Hi there,
I have domain adapted OpenNMT-tf Transformer models for different language pairs. I will present here an example for german to english. First, I trained a general model with the following Sentencepiece models ( I specified an input sentence size because the training data was too large to be handled):
Sentencepiece models
onmt-build-vocab --sentencepiece character_coverage=1.0 input_sentence_size=10000000 shuffle_input_sentence=false --size $vocab_size --save_vocab ./model_32000/sentencepiece_32000.de-en.de train.de-en.de
onmt-build-vocab --sentencepiece character_coverage=1.0 input_sentence_size=10000000 shuffle_input_sentence=false --size $vocab_size --save_vocab ./model_32000/sentencepiece_32000.de-en.en train.de-en.en
Then tokenized the different sets of the general domain and worked with it.
Once I had my final general model, as suggested in OpenNMT-tf procedure for fine-tuning/domain adaptation? I did not update the vocabulary for the domain adaptation. I just tokenized as follows the in-domain training data:
Tokenization of in-domain data
onmt-tokenize-text --tokenizer_config ./model_32000/tok_config.32000.de-en.de.yml < ./train.adapt.de-en.de> ./model_32000/train.adapt.de-en.de.32000.token
onmt-tokenize-text --tokenizer_config ./model_32000/tok_config.32000.de-en.de.yml < ./train.adapt.de-en.de> ./model_32000/train.adapt.de-en.de.32000.token
where tok_config.32000.de-en.de is:
type: OpenNMTTokenizer params: mode: none sp_model_path: ./model_$3/sentencepiece_32000.de-en.de.model
Same procedure for the other in-domain sets used dev.adapt.de-en.de , dev.adapt.de-en.en, test.adapt.de-en.de and test.adapt.de-en.en.
Tracking adaptation
I launch training starting from my general model checkpoint and everything goes as expected. I regularly save predictions for the in-domain and for the general test data to observe the adaptation classic behavior ( loss of quality for the general domain and gain of quality in the in-domain). I measure the BLEU for each tokenized and detokenized prediction as follows:
General_tok_bleu=$(perl ./mosesdecoder/scripts/generic/multi-bleu.perl ./model_32000/test.de-en.en.32000.token < $eval_folders_path/eval_test_tok_gen/predictions.txt.$i | cut -c7-12)
General_detok_bleu=$(perl ./mosesdecoder/scripts/generic/multi-bleu-detok.perl ./test.de-en.en < $eval_folders_path/eval_test_gen/predictions.txt.$i | cut -c7-11)
Adapted_tok_bleu=$(perl ./mosesdecoder/scripts/generic/multi-bleu.perl ./model_32000/test.de-en.en.32000.token < $eval_folders_path/eval_test_tok_adapt/predictions.txt.$i | cut -c7-12)
Adapted_detok_bleu=$( perl ./mosesdecoder/scripts/generic/multi-bleu-detok.perl ./test.adapt.de-en.en < $eval_folders_path/eval_test_adapt/predictions.txt.$i | cut -c7-11)
And visualize it as follows:
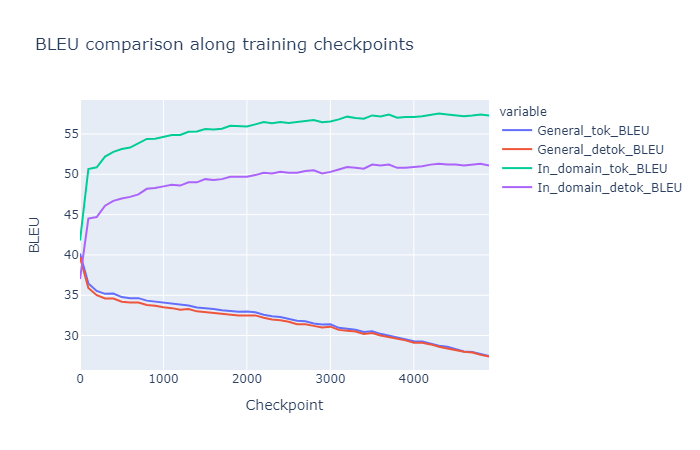
So the BLEU evolution makes sense.
What we are wondering is why there is such a big gap between the tokenized and detokenized Bleu score for the in-domain data when for general domain it is almost the same value?
The only clue I have is that it must come from the vocabulary which is created based on the general domain. Instead of tokenizing the general domain as subwords with our sentencepiece model it looks more like it is doing a word tokenization due to the large presence of words in the vocabulary ( I wanted to put a histogram comparing the frequency of words, subwords and characters in my vocab but I am new  )
)
Number of Full words: 17194
Number of Character words: 5496
Number of Subword words: 4706
So the general domain explanation makes sense because it is almost equivalent to calculate the BLEU for the tokenized and the detokenized predictions. However, I am not very sure how to explain clearly such a big gap in the in-domain data even if I know that it comes from the non-update of the vocabulary. If I had updated the vocabulary with the in-domain data I would get the opposite behaviour ( big gap for general BLEUs and almost equal BLEUs for in-domain data).
Thanks in advance. Do not hesitate to ask me for more details if required.
Best regards,
Jon