I have created source and target dictionary of source language and target language respectively using OpenNMT.
But i notice that the source language word in a specific line didn’t match with the word of target language on that specific line.
Is it required to match those words or it can manage automatically?
The order of words in vocabularies does not matter.
1 Like
I understand. But i want to clear. so i put some reference
Here is english vocab what I create
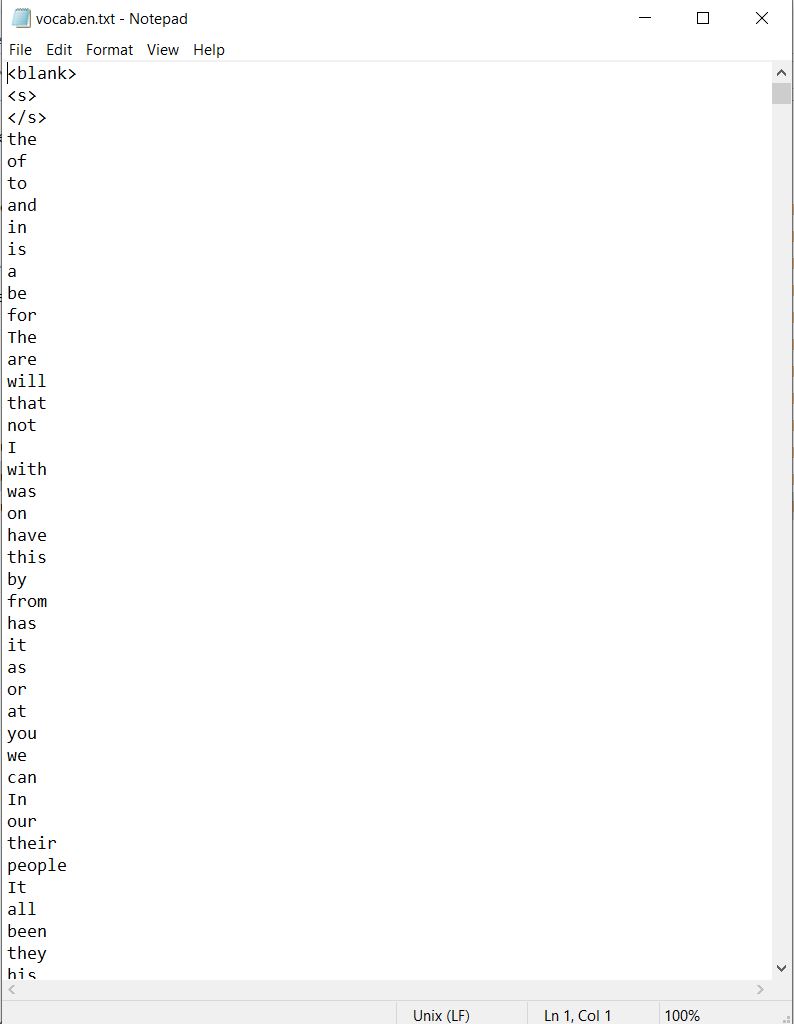
but according to my target vocabulary file it should be look like
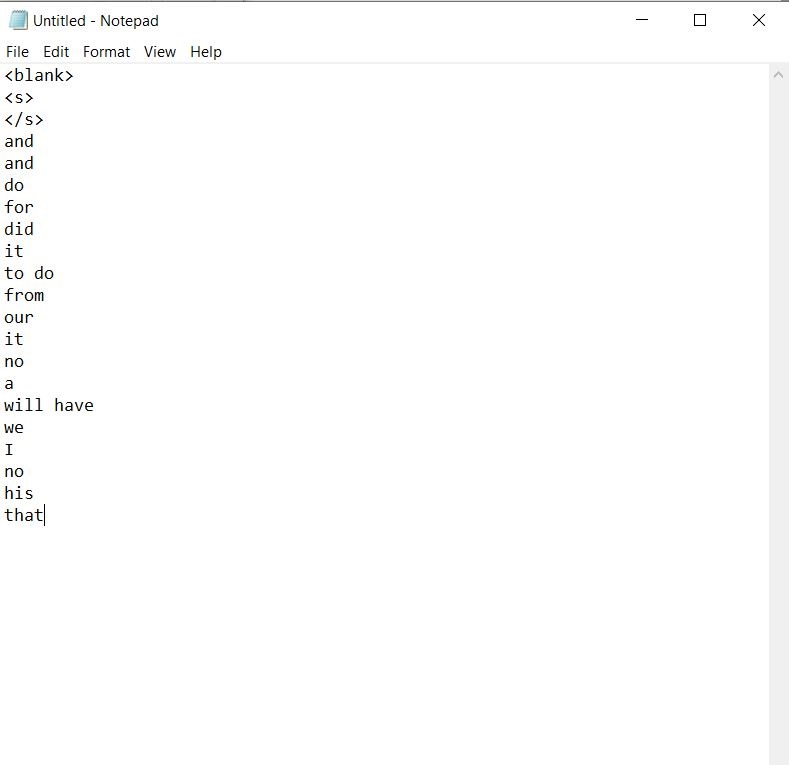
is it okay?
@shan778, The words in the vocab files have nothing to do with the order, If I will explain in a layman language, the list of words are assigned a unique number, and those numbers are only used in our models for training and all. as no machine understand text. it does not mater where these words are .
I hope this is clear.
And yes make sure all the words are there in you vocab file. ie vocab file of source should contain all the distinct words from the source file , and vocab file of target should contain all the distinct words from target file.
1 Like