For the second time, OpenNMT participated to the efficiency task part of the WNGT 2020 workshop (previously WNMT 2018).
The goal of the task is to see how accuracy (BLEU) and efficiency (speed, memory usage, model size) can be combined. Since it is easy to understand that both are tightly connected, competitive systems must be on the Pareto frontier, where for a given accuracy there is no more efficient system.
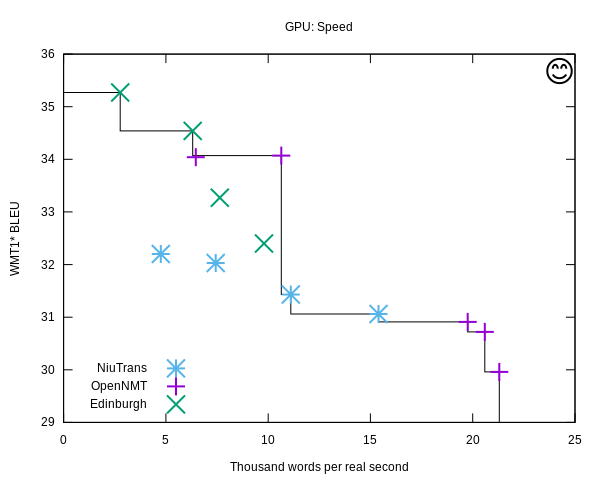
We submitted 4 systems that were evaluated both on CPU and GPU tracks. The systems were trained with OpenNMT-tf and decoded with CTranslate2. We used several techniques:
- Model distillation (also known as teacher-student training)
- Optimized greedy decoding and caching
- 8-bit quantization on CPU
- Memory-efficient parallelism at the file level on CPU
- Sorted and dynamic batches
- Target vocabulary reduction
These techniques are described in the system description.
The other systems in competition were:
- University of Edinburgh (using Marian NMT)
- NiuTrans
Results are presented in length in the overview paper, but here is a quick summary:
- Almost all submitted systems are on the Pareto frontier, with remarkable numbers for the memory footprint (disk and RAM) and Mw/USD.
- As in 2018, the smaller engines are reaching the highest throughput on both CPU and GPU.