I’m normally able to train models fine but trying to train a Polish model with 55,743,802 lines of data I get this error I can’t make much sense of:
[2021-03-17 03:43:22,204 WARNING] Corpus corpus_1's weight should be given. We default it to 1 for you.
[2021-03-17 03:43:22,204 INFO] Parsed 2 corpora from -data.
[2021-03-17 03:43:22,204 INFO] Get special vocabs from Transforms: {'src': set(), 'tgt': set()}.
[2021-03-17 03:43:22,204 INFO] Loading vocab from text file...
[2021-03-17 03:43:22,204 INFO] Loading src vocabulary from opennmt_data/openmt.vocab
[2021-03-17 03:43:22,309 INFO] Loaded src vocab has 37600 tokens.
Traceback (most recent call last):
File "/home/argosopentech/.local/bin/onmt_train", line 11, in <module>
load_entry_point('OpenNMT-py', 'console_scripts', 'onmt_train')()
File "/home/argosopentech/OpenNMT-py/onmt/bin/train.py", line 169, in main
train(opt)
File "/home/argosopentech/OpenNMT-py/onmt/bin/train.py", line 103, in train
checkpoint, fields, transforms_cls = _init_train(opt)
File "/home/argosopentech/OpenNMT-py/onmt/bin/train.py", line 80, in _init_train
fields, transforms_cls = prepare_fields_transforms(opt)
File "/home/argosopentech/OpenNMT-py/onmt/bin/train.py", line 33, in prepare_fields_transforms
fields = build_dynamic_fields(
File "/home/argosopentech/OpenNMT-py/onmt/inputters/fields.py", line 32, in build_dynamic_fields
_src_vocab, _src_vocab_size = _load_vocab(
File "/home/argosopentech/OpenNMT-py/onmt/inputters/inputter.py", line 309, in _load_vocab
for token, count in vocab:
ValueError: not enough values to unpack (expected 2, got 1)
Thanks, that does seem to be the issue but I’m not sure what the root cause is. My sentencepiece.vocab file seems fine even though I can’t easily check every line:
▁Dia -8.0681
▁who -8.06953
▁high -8.07295
ra -8.07622
ka -8.08309
▁He -8.08323
▁New -8.08698
▁So -8.08781
ru -8.08827
▁18 -8.09131
Y -8.09186
▁# -8.09324
▁hari -8.09674
▁9 -8.09719
el -8.10969
ro -8.11083
The error message indicates that one or more of your lines are missing either the token or the frequency. It should be fairly easy to find these lines with grep or a similar tool.
For anyone with the same problem @panosk is right it’s a bad line in the sentencepiece.vocab file. It seems to only happen only on large datasets so I’m guessing this is a SentencePiece issue but I’m trying to figure it out.
Here’s the script for finding bad lines:
VOCAB_FILE = 'sentencepiece.vocab'
lines = open(VOCAB_FILE).readlines()
for i, line in enumerate(lines):
print(line)
split = line.split()
assert(len(split) == 2)
assert(split[1][-1].isdigit())
print(f'Checked line {i}/{len(lines)}')
And the output:
Checked line 31877/32000
𐍅 -17.1575
Checked line 31878/32000
⟨ -17.1576
Checked line 31879/32000
-17.1576
Traceback (most recent call last):
File "search_for_bad_data.py", line 6, in <module>
assert(len(split) == 2)
AssertionError
Normally lines are <character><tab><number>, this line (near the end of the file) is just <tab><number>.
Actually looking at this again I think the token may be <carriage return (ascii 13)><new line (ascii 10)>. It may be that you need enough data for these two tokens to get tokenized together. When it happens though maybe onmt reads them as separate lines?
Hello, @argosopentech . I am trying to use OpenNMT to train a multilingual NMT model. I also use sentencepiece to get the vocab file. But I always get a OOM error using large data like 90 million sentence. Do you ever meet this issue before?
In addition to the other replies you received from colleagues, please note that currently the default value of SentencePiece’s --input_sentence_size is 0, i.e. the whole corpus. If you make it something like 10000000, these 10 million sentences will be sampled from the corpus, and they are enough for creating a good SentencePiece model.
There are also a few notes here:
The default SentencePiece value for --vocab_size is 8000. You can go for a higher value like between 30000 and 50000, and up to 100000 for a big corpus. Still, note that smaller values will encourage the model to make more splits on words, which might be better in the case of a multilingual model if the languages share the alphabet.
After you segment your source and target files with the generated SentencePiece models, you must build vocab using OpenNMT-py to generate vocab files compatible with it.
When you start training with OpenNMT-py, you must set src_vocab_size and tgt_vocab_size exactly as you set the --vocab_size for SentencePiece. The default is 50000, which is usually good.
If you do not set it, it will take the default 50000, which will still work. However, it is better to be compatible with that you set in SentencePiece.
Thank you for your reply. I set the --input_sentence_size to 70000000 as my training data is a multilingual corpus of about 1.3 billion sentences. I think more data is needed to learn good vocab, but there is always an OOM error. However, there are a lot of multilingual research papers using sentencepiece to learn the join vocab, so I think it should be able to solve the problem of large corpus training. I am still finding a way to solve this OOM error.
You will need hundreds of GB of RAM to train a model on that much data, like I said EC2 instances are very affordable. Make sure you also set --shuffle_input_sentence=true to get a complete distribution of your data.
The point of adding swap space is you can use your disk space as overflow RAM on Linux. It’s slower but I find it works well to train large SentencePiece models.
sourceSP = spm.SentencePieceProcessor(model_file=sourceVocabPath + '.model')
print([[sourceSP.id_to_piece(id), id] for id in range(sourceSP.get_piece_size())])
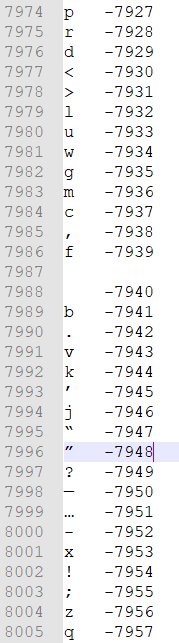
I could clearly see the culprit: ...7974], ['\r', 7975], ['b', 7976], ['.', 7977], ['v', 7978], ['k', 7979], ['’', 7980], ['j', 7981], ['“', 7982], ['”', 7983], ...
[’\r’, 7975] = carriage return.
The vocab file generated by sentencePiece confirm it. Since it’s jumping a line at the exact spot where that char would be in the file.
Well, turned out that removing ‘\r’ in my preprocess didn’t solve the issue.
After some investigations. It seems that when my training files get created, there is both ‘\r\n’ on every line (since I’m in windows, in unix it would have been ‘\n’).
Since SentencePiece is consuming those file directly and split on ‘\n’, all ‘\r’ are interpreted has single char and create a jump line in the resulting vocab file. Most people don’t get this issue since they use the default parameter for “normalization_rule_name” in sentencePiece which remove by default all the ‘\r’. In my case, I need to set it at “normalization_rule_name =identity” since I want my pretokenization to stay as is.
Now, I’m playing around with the parameters of the function I’m using to generate my txt files, so that they only generate ‘\n’. I will keep you posted if I find the solution…
I finally succeed, but the solution is not the most elegant I seen.
I’m personally using dataframes.to_csv to generate training/testing/validation my files. The way to force to use ‘\n’ and prevent windows to add ‘\r’ is to do what is mentioned here: