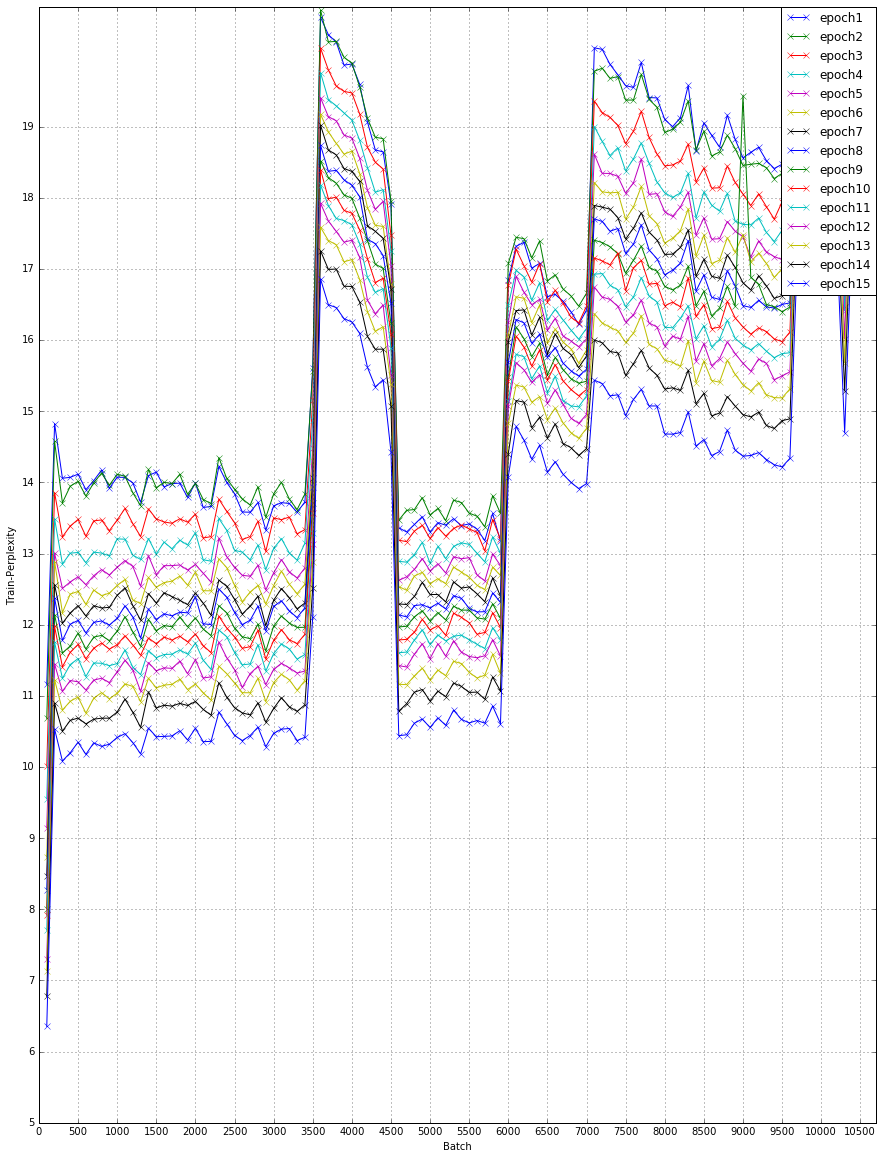
Hi, I have found sentence length affect train perplexity decrease. I’d like to train a model for English to Chinese. The network hidden layer is 1, and the data I use is about 0.8M which split to some buckets below:
(10,10), (10,20),(10,60),(20,10),(20,60),(60,60)
As you can image, the data distribution is not even. When data iterator skip from one bucket to another, the perplexity increase or decrease suddenly. From my view, the network learn the length information itself that the hyper parameters impact it. But I am confused about that now, please give me some advice.
It is (source length, target length), and the image shows all buckets. Different bucket has different samples (or batches). Each curve display the perplexity at different batch.
bucket of (10, 10) : 0 samples
bucket of (10, 20) : 0 samples
bucket of (10, 30) : 0 samples
bucket of (10, 40) : 0 samples
bucket of (10, 50) : 0 samples
bucket of (10, 60) : 0 samples
bucket of (20, 10) : 7983 samples
bucket of (20, 20) : 270197 samples ----- the perplexity is low
from now, the perplexity increase suddenly
bucket of (20, 30) : 75780 samples
bucket of (20, 40) : 703 samples ------ the perplexity decrease
bucket of (20, 50) : 25 samples
bucket of (20, 60) : 7 samples
bucket of (30, 10) : 178 samples
bucket of (30, 20) : 119753 samples
bucket of (30, 30) : 298605 samples
bucket of (30, 40) : 34903 samples
bucket of (30, 50) : 678 samples
bucket of (30, 60) : 28 samples
bucket of (40, 10) : 1 samples
bucket of (40, 20) : 614 samples
bucket of (40, 30) : 16563 samples
bucket of (40, 40) : 25968 samples
bucket of (40, 50) : 4138 samples
bucket of (40, 60) : 198 samples
bucket of (50, 10) : 0 samples
bucket of (50, 20) : 8 samples
bucket of (50, 30) : 123 samples
bucket of (50, 40) : 742 samples
bucket of (50, 50) : 906 samples
bucket of (50, 60) : 124 samples
bucket of (60, 10) : 0 samples
bucket of (60, 20) : 0 samples
bucket of (60, 30) : 1 samples
bucket of (60, 40) : 2 samples
bucket of (60, 50) : 3 samples
bucket of (60, 60) : 1 samples