Hello,
I’m having issue running opennmt in Colab. It used to be working, but for some reasons that I have no clue, it’s not anymore.
I have tried to update the version of my libraries (tenserflow and ctranslate2 to 2.7.0), but nothing avail.
here is the logs i’m getting from running !omnt-main:
2021-11-12 02:50:00.698416: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-11-12 02:50:00.706615: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-11-12 02:50:00.707209: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-11-12 02:50:00.832000: I main.py:304] Using OpenNMT-tf version 2.22.0
2021-11-12 02:50:00.832000: I main.py:304] Using model:
(model): TransformerBase(
(examples_inputter): SequenceToSequenceInputter(
(features_inputter): WordEmbedder()
(labels_inputter): WordEmbedder()
(inputters): ListWrapper(
(0): WordEmbedder()
(1): WordEmbedder()
)
)
(encoder): SelfAttentionEncoder(
(position_encoder): SinusoidalPositionEncoder(
(reducer): SumReducer()
)
(layer_norm): LayerNorm()
(layers): ListWrapper(
(0): SelfAttentionEncoderLayer(
(self_attention): TransformerLayerWrapper(
(layer): MultiHeadAttention(
(linear_queries): Dense(512)
(linear_keys): Dense(512)
(linear_values): Dense(512)
(linear_output): Dense(512)
)
(input_layer_norm): LayerNorm()
)
(ffn): TransformerLayerWrapper(
(layer): FeedForwardNetwork(
(inner): Dense(2048)
(outer): Dense(512)
)
(input_layer_norm): LayerNorm()
)
)
(1): SelfAttentionEncoderLayer(
(self_attention): TransformerLayerWrapper(
(layer): MultiHeadAttention(
(linear_queries): Dense(512)
(linear_keys): Dense(512)
(linear_values): Dense(512)
(linear_output): Dense(512)
)
(input_layer_norm): LayerNorm()
)
(ffn): TransformerLayerWrapper(
(layer): FeedForwardNetwork(
(inner): Dense(2048)
(outer): Dense(512)
)
(input_layer_norm): LayerNorm()
)
)
(2): SelfAttentionEncoderLayer(
(self_attention): TransformerLayerWrapper(
(layer): MultiHeadAttention(
(linear_queries): Dense(512)
(linear_keys): Dense(512)
(linear_values): Dense(512)
(linear_output): Dense(512)
)
(input_layer_norm): LayerNorm()
)
(ffn): TransformerLayerWrapper(
(layer): FeedForwardNetwork(
(inner): Dense(2048)
(outer): Dense(512)
)
(input_layer_norm): LayerNorm()
)
)
(3): SelfAttentionEncoderLayer(
(self_attention): TransformerLayerWrapper(
(layer): MultiHeadAttention(
(linear_queries): Dense(512)
(linear_keys): Dense(512)
(linear_values): Dense(512)
(linear_output): Dense(512)
)
(input_layer_norm): LayerNorm()
)
(ffn): TransformerLayerWrapper(
(layer): FeedForwardNetwork(
(inner): Dense(2048)
(outer): Dense(512)
)
(input_layer_norm): LayerNorm()
)
)
(4): SelfAttentionEncoderLayer(
(self_attention): TransformerLayerWrapper(
(layer): MultiHeadAttention(
(linear_queries): Dense(512)
(linear_keys): Dense(512)
(linear_values): Dense(512)
(linear_output): Dense(512)
)
(input_layer_norm): LayerNorm()
)
(ffn): TransformerLayerWrapper(
(layer): FeedForwardNetwork(
(inner): Dense(2048)
(outer): Dense(512)
)
(input_layer_norm): LayerNorm()
)
)
(5): SelfAttentionEncoderLayer(
(self_attention): TransformerLayerWrapper(
(layer): MultiHeadAttention(
(linear_queries): Dense(512)
(linear_keys): Dense(512)
(linear_values): Dense(512)
(linear_output): Dense(512)
)
(input_layer_norm): LayerNorm()
)
(ffn): TransformerLayerWrapper(
(layer): FeedForwardNetwork(
(inner): Dense(2048)
(outer): Dense(512)
)
(input_layer_norm): LayerNorm()
)
)
)
)
(decoder): SelfAttentionDecoder(
(position_encoder): SinusoidalPositionEncoder(
(reducer): SumReducer()
)
(layer_norm): LayerNorm()
(layers): ListWrapper(
(0): SelfAttentionDecoderLayer(
(self_attention): TransformerLayerWrapper(
(layer): MultiHeadAttention(
(linear_queries): Dense(512)
(linear_keys): Dense(512)
(linear_values): Dense(512)
(linear_output): Dense(512)
)
(input_layer_norm): LayerNorm()
)
(attention): ListWrapper(
(0): TransformerLayerWrapper(
(layer): MultiHeadAttention(
(linear_queries): Dense(512)
(linear_keys): Dense(512)
(linear_values): Dense(512)
(linear_output): Dense(512)
)
(input_layer_norm): LayerNorm()
)
)
(ffn): TransformerLayerWrapper(
(layer): FeedForwardNetwork(
(inner): Dense(2048)
(outer): Dense(512)
)
(input_layer_norm): LayerNorm()
)
)
(1): SelfAttentionDecoderLayer(
(self_attention): TransformerLayerWrapper(
(layer): MultiHeadAttention(
(linear_queries): Dense(512)
(linear_keys): Dense(512)
(linear_values): Dense(512)
(linear_output): Dense(512)
)
(input_layer_norm): LayerNorm()
)
(attention): ListWrapper(
(0): TransformerLayerWrapper(
(layer): MultiHeadAttention(
(linear_queries): Dense(512)
(linear_keys): Dense(512)
(linear_values): Dense(512)
(linear_output): Dense(512)
)
(input_layer_norm): LayerNorm()
)
)
(ffn): TransformerLayerWrapper(
(layer): FeedForwardNetwork(
(inner): Dense(2048)
(outer): Dense(512)
)
(input_layer_norm): LayerNorm()
)
)
(2): SelfAttentionDecoderLayer(
(self_attention): TransformerLayerWrapper(
(layer): MultiHeadAttention(
(linear_queries): Dense(512)
(linear_keys): Dense(512)
(linear_values): Dense(512)
(linear_output): Dense(512)
)
(input_layer_norm): LayerNorm()
)
(attention): ListWrapper(
(0): TransformerLayerWrapper(
(layer): MultiHeadAttention(
(linear_queries): Dense(512)
(linear_keys): Dense(512)
(linear_values): Dense(512)
(linear_output): Dense(512)
)
(input_layer_norm): LayerNorm()
)
)
(ffn): TransformerLayerWrapper(
(layer): FeedForwardNetwork(
(inner): Dense(2048)
(outer): Dense(512)
)
(input_layer_norm): LayerNorm()
)
)
(3): SelfAttentionDecoderLayer(
(self_attention): TransformerLayerWrapper(
(layer): MultiHeadAttention(
(linear_queries): Dense(512)
(linear_keys): Dense(512)
(linear_values): Dense(512)
(linear_output): Dense(512)
)
(input_layer_norm): LayerNorm()
)
(attention): ListWrapper(
(0): TransformerLayerWrapper(
(layer): MultiHeadAttention(
(linear_queries): Dense(512)
(linear_keys): Dense(512)
(linear_values): Dense(512)
(linear_output): Dense(512)
)
(input_layer_norm): LayerNorm()
)
)
(ffn): TransformerLayerWrapper(
(layer): FeedForwardNetwork(
(inner): Dense(2048)
(outer): Dense(512)
)
(input_layer_norm): LayerNorm()
)
)
(4): SelfAttentionDecoderLayer(
(self_attention): TransformerLayerWrapper(
(layer): MultiHeadAttention(
(linear_queries): Dense(512)
(linear_keys): Dense(512)
(linear_values): Dense(512)
(linear_output): Dense(512)
)
(input_layer_norm): LayerNorm()
)
(attention): ListWrapper(
(0): TransformerLayerWrapper(
(layer): MultiHeadAttention(
(linear_queries): Dense(512)
(linear_keys): Dense(512)
(linear_values): Dense(512)
(linear_output): Dense(512)
)
(input_layer_norm): LayerNorm()
)
)
(ffn): TransformerLayerWrapper(
(layer): FeedForwardNetwork(
(inner): Dense(2048)
(outer): Dense(512)
)
(input_layer_norm): LayerNorm()
)
)
(5): SelfAttentionDecoderLayer(
(self_attention): TransformerLayerWrapper(
(layer): MultiHeadAttention(
(linear_queries): Dense(512)
(linear_keys): Dense(512)
(linear_values): Dense(512)
(linear_output): Dense(512)
)
(input_layer_norm): LayerNorm()
)
(attention): ListWrapper(
(0): TransformerLayerWrapper(
(layer): MultiHeadAttention(
(linear_queries): Dense(512)
(linear_keys): Dense(512)
(linear_values): Dense(512)
(linear_output): Dense(512)
)
(input_layer_norm): LayerNorm()
)
)
(ffn): TransformerLayerWrapper(
(layer): FeedForwardNetwork(
(inner): Dense(2048)
(outer): Dense(512)
)
(input_layer_norm): LayerNorm()
)
)
)
)
)
2021-11-12 02:50:00.838204: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2021-11-12 02:50:00.838511: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-11-12 02:50:00.839285: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-11-12 02:50:00.839894: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-11-12 02:50:01.524324: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-11-12 02:50:01.525011: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-11-12 02:50:01.525583: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-11-12 02:50:01.526109: W tensorflow/core/common_runtime/gpu/gpu_bfc_allocator.cc:39] Overriding allow_growth setting because the TF_FORCE_GPU_ALLOW_GROWTH environment variable is set. Original config value was 0.
2021-11-12 02:50:01.526158: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1510] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 15405 MB memory: -> device: 0, name: Tesla P100-PCIE-16GB, pci bus id: 0000:00:04.0, compute capability: 6.0
2021-11-12 02:50:01.527000: I main.py:312] Searching the largest batch size between 256 and 16384 with a precision of 256...
2021-11-12 02:50:01.531000: I main.py:312] Trying training with batch size 8320...
2021-11-12 02:50:31.404000: I main.py:312] ... failed.
2021-11-12 02:50:31.410000: I main.py:312] Trying training with batch size 4287...
2021-11-12 02:51:01.902000: I main.py:312] ... failed.
2021-11-12 02:51:01.908000: I main.py:312] Trying training with batch size 2271...
2021-11-12 02:51:32.245000: I main.py:312] ... failed.
2021-11-12 02:51:32.251000: I main.py:312] Trying training with batch size 1263...
2021-11-12 02:52:02.458000: I main.py:312] ... failed.
2021-11-12 02:52:02.463000: I main.py:312] Trying training with batch size 759...
2021-11-12 02:52:32.769000: I main.py:312] ... failed.
2021-11-12 02:52:32.776000: I main.py:312] Trying training with batch size 507...
2021-11-12 02:53:03.043000: I main.py:312] ... failed.
2021-11-12 02:53:03.044000: E main.py:312] Last training attempt exited with an error:
"""
2021-11-12 02:53:01.849184: E tensorflow/stream_executor/cuda/cuda_dnn.cc:362] Loaded runtime CuDNN library: 8.0.5 but source was compiled with: 8.1.0. CuDNN library needs to have matching major version and equal or higher minor version. If using a binary install, upgrade your CuDNN library. If building from sources, make sure the library loaded at runtime is compatible with the version specified during compile configuration.
2021-11-12 02:53:01.851904: E tensorflow/stream_executor/cuda/cuda_dnn.cc:362] Loaded runtime CuDNN library: 8.0.5 but source was compiled with: 8.1.0. CuDNN library needs to have matching major version and equal or higher minor version. If using a binary install, upgrade your CuDNN library. If building from sources, make sure the library loaded at runtime is compatible with the version specified during compile configuration.
Traceback (most recent call last):
File "/usr/lib/python3.7/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/usr/lib/python3.7/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/usr/local/lib/python3.7/dist-packages/opennmt/bin/main.py", line 350, in <module>
main()
File "/usr/local/lib/python3.7/dist-packages/opennmt/bin/main.py", line 312, in main
hvd=hvd,
File "/usr/local/lib/python3.7/dist-packages/opennmt/runner.py", line 284, in train
moving_average_decay=train_config.get("moving_average_decay"),
File "/usr/local/lib/python3.7/dist-packages/opennmt/training.py", line 122, in __call__
self._steps(dataset, accum_steps=accum_steps, report_steps=report_steps)
File "/usr/local/lib/python3.7/dist-packages/opennmt/training.py", line 262, in _steps
loss = forward_fn()
File "/usr/local/lib/python3.7/dist-packages/tensorflow/python/eager/def_function.py", line 885, in __call__
result = self._call(*args, **kwds)
File "/usr/local/lib/python3.7/dist-packages/tensorflow/python/eager/def_function.py", line 950, in _call
return self._stateless_fn(*args, **kwds)
File "/usr/local/lib/python3.7/dist-packages/tensorflow/python/eager/function.py", line 3040, in __call__
filtered_flat_args, captured_inputs=graph_function.captured_inputs) # pylint: disable=protected-access
File "/usr/local/lib/python3.7/dist-packages/tensorflow/python/eager/function.py", line 1964, in _call_flat
ctx, args, cancellation_manager=cancellation_manager))
File "/usr/local/lib/python3.7/dist-packages/tensorflow/python/eager/function.py", line 596, in call
ctx=ctx)
File "/usr/local/lib/python3.7/dist-packages/tensorflow/python/eager/execute.py", line 60, in quick_execute
inputs, attrs, num_outputs)
tensorflow.python.framework.errors_impl.InternalError: 2 root error(s) found.
(0) Internal: cuDNN launch failure : input shape ([1,500,512,1])
[[node transformer_base_1/self_attention_decoder_1/self_attention_decoder_layer_6/transformer_layer_wrapper_42/layer_norm_46/FusedBatchNormV3 (defined at /local/lib/python3.7/dist-packages/opennmt/layers/common.py:128) ]]
[[Func/gradients/global_norm/write_summary/summary_cond/then/_267/input/_804/_56]]
(1) Internal: cuDNN launch failure : input shape ([1,500,512,1])
[[node transformer_base_1/self_attention_decoder_1/self_attention_decoder_layer_6/transformer_layer_wrapper_42/layer_norm_46/FusedBatchNormV3 (defined at /local/lib/python3.7/dist-packages/opennmt/layers/common.py:128) ]]
0 successful operations.
0 derived errors ignored. [Op:__inference__forward_32883]
Function call stack:
_forward -> _forward
"""
Traceback (most recent call last):
File "/usr/local/bin/onmt-main", line 8, in <module>
sys.exit(main())
File "/usr/local/lib/python3.7/dist-packages/opennmt/bin/main.py", line 312, in main
hvd=hvd,
File "/usr/local/lib/python3.7/dist-packages/opennmt/runner.py", line 202, in train
training=True, num_replicas=num_replicas, num_devices=num_devices
File "/usr/local/lib/python3.7/dist-packages/opennmt/runner.py", line 151, in _finalize_config
mixed_precision=self._mixed_precision,
File "/usr/local/lib/python3.7/dist-packages/opennmt/runner.py", line 625, in _auto_tune_batch_size
"Batch size autotuning failed: all training attempts exited with an error "
RuntimeError: Batch size autotuning failed: all training attempts exited with an error (see last error above). Either there is not enough memory to train this model, or unexpected errors occured. Please try to set a fixed batch size in the training configuration.
After some additional debugging it seem that the problem is that google colab come with CUDA 11.1, but Tensorflow 2.7 require CUDA 11.2
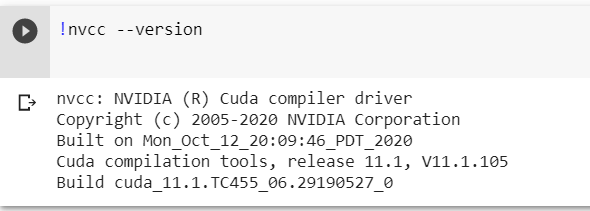
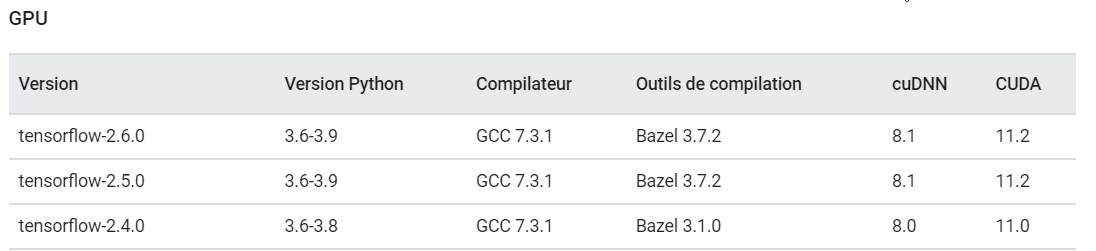
There are no version of Tensorflow that match the one of CUDA. If I try to change the Tensorflow/Ctranslate2 version to 2.4, I get this error when running onmt-main:
/bin/bash: onmt-main: command not found
I’m kind of stuck has changing the CUDA version is a pain in Colab.