EDIT 19/03/2023: I rescored with the proper source sequence.
Before: src: tokens + “ LangTok” (based on HuggingFace implementation)
Now: src: “ LangTok” + tokens (based on the actual paper Page 48)
Last July 2022, Meta released “No Language Left Behind”, a paper with opensource models that support 200 languages. No matter what follows it is a great paper and gives a lot of possibilities to integrate low resource languages.
They released various models:
The huge one, 54 billion parameters, a mixture of experts (128 experts).
A dense Transformer 3.3 billion parameters.
A dense Transformer 1.3 billion parameters.
A distilled Transformer 1.3 billion parameters.
A distilled Transformer 600M parameters.
I wanted to assess the performance of these models with regards to their claim (breakthrough … +44% improvement… SOTA…).
I focused on the table 36 page 109 on which they calculate averages and measure some performance versus previous work or SOTA.
First of all, I only looked at WMT (table 36a) because IWSLT (table 36b) is based on a completely different task with far less data in the datasets.
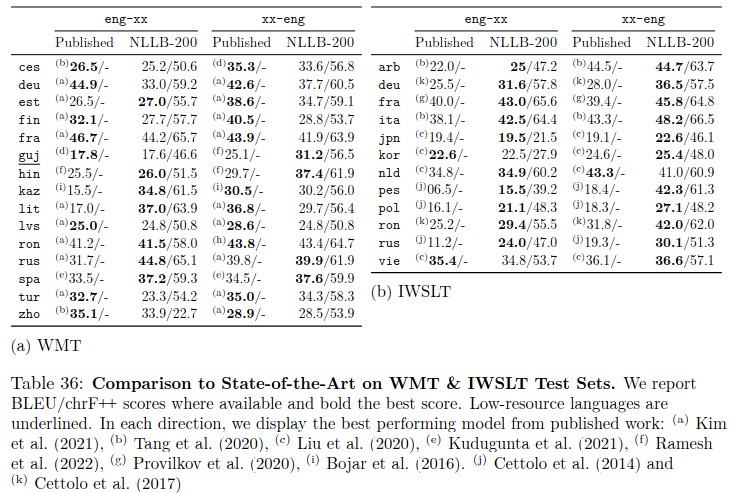
It is unclear whether comparison are versus “similar work” on multilingual research or on absolute SOTA. So I wanted to compare scores versus real SOTA.
Let’s start with the ugly and the bad.
Six lines of the table 36a are based on WMT19. Starting in 2019, WMT released specific directional test sets which means that the RU-EN test set is NOT the reversed EN-RU test set. Unfortunately they messed up and used the wrong test set in the EN-XX directions. Anyway, I recomputed scores with the 3.3B model (when they obviously report everywhere scores with the 54B model).
| Lang from / to Eng | 3.3B | Paper | SOTA | 3.3B | Paper | SOTA | |
|---|---|---|---|---|---|---|---|
| FI | 25.1 | 27.7 | 27.4 | 28.0 | 28.8 | 33.0 | |
| GU | 27.1 | 17.6 | 28.2 | 30.9 | 31.2 | 38.4 | |
| KK | 12.0 | 34.8 | 16.9 | 29.5 | 30.2 | 32.0 | |
| LT | 16.9 | 37.0 | 20.1 | 30.6 | 29.7 | 36.3 | |
| RU | 34.6 | 44.8 | 36.3 | 39.1 | 39.9 | 45.3 | |
| ZH | 25.6 | 33.9 | 42.4 | 25.9 | 28.5 | 42.2 |
As I said, the “from ENG” scores of the second column are wrong. Even though it was misleading for some languages, it was quite obvious for KK/LT as well as Russian (by the way SOTA 36.3 is the Fairseq paper from WMT19. It would have been weird to beat it with a multilingual model).
For “into ENG” scores from the paper are slightly higher than the 3.3B since they reported figures with the huge 54B model. The SOTA scores are taken from the http://wmt.ufal.cz/ website that gathers all WMT history.
I do not recall exactly where but I read somewhere that the output of NLLB for Chinese was quite bad. There might be some tokenization issues but I fear that the model is not really good with this alphabet.
EDIT: NLLB vocabulary missing common Chinese character/tokens · Issue #4560 · facebookresearch/fairseq · GitHub could be an explanation.
Now the good and the really good.
Let’s have a look at the WMT18 languages.
| Lang from / to Eng | 3.3B | Paper | SOTA | 3.3B | Paper | SOTA | |
|---|---|---|---|---|---|---|---|
| CS | 23.1 | 25.2 | 26.0 | 33.2 | 35.3 | 33.9 | |
| ET | 23.6 | 27.0 | 25.2 | 33.2 | 34.7 | 30.9 | |
| TR | 21.1 | 23.3 | 20.0 | 33.3 | 34.3 | 26.9 |
Again the column “Paper” reports scores with the huge model and scores are consistently higher than what I computed with the 3.3B model. We can observe that scores are close to or better than SOTA from WMT18.
Now what about very high resource languages (DE, FR, ES) ?
English are French are run with WMT14 test sets whereas Spanish is done on WMT13.
English to German WMT14:
As a reminder this is the base for the original Transformer publication (BLEU 28.4 for the big model). I ran the test sets with the various NLLB-200 models:
3.3B model: 30.1
1.3B distilled: 29.6
1.3B model: 28.5
600M model: 26.9
Paper reports 33.0 which means there is a major improvement with the very large 54B 128MOE model.
However this remains under the 33.8 of the Fairseq WMT18 bilingual model. (https://arxiv.org/pdf/1808.09381.pdf)
For the sake of comparison, I trained a small (4 layers 512) 42M parameters with selected crawled data and back translation which scores at 30.0 BLEU on WMT14 (> the 3.3B model …)
German to English:
Paper: 37.7
3.3B: 36.5
English to French:
Paper: 44.2
3.3B: 43.2
French to English:
Paper: 41.9
3.3B: 41.2
English to Spanish (WMT13):
Paper: 37.2
3.3B: 36.6
Spanish to English:
Paper: 37.6
3.3B: 36.6
Overall the results for those 3 high resource languages are very good but we can see that scores decrease significantly when the size of the model decreases.
We will release OpenNMT-py checkpoints of NLLB-200 and if some users are willing to test finetuning this model, it might be interesting to see the results.
Enjoy.
V.
