Yes indeed, however the result is the same (I had put 1 to test as I had the error with floating numbers).
The complete error:
[2022-02-07 20:48:34 +0000] [80492] [ERROR] Exception in ASGI application
Traceback (most recent call last):
File "/usr/local/lib/python3.9/dist-packages/uvicorn/protocols/http/httptools_impl.py", line 376, in run_asgi
result = await app(self.scope, self.receive, self.send)
File "/usr/local/lib/python3.9/dist-packages/uvicorn/middleware/proxy_headers.py", line 75, in __call__
return await self.app(scope, receive, send)
File "/usr/local/lib/python3.9/dist-packages/fastapi/applications.py", line 211, in __call__
await super().__call__(scope, receive, send)
File "/usr/local/lib/python3.9/dist-packages/starlette/applications.py", line 112, in __call__
await self.middleware_stack(scope, receive, send)
File "/usr/local/lib/python3.9/dist-packages/starlette/middleware/errors.py", line 181, in __call__
raise exc
File "/usr/local/lib/python3.9/dist-packages/starlette/middleware/errors.py", line 159, in __call__
await self.app(scope, receive, _send)
File "/usr/local/lib/python3.9/dist-packages/starlette/exceptions.py", line 82, in __call__
raise exc
File "/usr/local/lib/python3.9/dist-packages/starlette/exceptions.py", line 71, in __call__
await self.app(scope, receive, sender)
File "/usr/local/lib/python3.9/dist-packages/starlette/routing.py", line 656, in __call__
await route.handle(scope, receive, send)
File "/usr/local/lib/python3.9/dist-packages/starlette/routing.py", line 259, in handle
await self.app(scope, receive, send)
File "/usr/local/lib/python3.9/dist-packages/starlette/routing.py", line 61, in app
response = await func(request)
File "/usr/local/lib/python3.9/dist-packages/fastapi/routing.py", line 226, in app
raw_response = await run_endpoint_function(
File "/usr/local/lib/python3.9/dist-packages/fastapi/routing.py", line 159, in run_endpoint_function
return await dependant.call(**values)
File "/root/TranslationBot/Api/ApiTest.py", line 78, in run_prediction
prediction = await run_in_threadpool(lambda: model_class.translate(item.message, item.input, item.output))
File "/usr/local/lib/python3.9/dist-packages/starlette/concurrency.py", line 39, in run_in_threadpool
return await anyio.to_thread.run_sync(func, *args)
File "/usr/local/lib/python3.9/dist-packages/anyio/to_thread.py", line 28, in run_sync
return await get_asynclib().run_sync_in_worker_thread(func, *args, cancellable=cancellable,
File "/usr/local/lib/python3.9/dist-packages/anyio/_backends/_asyncio.py", line 818, in run_sync_in_worker_thread
return await future
File "/usr/local/lib/python3.9/dist-packages/anyio/_backends/_asyncio.py", line 754, in run
result = context.run(func, *args)
File "/root/TranslationBot/Api/ApiTest.py", line 78, in <lambda>
prediction = await run_in_threadpool(lambda: model_class.translate(item.message, item.input, item.output))
File "/root/TranslationBot/Api/ApiTest.py", line 49, in translate
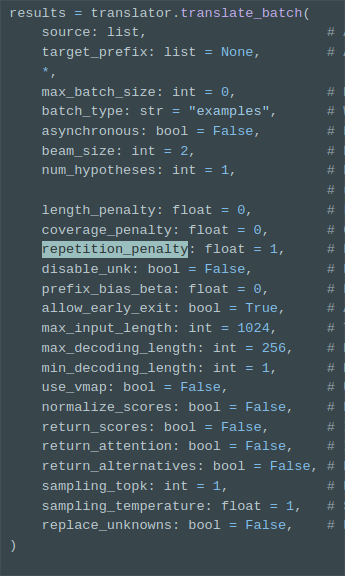
results = self.translator.translate_batch([tokens], target_prefix=[["__%s__" % output]], return_scores=False, beam_size=2, repetition_penalty=1.2, replace_unknowns=True)
TypeError: translate_batch(): incompatible function arguments. The following argument types are supported:
1. (self: ctranslate2.translator.Translator, source: List[List[str]], target_prefix: Optional[List[Optional[List[str]]]] = None, *, max_batch_size: int = 0, batch_type: str = 'examples', asynchronous: bool = False, beam_size: int = 2, num_hypotheses: int = 1, length_penalty: float = 0, coverage_penalty: float = 0, prefix_bias_beta: float = 0, allow_early_exit: bool = True, max_decoding_length: int = 250, min_decoding_length: int = 1, use_vmap: bool = False, normalize_scores: bool = False, return_scores: bool = False, return_attention: bool = False, return_alternatives: bool = False, sampling_topk: int = 1, sampling_temperature: float = 1, replace_unknowns: bool = False) -> Union[List[ctranslate2.translator.TranslationResult], List[ctranslate2.translator.AsyncTranslationResult]]
Invoked with: <ctranslate2.translator.Translator object at 0x7f7f85cb0630>, [['__en__', '▁123', '▁**', 'M', 'IG', 'HT', 'Y', '▁MIN', 'ION', '▁SOL', '▁G', 'IV', 'EA', 'W', 'AY', '▁#', '15', '!', '**', '▁123', '▁@', 'e', 'very', 'one', '▁123', '123', '**', 'PR', 'IZ', 'E', ':', '▁$', '20', '▁SOL', '**', '▁123', '▁123', '123', '▁1.', '▁RE', 'ACT', '▁123', '▁to', '▁this', '▁G', 'IV', 'EA', 'W', 'AY', '▁P', 'OST', '123', '▁2.', '▁I', '▁will', '▁do', '▁a', '▁random', '▁sc', 'roll', '▁and', '▁choose', '▁1', '▁person', '!']]; kwargs: target_prefix=[['__hi__']], return_scores=False, beam_size=2, repetition_penalty=1.2, replace_unknowns=True