@argosopentech Thanks for your response.
I´m now inside the docker container. The source file size assert error is now calling
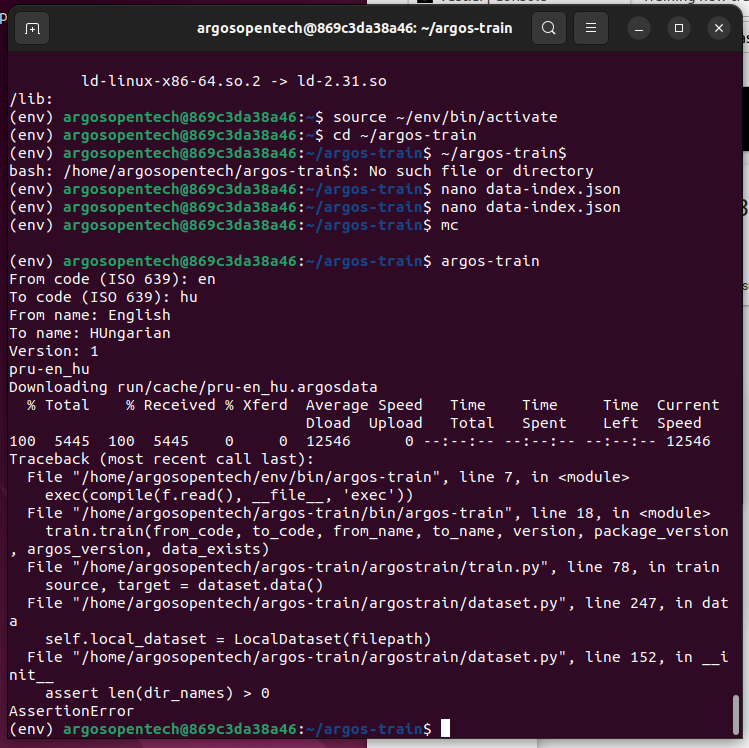
assert len(source_data) > VALID_SIZE
if i check it with a print statement
Len source is 1275 and the limit is: 2000
so the minimum size of chars are 2000 ?
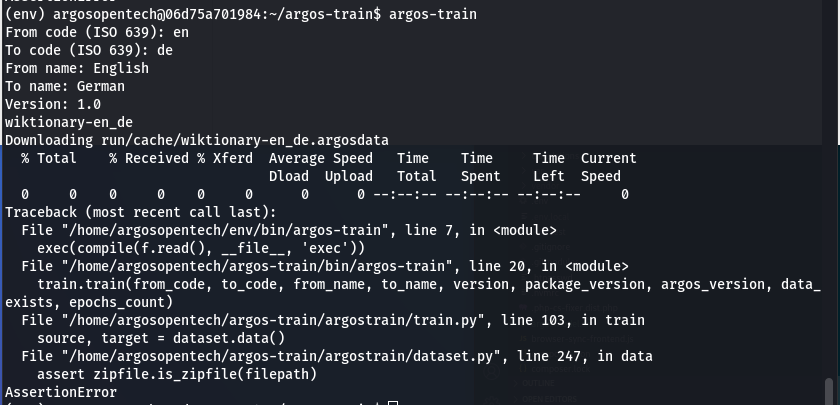
If i comment it out i get the next error
“”"
denormalizer_spec {}
trainer_interface.cc(350) LOG(INFO) SentenceIterator is not specified. Using MultiFileSentenceIterator.
trainer_interface.cc(181) LOG(INFO) Loading corpus: run/split_data/all.txt
trainer_interface.cc(406) LOG(INFO) Loaded all 0 sentences
trainer_interface.cc(422) LOG(INFO) Adding meta_piece:
trainer_interface.cc(422) LOG(INFO) Adding meta_piece:
trainer_interface.cc(422) LOG(INFO) Adding meta_piece:
trainer_interface.cc(427) LOG(INFO) Normalizing sentences…
spm_train_main.cc(275) [status.ok()] Internal: src/trainer_interface.cc(428) [!sentences.empty()]
Program terminated with an unrecoverable error.
Corpus corpus_1’s weight should be given. We default it to 1 for you.
Traceback (most recent call last):
File “/home/argosopentech/env/bin/onmt_build_vocab”, line 33, in
sys.exit(load_entry_point(‘OpenNMT-py’, ‘console_scripts’, ‘onmt_build_vocab’)())
File “/home/argosopentech/OpenNMT-py/onmt/bin/build_vocab.py”, line 71, in main
build_vocab_main(opts)
File “/home/argosopentech/OpenNMT-py/onmt/bin/build_vocab.py”, line 32, in build_vocab_main
transforms = make_transforms(opts, transforms_cls, fields)
File “/home/argosopentech/OpenNMT-py/onmt/transforms/transform.py”, line 235, in make_transforms
transform_obj.warm_up(vocabs)
File “/home/argosopentech/OpenNMT-py/onmt/transforms/tokenize.py”, line 147, in warm_up
load_src_model.Load(self.src_subword_model)
File “/home/argosopentech/env/lib/python3.10/site-packages/sentencepiece/init.py”, line 905, in Load
return self.LoadFromFile(model_file)
File “/home/argosopentech/env/lib/python3.10/site-packages/sentencepiece/init.py”, line 310, in LoadFromFile
return _sentencepiece.SentencePieceProcessor_LoadFromFile(self, arg)
OSError: Not found: “run/sentencepiece.model”: No such file or directory Error #2
[2023-04-06 11:39:41,855 WARNING] Corpus corpus_1’s weight should be given. We default it to 1 for you.
[2023-04-06 11:39:41,856 INFO] Parsed 2 corpora from -data.
Traceback (most recent call last):
File “/home/argosopentech/env/bin/onmt_train”, line 33, in
sys.exit(load_entry_point(‘OpenNMT-py’, ‘console_scripts’, ‘onmt_train’)())
File “/home/argosopentech/OpenNMT-py/onmt/bin/train.py”, line 172, in main
train(opt)
File “/home/argosopentech/OpenNMT-py/onmt/bin/train.py”, line 106, in train
checkpoint, fields, transforms_cls = _init_train(opt)
File “/home/argosopentech/OpenNMT-py/onmt/bin/train.py”, line 58, in _init_train
ArgumentParser.validate_prepare_opts(opt)
File “/home/argosopentech/OpenNMT-py/onmt/utils/parse.py”, line 197, in validate_prepare_opts
cls._validate_fields_opts(opt, build_vocab_only=build_vocab_only)
File “/home/argosopentech/OpenNMT-py/onmt/utils/parse.py”, line 151, in _validate_fields_opts
cls._validate_file(opt.src_vocab, info=‘src vocab’)
File “/home/argosopentech/OpenNMT-py/onmt/utils/parse.py”, line 18, in _validate_file
raise IOError(f"Please check path of your {info} file!“)
OSError: Please check path of your src vocab file!
Traceback (most recent call last):
File “/home/argosopentech/env/bin/argos-train”, line 7, in
exec(compile(f.read(), file, ‘exec’))
File “/home/argosopentech/argos-train/bin/argos-train”, line 27, in
train.train(from_code, to_code, from_name, to_name, version, package_version, argos_version, data_exists, epochs_count)
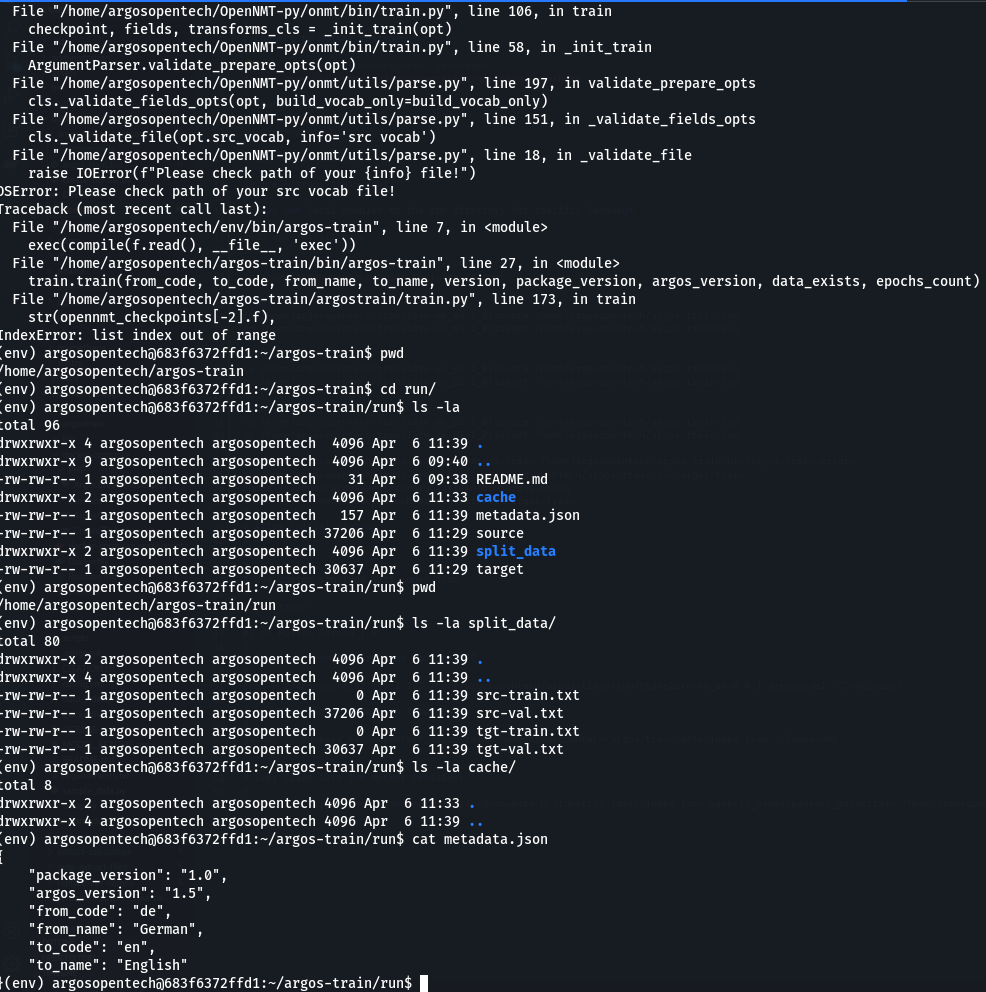
File “/home/argosopentech/argos-train/argostrain/train.py”, line 173, in train
str(opennmt_checkpoints[-2].f),
IndexError: list index out of range
“””
OSError: Not found: “run/sentencepiece.model”: No such file or directory Error #2
OSError: Please check path of your src vocab file!
How can i create the sentencepiece.model file, and what content should it have and what Im doin wrong ?
The source and target files inside the directory (pwd)
/home/argosopentech/argos-train/run
Please help me to get this code working.