Even with two GTX780 GPU´s, the time this takes is insane. I need a higher vocab due to the high number of unknowns, but I don´t want to compromise too much on quality. What is your best suggestion?
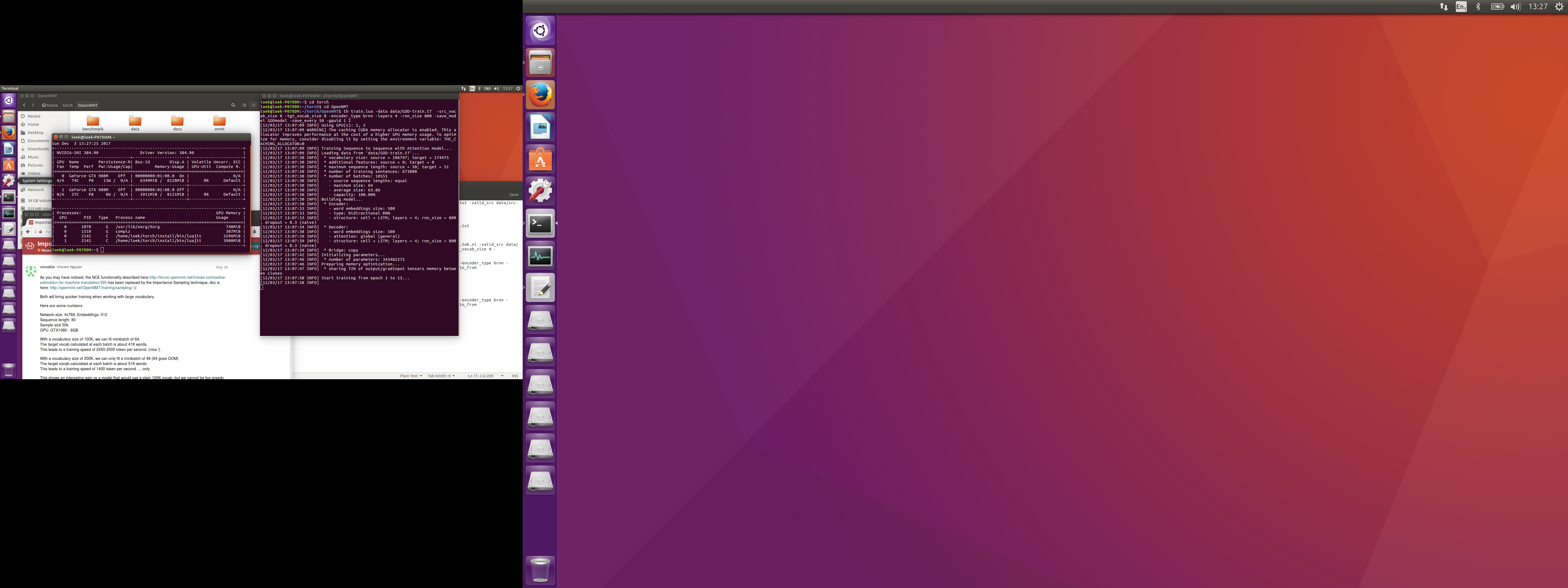
After 1,5 hours and 0 steps (not epochs!), I gave up. This is strange behavior on a pure Ubuntu system. In Windows VirtualBox I get faster results using the same parameters (without passthrough, which doesn work).
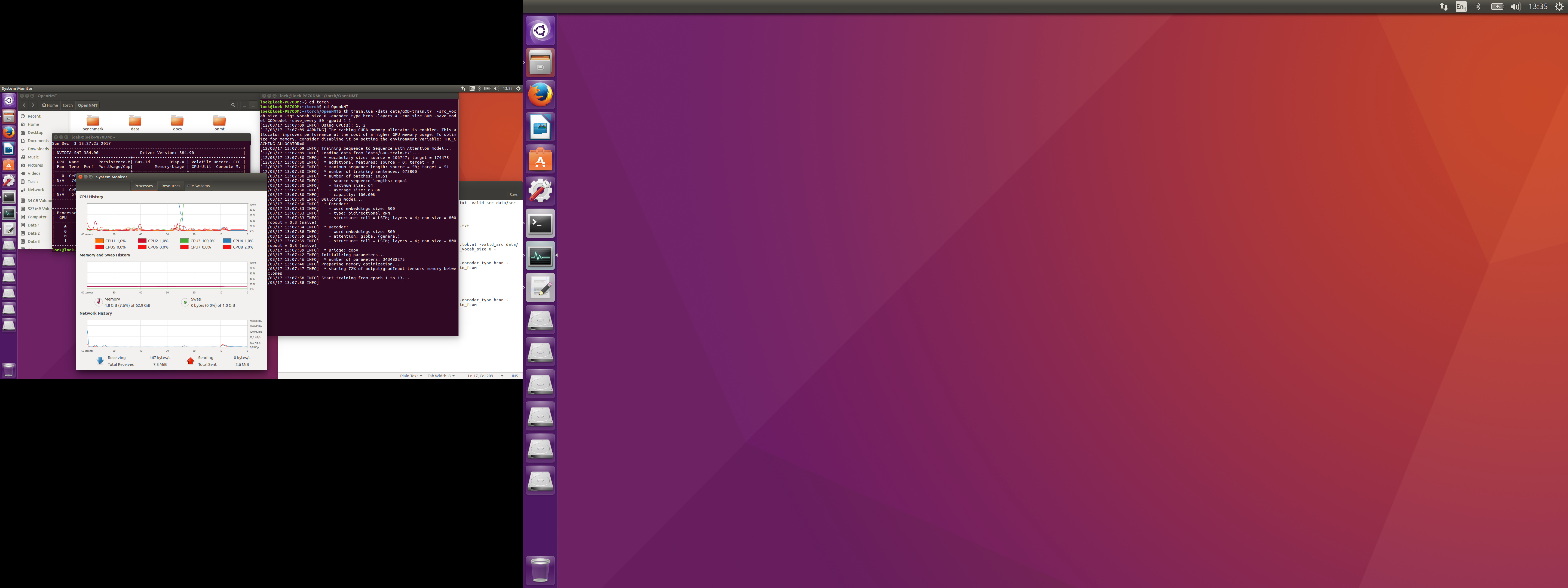
There´s indeed something very strange going on with the GPU´s: training without them is definitely faster. I lowered the layers to 4 and the size to 800; now the first step is written in 13 minutes or do.
All CPU cores are used.
Did you try with 1 GPU only?
For handling unknows, consider using BPE (see the documentation and search in the forum). It’s not a perfect solution either but it is better than giant word vocabularies.
1 Like
Thank you! I’ll try that as soon as I have finished the current model.
Hi Loek,
I have kept the vocab in the model down by using the -phrase_table option which allows me to incorporate a dictionary of some 350,000 tokens. Although it only allows single tokens you can get around this by using an underscore (e.g. systeembeheerder|||system_manager) which you can take out in post-processing.
1 Like
Thank you for the tip, Terence!