I’ve been using openNMT-py for a while and it’s pretty straight forward. I have been trying to use opennmt-tf for few days, but I can’t seem to get any decent results or any results at all. I have tried Transformer/ Adam optimiser and SDG all this with and without sentencePiece and nothing avail.
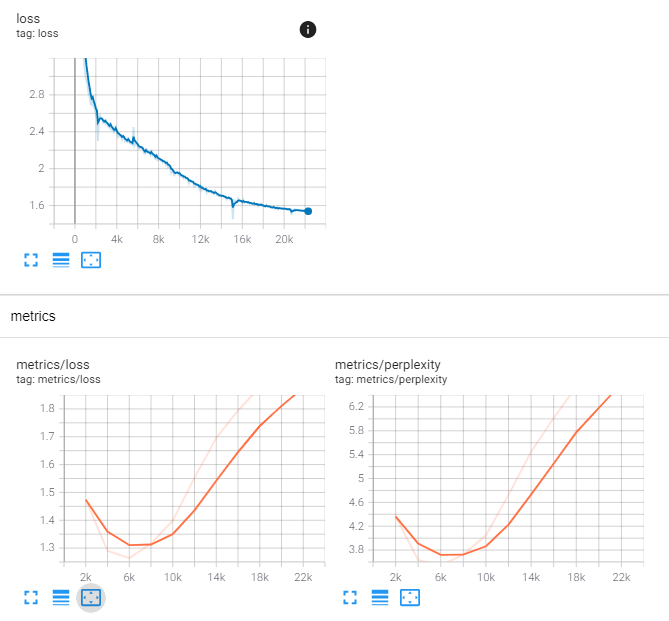
When i’m training I see the perplexity going down… (yet still really high … around 15 after 75000 steps with 128 batch size (exemples not tokens)…) and then when i try to infer i only get “unk” for every words.
I believe the problem is partially related to the fact i’m using sentencePiece. I have notice that in the loading of the training there are no embedding specified. This is something i have never define in opennmt-py… i’m not sure if i’m missing something here?
if anyone could point out what i’m doing wrong… it would be greatly appreciated.
here my params:
learning_rate = ‘0.0003’
batch_size = ‘128’
tokenizer_model_type = ‘bpe’
vocab_size = 20000
model_type = ‘NMTSmallV1’
sourceTrainFile = “gdrive/MyDrive/VGR/en-” + languageCode2 + “/src-train.txt”
targetTrainFile = “gdrive/MyDrive/VGR/en-” + languageCode2 + “/tgt-train.txt”vocabPath = “gdrive/MyDrive/VGR/en-” + languageCode2 + “/tf/vocab/”
sourceVocabPath = vocabPath + ‘SourceSP’
targetVocabPath = vocabPath + ‘TargetSP’
import osif not os.path.isdir(vocabPath):
os.makedirs(vocabPath)
!onmt-build-vocab --sentencepiece model_type=$tokenizer_model_type --size $vocab_size --save_vocab $sourceVocabPath $sourceTrainFile
!onmt-build-vocab --sentencepiece model_type=$tokenizer_model_type --size $vocab_size --save_vocab $targetVocabPath $targetTrainFile
Create the YAML configuration file (Basic)
config = ‘’’# en-’’’ + languageCode2 + ‘’’.yaml
Where the model will be saved
model_dir: gdrive/MyDrive/VGR/en-’’’ + languageCode2 + ‘’’/model/tf/’’’ + modelName + ‘’’
data:
train_features_file: gdrive/MyDrive/VGR/en-’’’ + languageCode2 + ‘’’/src-train.txt
train_labels_file: gdrive/MyDrive/VGR/en-’’’ + languageCode2 + ‘’’/tgt-train.txt
eval_features_file: gdrive/MyDrive/VGR/en-’’’ + languageCode2 + ‘’’/src-val.txt
eval_labels_file: gdrive/MyDrive/VGR/en-’’’ + languageCode2 + ‘’’/tgt-val.txt## Where the vocab(s) source_vocabulary: ''' + sourceVocabPath + '''.vocab target_vocabulary: ''' + targetVocabPath + '''.vocabparams:
learning_rate: ‘’’ + learning_rate + ‘’’
minimum_learning_rate: 0.0001
beam_width: 5
optimizer: SGD
optimizer_params:
clipnorm: 1train:
save_checkpoints_steps: ‘’’ + str(save_checkpoint_steps) + ‘’’
# (optional) How many checkpoints to keep on disk.
keep_checkpoint_max: 10
batch_size: ‘’’ + batch_size + ‘’’
effective_batch_size: 1eval:
steps: 2000
# Available scorers: bleu, rouge, wer, ter, prf
#scorers: bleu
#export_on_best: bleu
export_format: saved_modelinfer:
n_best: 3
with_scores: true ‘’’with open(“en-” + languageCode2 + “.yaml”, “w+”) as config_yaml:
config_yaml.write(config)!cat “en-”$languageCode2".yaml"
and at last the training line:
!onmt-main --model_type $model_type --config “en-”$languageCode2".yaml" --auto_config train --with_eval
and if it can be of any help… this was my last try by tweaking some parameters… (I tried to use as mutch as possible the default params) and in this run i get INF as perplexity which is worse than my previous tries.
2021-05-28 13:45:16.959955: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
2021-05-28 13:45:18.624459: I tensorflow/compiler/jit/xla_cpu_device.cc:41] Not creating XLA devices, tf_xla_enable_xla_devices not set
2021-05-28 13:45:18.625247: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcuda.so.1
2021-05-28 13:45:18.638273: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-05-28 13:45:18.638895: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1720] Found device 0 with properties:
pciBusID: 0000:00:04.0 name: Tesla P100-PCIE-16GB computeCapability: 6.0
coreClock: 1.3285GHz coreCount: 56 deviceMemorySize: 15.90GiB deviceMemoryBandwidth: 681.88GiB/s
2021-05-28 13:45:18.638930: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
2021-05-28 13:45:18.641610: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcublas.so.11
2021-05-28 13:45:18.641677: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcublasLt.so.11
2021-05-28 13:45:18.643239: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcufft.so.10
2021-05-28 13:45:18.643570: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcurand.so.10
2021-05-28 13:45:18.645293: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcusolver.so.10
2021-05-28 13:45:18.645883: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcusparse.so.11
2021-05-28 13:45:18.646048: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudnn.so.8
2021-05-28 13:45:18.646141: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-05-28 13:45:18.646721: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-05-28 13:45:18.647256: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1862] Adding visible gpu devices: 0
2021-05-28 13:45:18.689000: I main.py:318] Using OpenNMT-tf version 2.18.1
2021-05-28 13:45:18.689000: I main.py:318] Using model:
(model): NMTSmallV1(
(examples_inputter): SequenceToSequenceInputter(
(features_inputter): WordEmbedder()
(labels_inputter): WordEmbedder()
(inputters): ListWrapper(
(0): WordEmbedder()
(1): WordEmbedder()
)
)
(encoder): RNNEncoder(
(rnn): RNN(
(rnn): RNN(
(cell): StackedRNNCells(
(cells): ListWrapper(
(0): RNNCellWrapper(
(layer): LSTMCell(512)
(cell): LSTMCell(512)
)
(1): RNNCellWrapper(
(layer): LSTMCell(512)
(cell): LSTMCell(512)
)
)
)
)
(reducer): ConcatReducer()
)
)
(decoder): AttentionalRNNDecoder(
(bridge): CopyBridge()
(attention_mechanism): LuongAttention(
(memory_layer): Dense(512)
)
(cell): AttentionWrapper()
)
)2021-05-28 13:45:18.689959: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2021-05-28 13:45:18.690150: I tensorflow/compiler/jit/xla_gpu_device.cc:99] Not creating XLA devices, tf_xla_enable_xla_devices not set
2021-05-28 13:45:18.690316: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-05-28 13:45:18.690927: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1720] Found device 0 with properties:
pciBusID: 0000:00:04.0 name: Tesla P100-PCIE-16GB computeCapability: 6.0
coreClock: 1.3285GHz coreCount: 56 deviceMemorySize: 15.90GiB deviceMemoryBandwidth: 681.88GiB/s
2021-05-28 13:45:18.690966: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
2021-05-28 13:45:18.691015: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcublas.so.11
2021-05-28 13:45:18.691035: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcublasLt.so.11
2021-05-28 13:45:18.691054: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcufft.so.10
2021-05-28 13:45:18.691072: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcurand.so.10
2021-05-28 13:45:18.691090: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcusolver.so.10
2021-05-28 13:45:18.691107: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcusparse.so.11
2021-05-28 13:45:18.691125: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudnn.so.8
2021-05-28 13:45:18.691199: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-05-28 13:45:18.691756: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-05-28 13:45:18.692274: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1862] Adding visible gpu devices: 0
2021-05-28 13:45:18.692320: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
2021-05-28 13:45:19.368493: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1261] Device interconnect StreamExecutor with strength 1 edge matrix:
2021-05-28 13:45:19.368544: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1267] 0
2021-05-28 13:45:19.368556: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1280] 0: N
2021-05-28 13:45:19.368748: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-05-28 13:45:19.369399: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-05-28 13:45:19.369969: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-05-28 13:45:19.370469: W tensorflow/core/common_runtime/gpu/gpu_bfc_allocator.cc:39] Overriding allow_growth setting because the TF_FORCE_GPU_ALLOW_GROWTH environment variable is set. Original config value was 0.
2021-05-28 13:45:19.370516: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1406] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 14957 MB memory) → physical GPU (device: 0, name: Tesla P100-PCIE-16GB, pci bus id: 0000:00:04.0, compute capability: 6.0)
2021-05-28 13:45:19.374000: I main.py:326] Using parameters:
data:
eval_features_file: gdrive/MyDrive/VGR/en-fr/src-val.txt
eval_labels_file: gdrive/MyDrive/VGR/en-fr/tgt-val.txt
source_vocabulary: gdrive/MyDrive/VGR/en-fr/tf/vocab/SourceSP.vocab
target_vocabulary: gdrive/MyDrive/VGR/en-fr/tf/vocab/TargetSP.vocab
train_features_file: gdrive/MyDrive/VGR/en-fr/src-train.txt
train_labels_file: gdrive/MyDrive/VGR/en-fr/tgt-train.txt
eval:
batch_size: 32
batch_type: examples
export_format: saved_model
length_bucket_width: 5
steps: 2000
infer:
batch_size: 32
batch_type: examples
length_bucket_width: 5
n_best: 3
with_scores: true
model_dir: gdrive/MyDrive/VGR/en-fr/model/tf/OpenNMT-TF_fr_mtNMTSmallV1_tmtbpe_vs20000_lr0.0003_bs64
params:
average_loss_in_time: false
beam_width: 5
learning_rate: 0.0002
minimum_learning_rate: 0.0001
num_hypotheses: 3
optimizer: Adam
optimizer_params:
beta_1: 0.8
beta_2: 0.998
score:
batch_size: 64
batch_type: examples
length_bucket_width: 5
train:
batch_size: 64
batch_type: examples
effective_batch_size: 1
keep_checkpoint_max: 10
length_bucket_width: 1
max_step: 500000
maximum_features_length: 80
maximum_labels_length: 80
sample_buffer_size: -1
save_checkpoints_steps: 11000
save_summary_steps: 1002021-05-28 13:45:19.568000: I runner.py:242] Restored checkpoint gdrive/MyDrive/VGR/en-fr/model/tf/OpenNMT-TF_fr_mtNMTSmallV1_tmtbpe_vs20000_lr0.0003_bs64/ckpt-1
2021-05-28 13:45:19.573000: W deprecation.py:339] From /usr/local/lib/python3.7/dist-packages/tensorflow/python/summary/summary_iterator.py:31: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version.
Instructions for updating:
Use eager execution and:
tf.data.TFRecordDataset(path)
2021-05-28 13:45:21.000000: I main.py:326] Accumulate gradients of 1 iterations to reach effective batch size of 1
2021-05-28 13:45:21.051000: I dataset_ops.py:1996] Training on 200980 examples
2021-05-28 13:45:21.861929: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:116] None of the MLIR optimization passes are enabled (registered 2)
2021-05-28 13:45:21.863488: I tensorflow/core/platform/profile_utils/cpu_utils.cc:112] CPU Frequency: 2299995000 Hz
2021-05-28 13:45:43.440000: I control_flow.py:1218] Number of model parameters: 40973345
2021-05-28 13:45:44.237000: I control_flow.py:1218] Number of model weights: 18 (trainable = 18, non trainable = 0)
2021-05-28 13:46:02.804032: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcublas.so.11
2021-05-28 13:46:03.977579: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcublasLt.so.11
2021-05-28 13:46:23.289000: I runner.py:281] Step = 100 ; steps/s = 5.62, source words/s = 6808, target words/s = 8035 ; Learning rate = 0.000200 ; Loss = 1266.827637
2021-05-28 13:46:40.876000: I runner.py:281] Step = 200 ; steps/s = 5.69, source words/s = 6912, target words/s = 8142 ; Learning rate = 0.000200 ; Loss = 1018.049866
2021-05-28 13:46:58.843000: I runner.py:281] Step = 300 ; steps/s = 5.57, source words/s = 6830, target words/s = 8138 ; Learning rate = 0.000200 ; Loss = 1051.877197
2021-05-28 13:47:16.394000: I runner.py:281] Step = 400 ; steps/s = 5.70, source words/s = 6912, target words/s = 8123 ; Learning rate = 0.000200 ; Loss = 1035.163452
2021-05-28 13:47:34.256000: I runner.py:281] Step = 500 ; steps/s = 5.60, source words/s = 6834, target words/s = 8108 ; Learning rate = 0.000200 ; Loss = 910.203552
2021-05-28 13:47:51.854000: I runner.py:281] Step = 600 ; steps/s = 5.68, source words/s = 6953, target words/s = 8187 ; Learning rate = 0.000200 ; Loss = 1179.720825
2021-05-28 13:48:09.652000: I runner.py:281] Step = 700 ; steps/s = 5.62, source words/s = 6882, target words/s = 8143 ; Learning rate = 0.000200 ; Loss = 997.235657
2021-05-28 13:48:27.638000: I runner.py:281] Step = 800 ; steps/s = 5.56, source words/s = 6860, target words/s = 8135 ; Learning rate = 0.000200 ; Loss = 884.168701
2021-05-28 13:48:45.839000: I runner.py:281] Step = 900 ; steps/s = 5.50, source words/s = 6827, target words/s = 8123 ; Learning rate = 0.000200 ; Loss = 1198.313477
2021-05-28 13:49:02.966000: I runner.py:281] Step = 1000 ; steps/s = 5.84, source words/s = 6942, target words/s = 8144 ; Learning rate = 0.000200 ; Loss = 1476.122803
2021-05-28 13:49:21.061000: I runner.py:281] Step = 1100 ; steps/s = 5.53, source words/s = 6860, target words/s = 8109 ; Learning rate = 0.000200 ; Loss = 1158.275757
2021-05-28 13:49:39.017000: I runner.py:281] Step = 1200 ; steps/s = 5.57, source words/s = 6806, target words/s = 8070 ; Learning rate = 0.000200 ; Loss = 1226.175171
2021-05-28 13:49:56.660000: I runner.py:281] Step = 1300 ; steps/s = 5.67, source words/s = 6877, target words/s = 8115 ; Learning rate = 0.000200 ; Loss = 1260.031006
2021-05-28 13:50:14.503000: I runner.py:281] Step = 1400 ; steps/s = 5.61, source words/s = 6773, target words/s = 8005 ; Learning rate = 0.000200 ; Loss = 890.193542
2021-05-28 13:50:32.387000: I runner.py:281] Step = 1500 ; steps/s = 5.59, source words/s = 6852, target words/s = 8144 ; Learning rate = 0.000200 ; Loss = 811.623596
2021-05-28 13:50:50.466000: I runner.py:281] Step = 1600 ; steps/s = 5.53, source words/s = 6818, target words/s = 8061 ; Learning rate = 0.000200 ; Loss = 1026.326904
2021-05-28 13:51:07.724000: I runner.py:281] Step = 1700 ; steps/s = 5.80, source words/s = 6953, target words/s = 8159 ; Learning rate = 0.000200 ; Loss = 715.587097
2021-05-28 13:51:25.901000: I runner.py:281] Step = 1800 ; steps/s = 5.50, source words/s = 6827, target words/s = 8106 ; Learning rate = 0.000200 ; Loss = 952.115234
2021-05-28 13:51:43.502000: I runner.py:281] Step = 1900 ; steps/s = 5.68, source words/s = 6910, target words/s = 8171 ; Learning rate = 0.000200 ; Loss = 926.592529
2021-05-28 13:52:01.011000: I runner.py:281] Step = 2000 ; steps/s = 5.71, source words/s = 6859, target words/s = 8098 ; Learning rate = 0.000200 ; Loss = 791.998291
2021-05-28 13:52:01.013000: I training.py:202] Running evaluation for step 2000
2021-05-28 13:57:09.319000: I training.py:202] Evaluation result for step 2000: loss = 514.641296 ; perplexity = inf
2021-05-28 13:57:26.899000: I runner.py:281] Step = 2100 ; steps/s = 5.69, source words/s = 6885, target words/s = 8091 ; Learning rate = 0.000200 ; Loss = 839.368347
2021-05-28 13:57:44.811000: I runner.py:281] Step = 2200 ; steps/s = 5.58, source words/s = 6889, target words/s = 8177 ; Learning rate = 0.000200 ; Loss = 908.090759
2021-05-28 13:58:02.761000: I runner.py:281] Step = 2300 ; steps/s = 5.57, source words/s = 6878, target words/s = 8155 ; Learning rate = 0.000200 ; Loss = 1177.083618
2021-05-28 13:58:20.328000: I runner.py:281] Step = 2400 ; steps/s = 5.69, source words/s = 6858, target words/s = 8075 ; Learning rate = 0.000200 ; Loss = 1329.044312
2021-05-28 13:58:38.186000: I runner.py:281] Step = 2500 ; steps/s = 5.60, source words/s = 6852, target words/s = 8128 ; Learning rate = 0.000200 ; Loss = 1493.157349
2021-05-28 13:58:55.756000: I runner.py:281] Step = 2600 ; steps/s = 5.69, source words/s = 6886, target words/s = 8121 ; Learning rate = 0.000200 ; Loss = 1473.173584