Neural machine translation with attention | TensorFlow Core
Can 30000 Sentences make an Excellent Translation Model. Many Languages with low resources do not have many sentences.
Neural machine translation with attention | TensorFlow Core
Can 30000 Sentences make an Excellent Translation Model. Many Languages with low resources do not have many sentences.
I guess most of the people would say it’s no good at all. I will say it’s depend on what your trying to translate and what’s your goal.
I’m a begginner myself, but I was able to get 70% accuracy to translate new data with only 50k sentences (steps). Because my data is text from a person talking and it’s always the same person talking. So the words are mostly the same and the context is always the same.
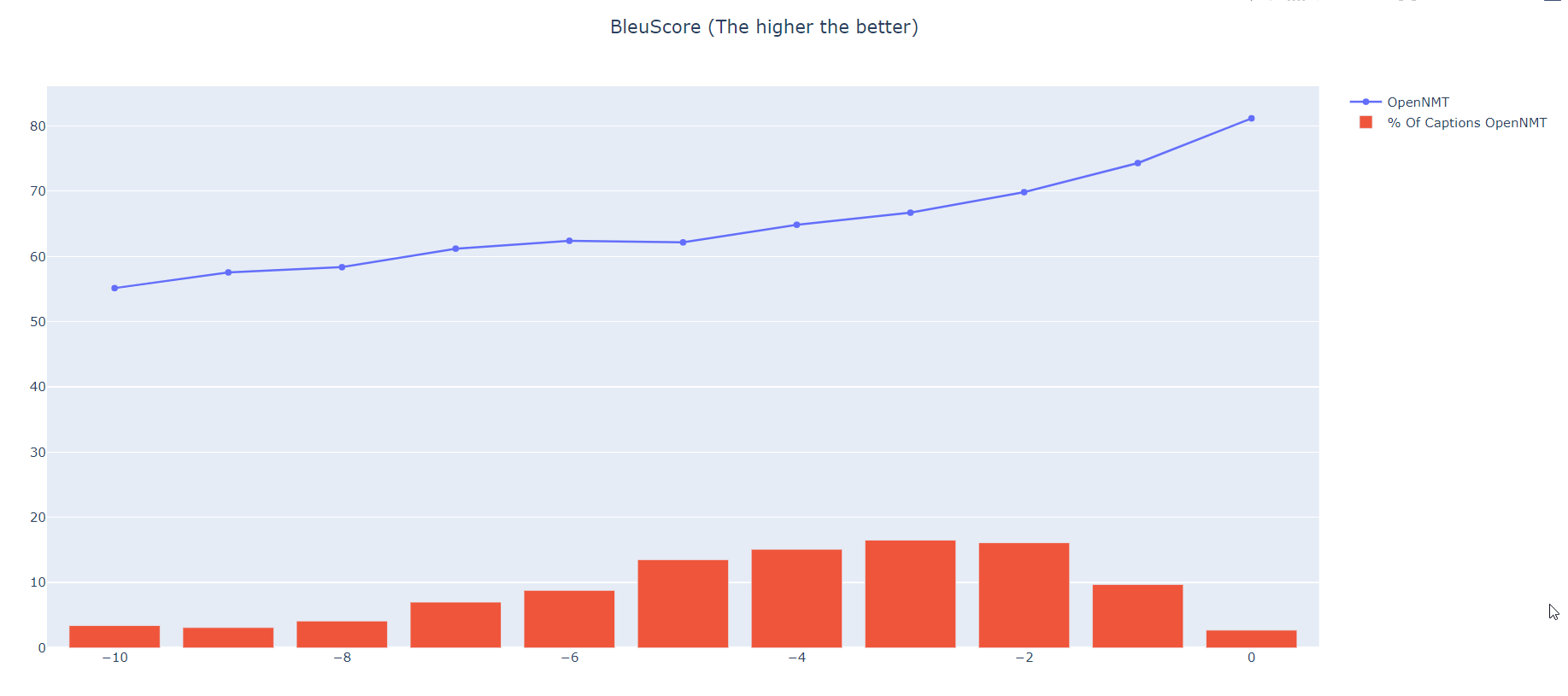
One thing you can do, if you’r using openNMT-py, is to keep only the translated sentences which has a predict score < -3 (or figure out the threshold that meets your sweet spot) and the rest you drop it. So you could meaby get 20% of what ever you are translating with a good translation draft.
here an exemple of my BlueScore for English to Lingala with only 50k sentences (steps). The red bars represent the % of the test set which is 2125 sentences (unseen by the model)