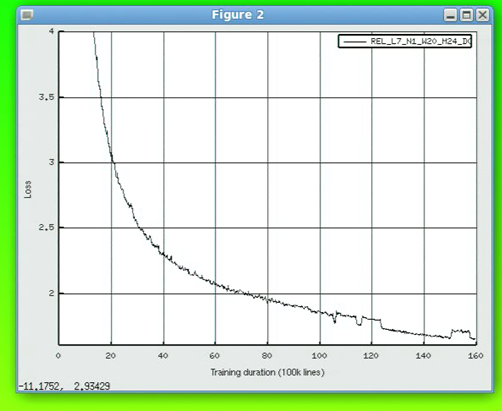
I am seeing some strange behavior during training. I train in many small (~50k sentence) files, running a validation evaluation after a single pass through each file. I use a transformer with relative position. My source inputter is a SequenceRecordInputter, and my target is WordEmbedder. The systems train for days, slowly appearing to converge.
I occasionally had out-of-memory problems (but not on the three cases I’ll show below). I changed the training batch size from the default (about 3000) to 111, and the training runs picked up the batch_size reduction in the configuration yml, as the bash script cycled through training files. Unexpectedly, the validation score went up 1-3 BLEU points, and the Loss dropped dramatically.
I returned to the large batch_size, and validation scores got worse. I repeated this and got another valley in Loss (or peak in BLEU). For each of the nine models I was training!
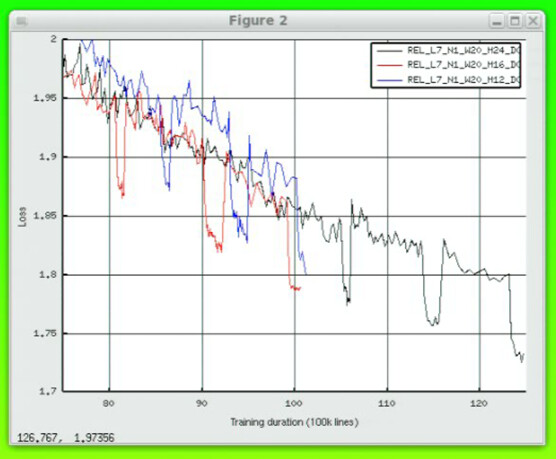
The figure below has validation loss curves for three models. In each curve you can see the three drops in Loss caused by three decreases in batch size.
I don’t understand this behavior. With any nonconvex optimization there’s the chance of local optima and batch size dependence, but I would expect that mostly to affect the validation slope. In particular, the dramatic, repeated drop in quality when I increased batch_size is a mystery to me.
Have others seen or have an explanation for this behavior? Is it perhaps related to a bug in OpenNMT-tf 2.18.1 (“Support” could well be a better category than “Research”)?
This config.yml is for the small training batch size (with good performance). For the large training batch size (with poor performance), I remove the batch_size line from the “train:” section.
The odd behavior persists now, with a week more training. I caused another mesa in the loss curve by temporarily increasing batch_size:
There is a corresponding valley in the validation BLEU score.
As you set the batch size to 111, I’m not sure you considered this value to be the number of tokens. I suggest overriding all batch related parameters to make sure they are consistent. You can consider disabling gradient accumulation for now (set effective_batch_size: null).
If I understand this correctly, you have multiple training files. I think this can explain the issue if the data is not properly shuffled. What happens if you concatenate all training data?
I think batch_type may be my main problem. I’ll try setting it to examples and see what happens.
I’ll also experiment with disabling gradient accumulation.
For each training run, I randomly draw 50 thousand lines from a 6 million line training set. So the data are shuffled. I believe my SequenceRecord files are too large for me to give all the training data at once.