Hello, I’m trying to use the multi language model of opus ml only I noticed that with ctranslate2, it returns <pad> during each translation if you use the model of mul-en direction. In the other direction (en-mul) everything works correctly. Here is an example:
import ctranslate2
import transformers
translator = ctranslate2.Translator("/home/jourdelune/opus-mt/")
tokenizer = transformers.AutoTokenizer.from_pretrained("Helsinki-NLP/opus-mt-mul-en")
source = tokenizer.convert_ids_to_tokens(tokenizer.encode(">>fra<<Bonjour le monde"))
results = translator.translate_batch([source])
target = results[0].hypotheses[0]
print(tokenizer.decode(tokenizer.convert_tokens_to_ids(target)))
output:
<pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad>
Only the model with hugging face works:
from transformers import MarianMTModel, MarianTokenizer
src_text = [
">>fra<<Bonjour le monde",
]
model_name = "Helsinki-NLP/opus-mt-mul-en"
tokenizer = MarianTokenizer.from_pretrained(model_name)
model = MarianMTModel.from_pretrained(model_name)
translated = model.generate(**tokenizer(src_text, return_tensors="pt", padding=True))
print([tokenizer.decode(t, skip_special_tokens=True) for t in translated])
output:
['Welcome to the World']
I converted the model with this command:
ct2-transformers-converter --model Helsinki-NLP/opus-mt-mul-en --output_dir opus-mt
The strange thing is that the translation works with the model used in the opposite direction (en-mul):
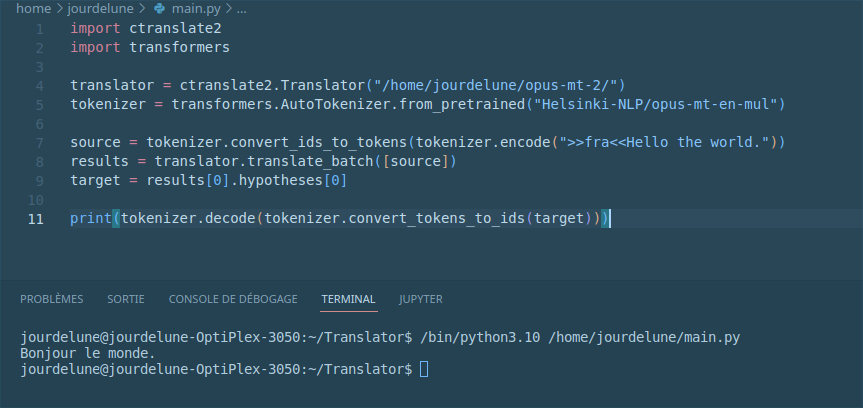
I converted the model with this command:
ct2-transformers-converter --model Helsinki-NLP/opus-mt-en-mul --output_dir opus-mt-2
If anyone has any idea why I’m experiencing this bug, don’t hesitate!