After reading all the papers,
I decided to give it a go. Here how I did it:
- I aligned my data in something which I call a caption (can be a full sentence or not depending on the size)
- I created an ID to keep track of the caption that are consecutive (from the origine of their text).
- I filtered any caption that didn’t fit in my filtering rules
- I grouped the captions. All captions that are still consecutive compare to the original text are grouped together. (this is achieved with the consecutiveness of the ids)
- Calculated the number of caption per group and randomize the groups.
- Determined the number of caption I wanted for training/testing/validation
- Splited the groups in 3 categories in order to have more or less the target number of captions for training/testing/validation
- Generated the concatenation of the caption in order to have 3 captions per line:
Caption1 + Caption2 + Caption3
Caption2 + Caption3 + Caption4
Caption3 + Caption4 + Caption5
- Kept the individual caption in the batch too…
- Applied augmentation technique on top of these.
I generated different formats to facilitate the testing afterwards. I have one file with only the 3 captions merged together and 1 file with just the basic caption.
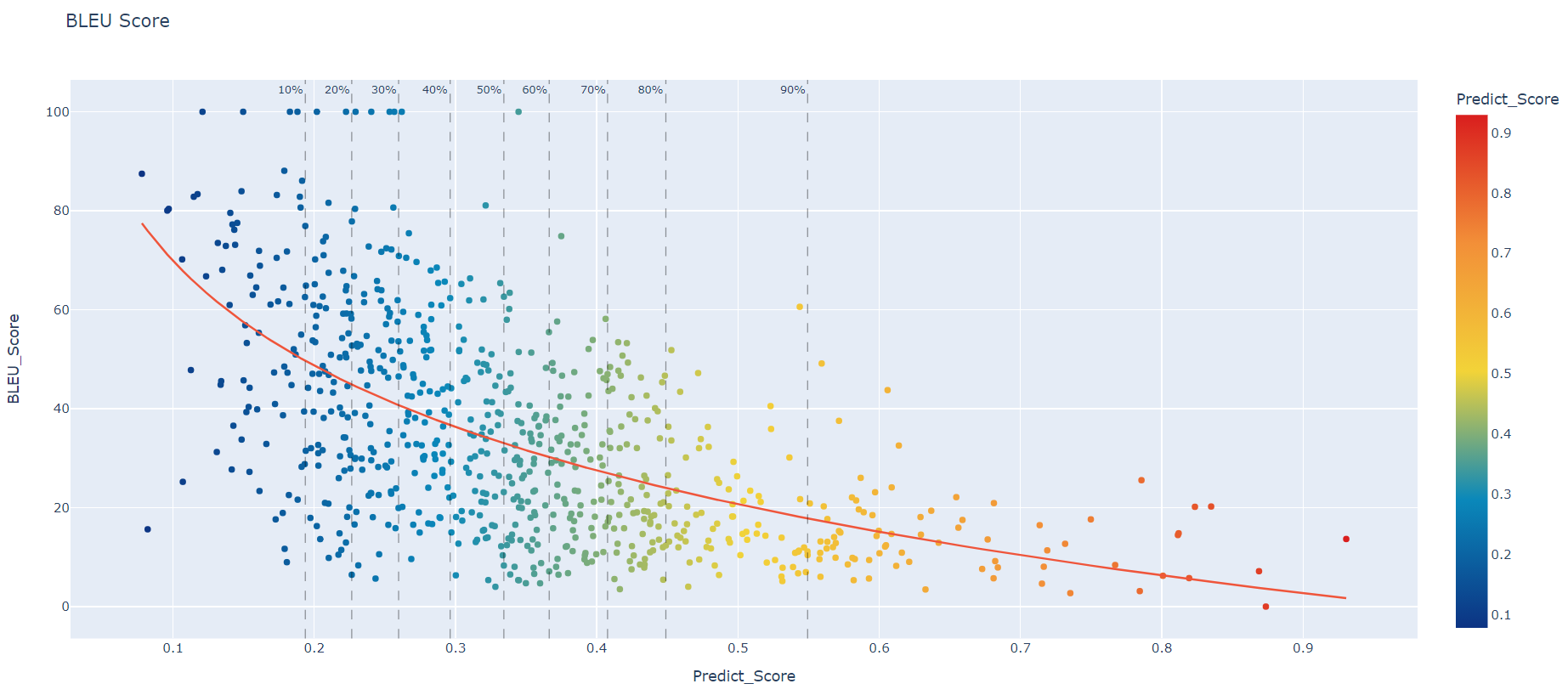
So far, this is a graph I obtained with my previous model which was trained with the same thing except for the merged 3 captions:
Note for graphs:
- the % at the top represent the % of the test case that are in present in the section before the line
- each dots represent a segment that was translated.
-Based on the same data, but not the same testing/training/validation files.
This is the results with 3 captions, but testing with single caption (not merged). So Bleu score should be comparable.
So far, if we compare both graphs we can noticed about + 3 BLEU in average. Data is comparable.
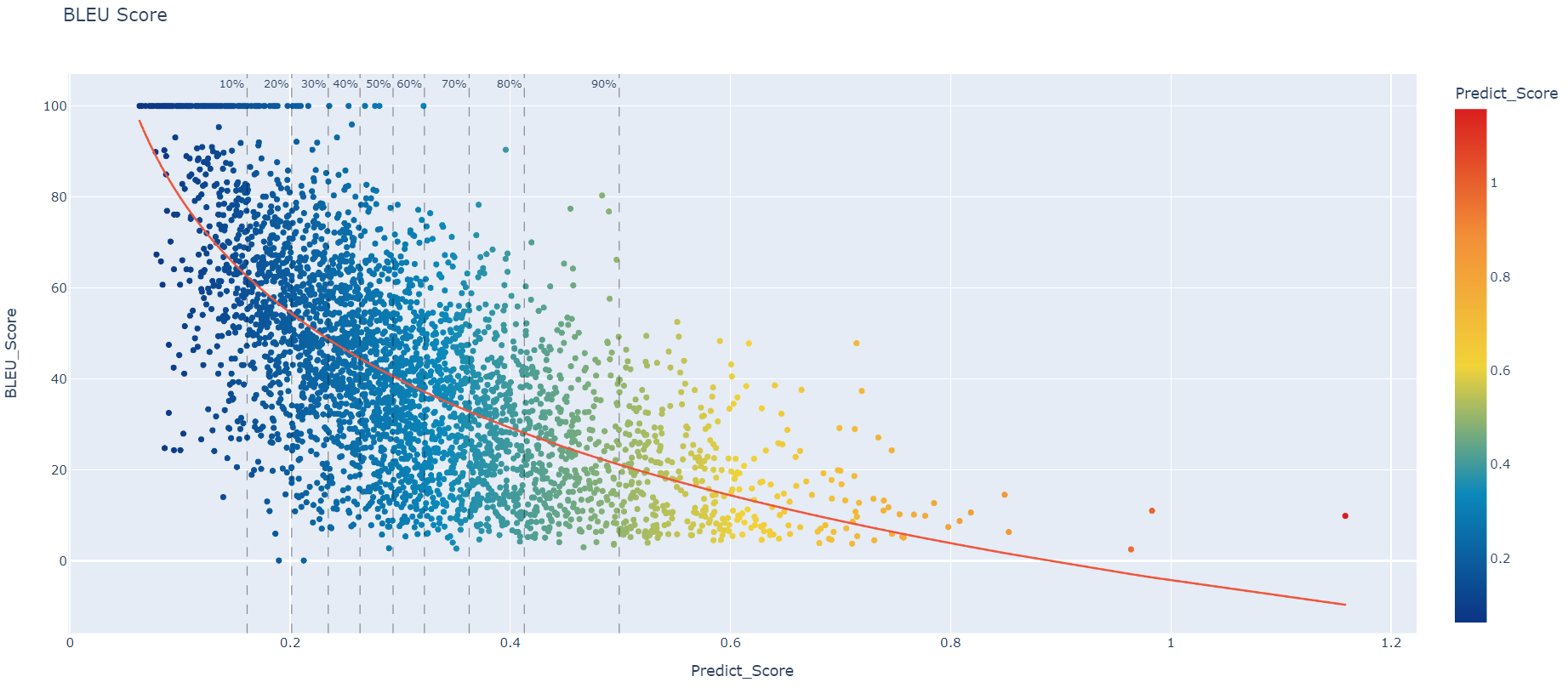
and finally this is test set with the 3 captions merged.
It’s can’t be compared to the 2 others conceptually, but there is something interesting in there… There are really few dots at the bottom left. Which is when the model is confident, but yet there is a big gap with the expected. I have found that this zone is either lack of context or golden record was wrong.
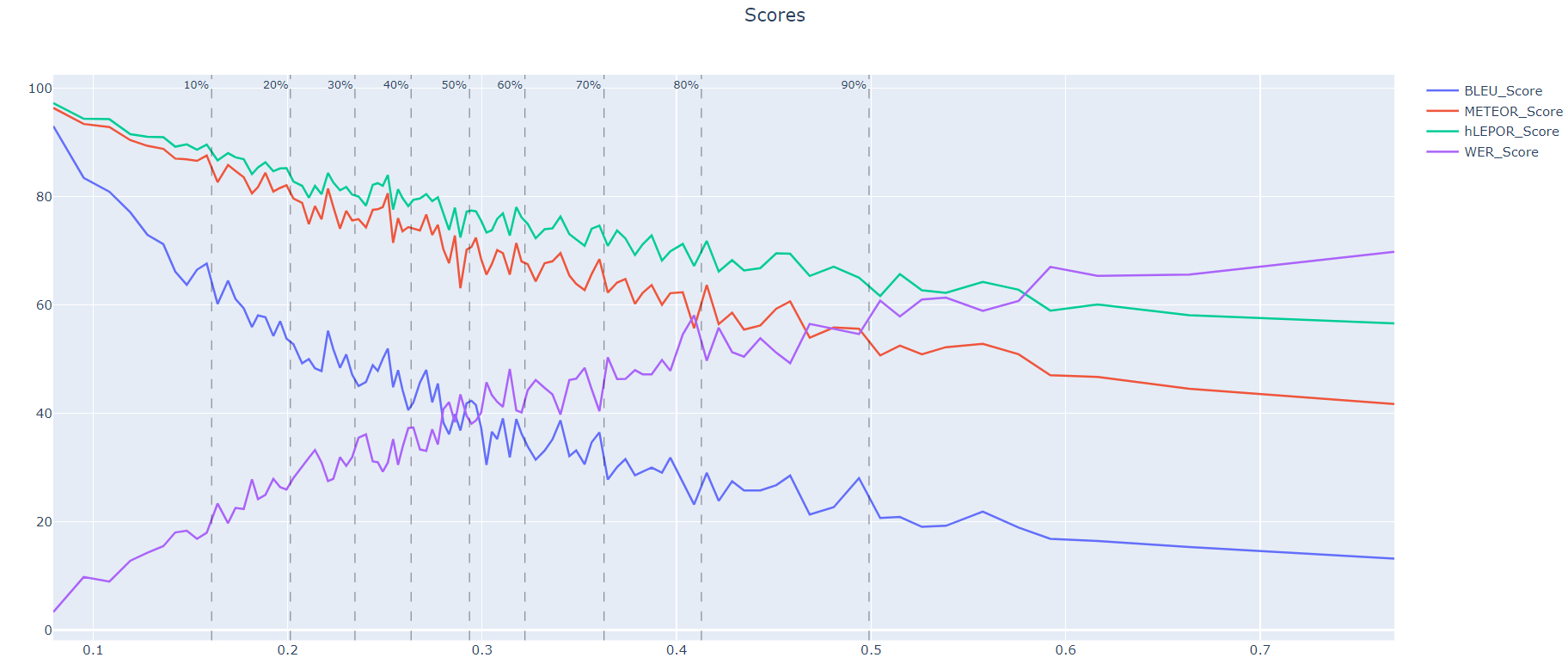
I believe the BLEU score also have a bios. The more words you have the less it becomes accurate, but I see this pattern also in my graphs for WER/hLEPOR/METEOR
So it seems that the model trained with more context will still improve smaller sentences.
here the resume of my first model without 3 captions merged:
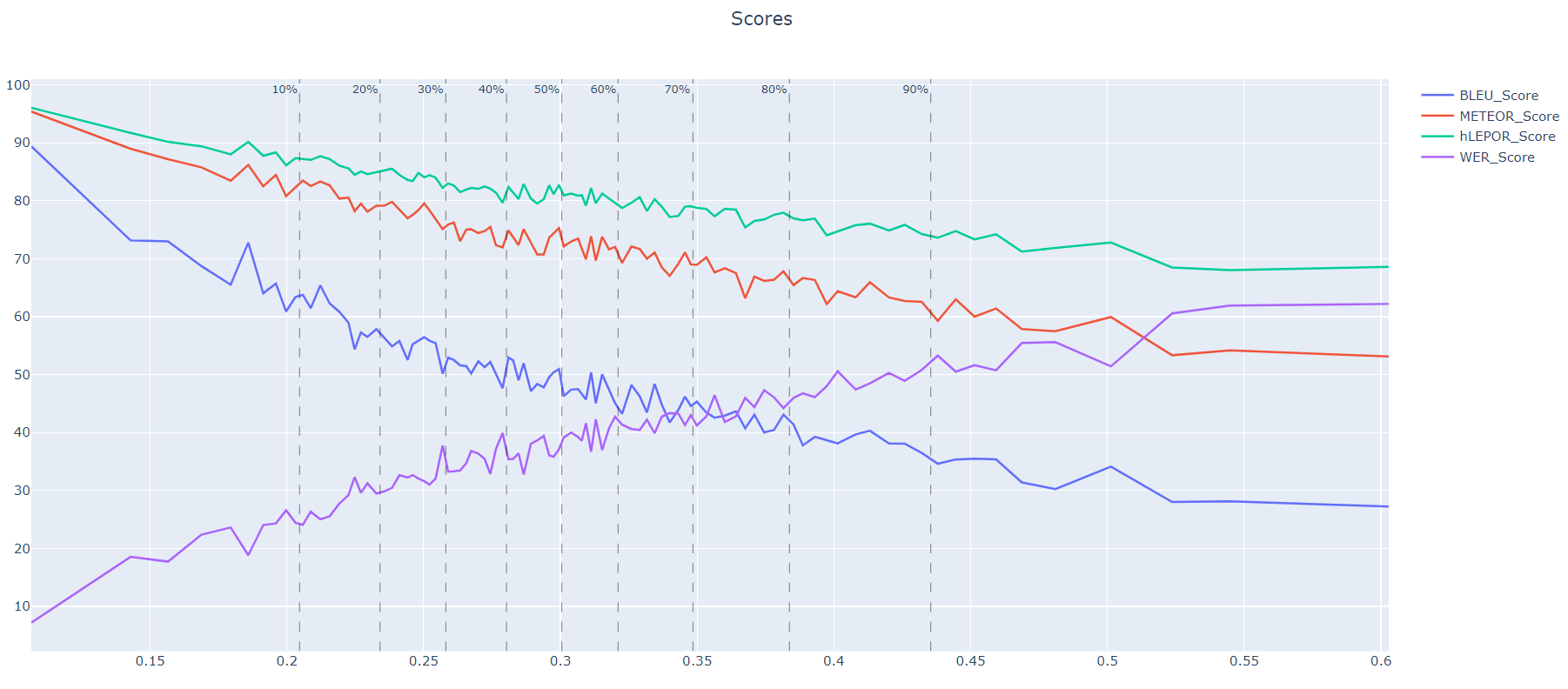
model with 3 captions merged but only tested on single captions:
model with 3 captions tested with 3captions set:
next step is to use my model with 3 captions and the testing batch with 3 captions, but translate “knowing” the 2 first and see how it improve the BLEU score. I’m having some dificulty to make it work in ctransalte2… will update this post when I get the graphs.
Best regards,
Samuel