Hello,
It’s been a while, but I have some news.
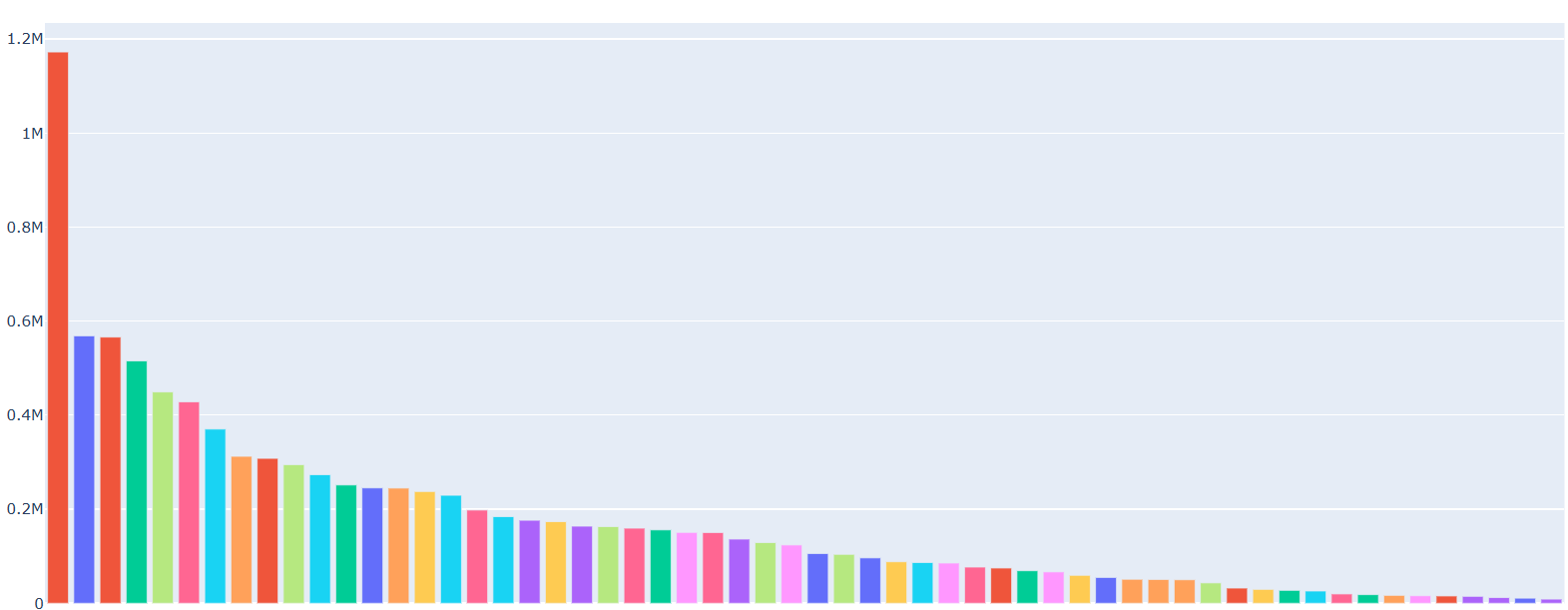
So I managed to create a multi lang model that support (n*(n-1)) language pairs. In my case, n = 61. So my model support 3660 languages pairs.
My data corpus are between medium/small/tiny.
My Original data source is English and all other languages are translated from the English. So they all share the same source.
I have generated all possible sentence alignments between all the various languages pairs, and I have assigned the weights in a way that all pairs are in equal quantity during training.
After getting the results, I picked 6 languages pairs that had (the most, the lowest and in between). For each one of them, I trained a single model with the exact same data that was used in the multi langs model (same training/validation/testing files).
Note: the multi langs model was a Big Transformer and the single models are Transformer.
I used Sentence Piece with about the same amount of tokens as the model Bert mutli langs.
Results:
The multi model was really good for all pairs that I tried.
Upon validation, the language pairs with the most data were performing about 6 Bleu score points lower than the single model I trained. The middle ones were on pare and the ones with the least data were performing sometimes 20 points above single model Bleu Score.
My current conclusion is that I should try to give weight proportional to the number of sentences for each pair. I should also reduce the number of token in my sentence piece configuration as I noticed that most word were tokenized has a single word. But I want the tokenization to cross tokenize the languages so that the model can build on top of those similarities.
I will keep updating has I work my way. If anyone has suggestion make sure to let me know!
Annexe:
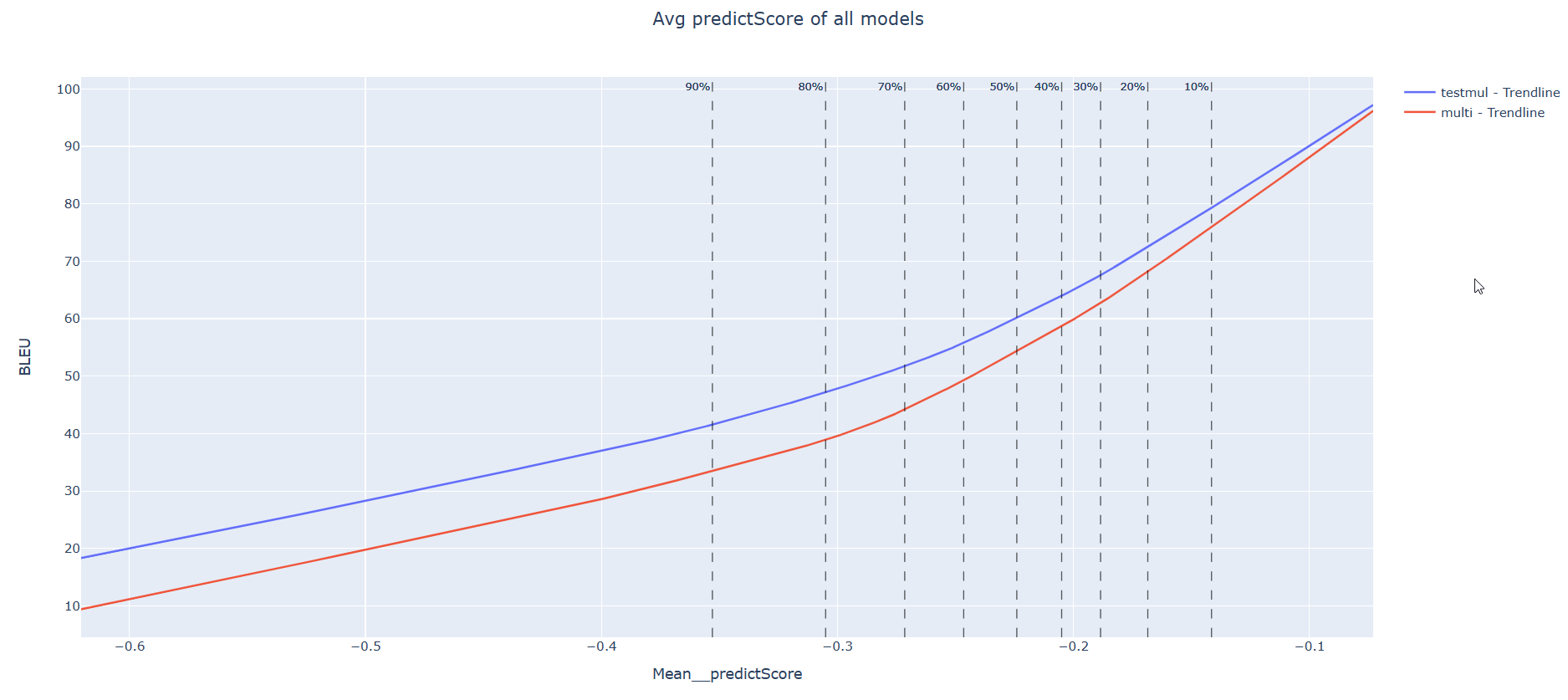
This graph shows my language pair with the most data BLEU score (multi vs single model) About 2000 sentences were used to test.
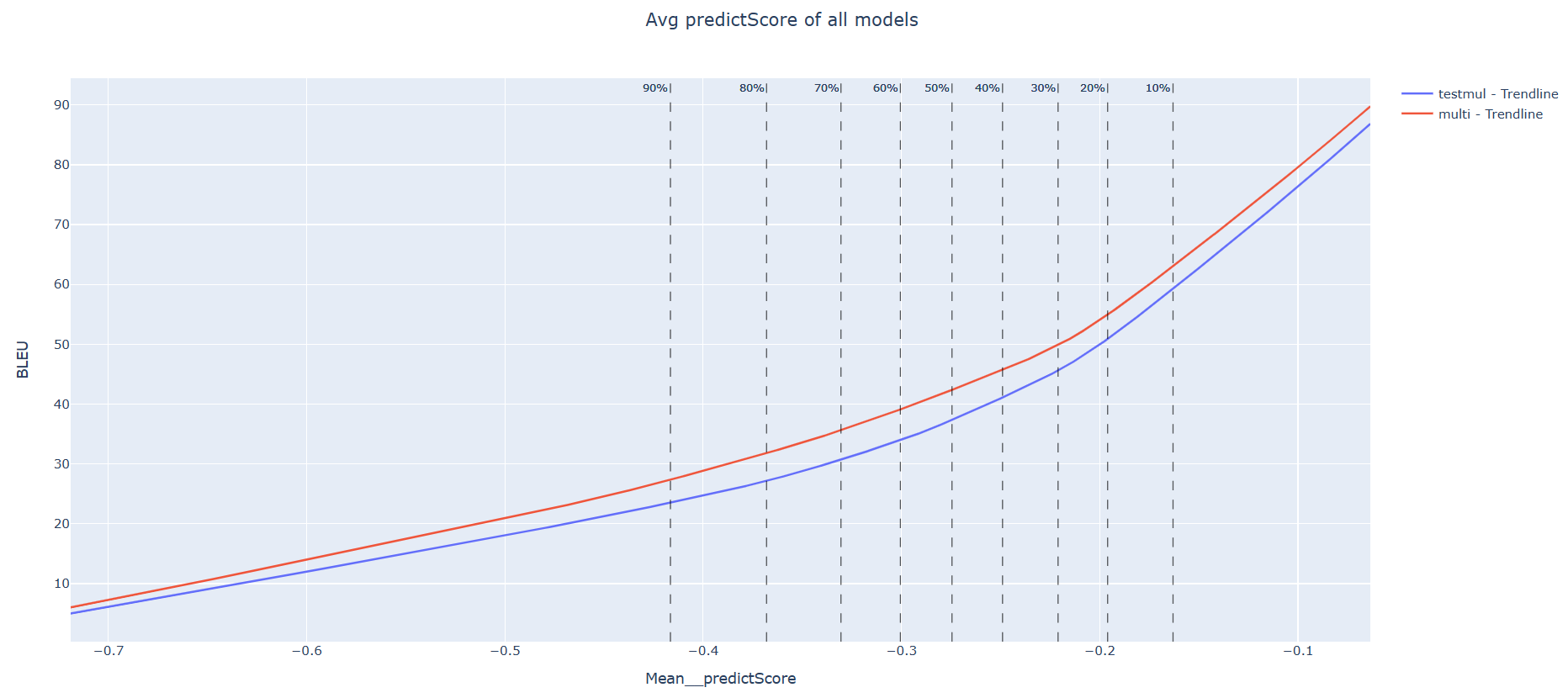
This graph shows a mid-size language pair (multi vs single model) About 2000 sentences were used to test.
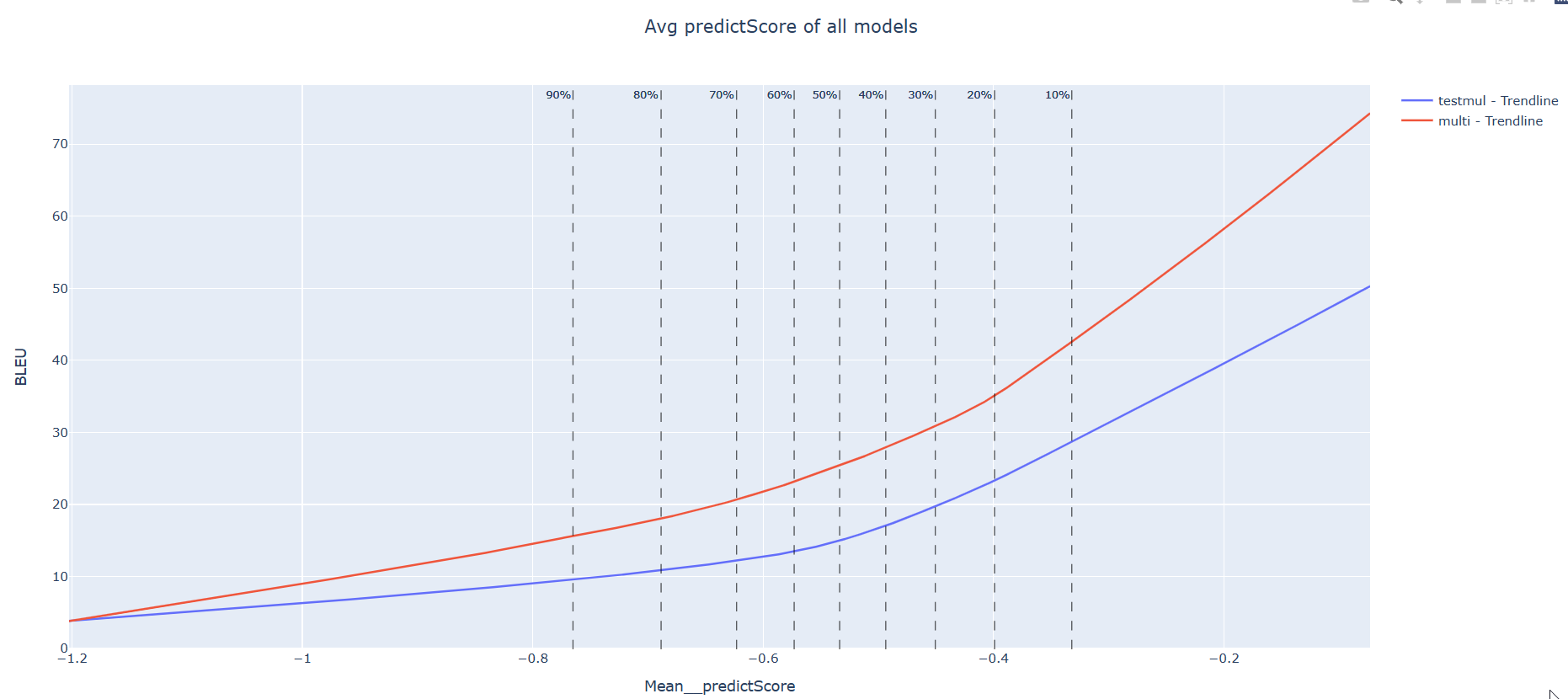
This graph shows one of the smallest language pair (multi vs single model) About 2000 sentences were used to test.