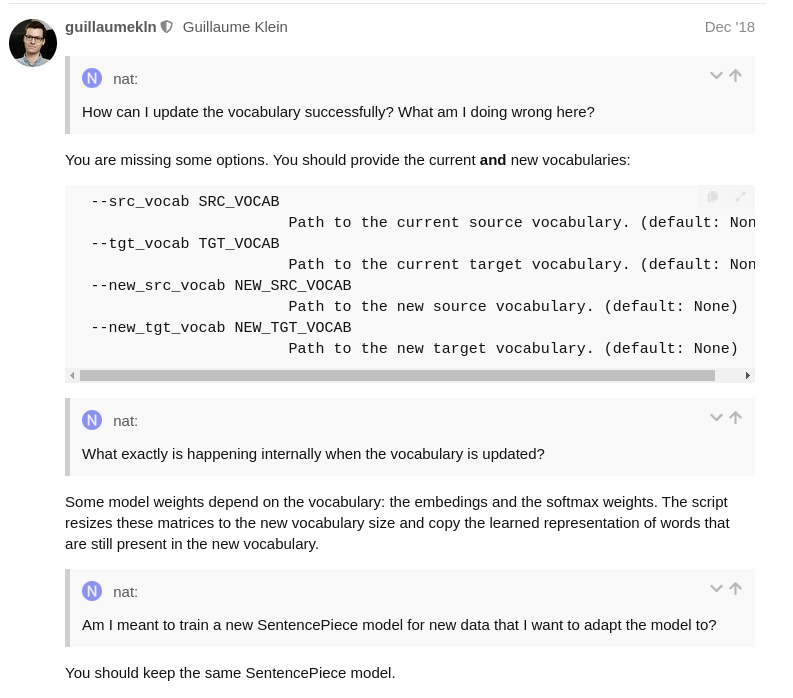
why should I keep the previous spm model, because by training a new model on domain data, the quality of tokenization and translation should be better. How difficult is it to create a pipeline with your framework for training a new spm model, including on domain data, while maintaining the possibility of additional training? Perhaps you can give some advice?