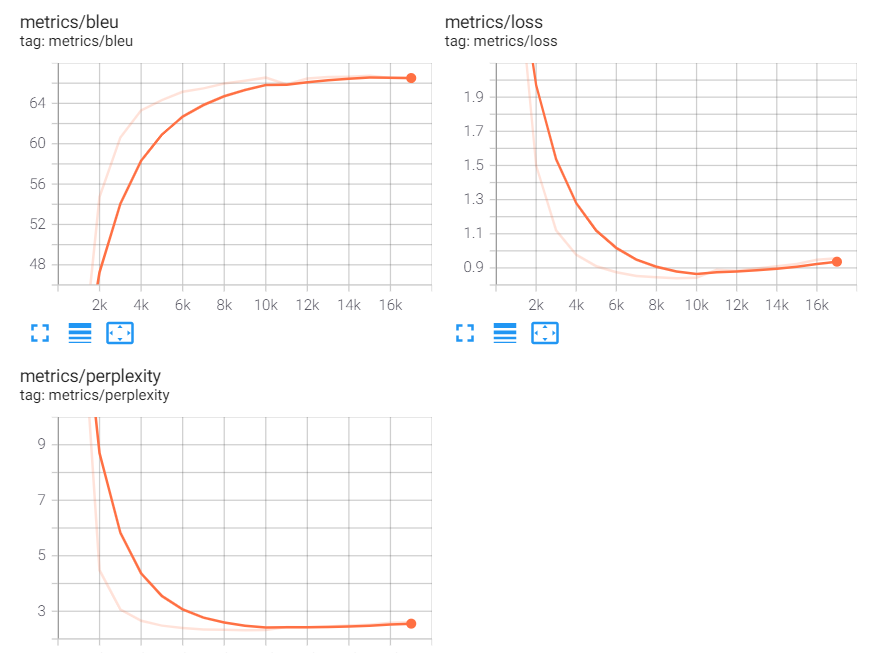
I believe the training should not know anything about the test sets. The tests are similar to real data, in that they are natural language without further processing (so, what you compare is predicted texts after any post-processing). Validation sets, on the other hand, are part of the training process, and they are already preprocessed and tokenised (at least in my case, since I use offline tokenisation). So, scores from validation are usually higher, but this does not mean the model overfits. However, I did notice that BLEU is less informative about overfitting than loss or perplexity. At least it seems it takes longer to reflect a possible overfitting, while loss might provide feedback on errors earlier. So it is not uncommon that BLEU keeps improving, but loss starts even to degrade. If you don’t have too many data or you think your model might overfit, I would try using loss for validation instead of BLEU as a metric to stop the training, then compare models using the test sets to see what metric turns out to be more reliable for you.
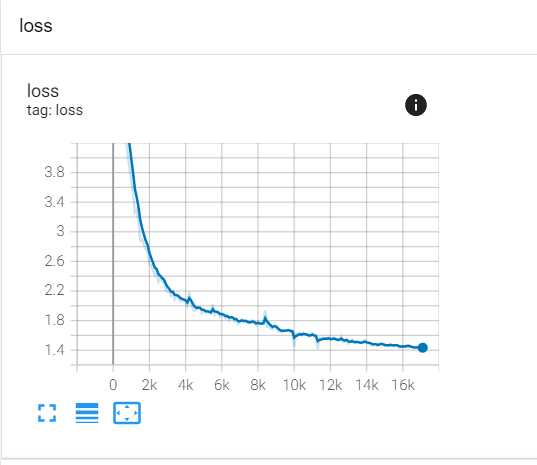
Exactly, the first loss is the training loss. If you don’t have too many data, it will continue improving until it “learns” all the data. The second is the validation loss, which is the one to be used as a main criteria to stop the training. From the graphs, I would say your model starts to overfit at around 10k steps, even if BLEU still improves until 15k. As I said, you can save both models, one at 10k and the other one at 15k, then predict the tests sets with both models and see what metric (BLEU, loss or perplexity) is more accurate in detecting the overfitting.