Hi,
Presently I am training the model for ENG to GER language translation.
The dataset has following number of lines :
SOURCE DATA
(base) fujiadmin@offlinetranslation:~/pytorch/OpenNMT-py/data$ wc -l europarl-v7.de-en.en
1920209 europarl-v7.de-en.en
DESTINATION DATA
(base) fujiadmin@offlinetranslation:~/pytorch/OpenNMT-py/data$ wc -l europarl-v7.de-en.de
1920209 europarl-v7.de-en.de
Out of the above 1920209 lines I have used 5000 lines as validation text for both source and destination.
I am getting the following error message after the training 10000 epochs of the total of 100000 epochs.
The error messages are as follows:
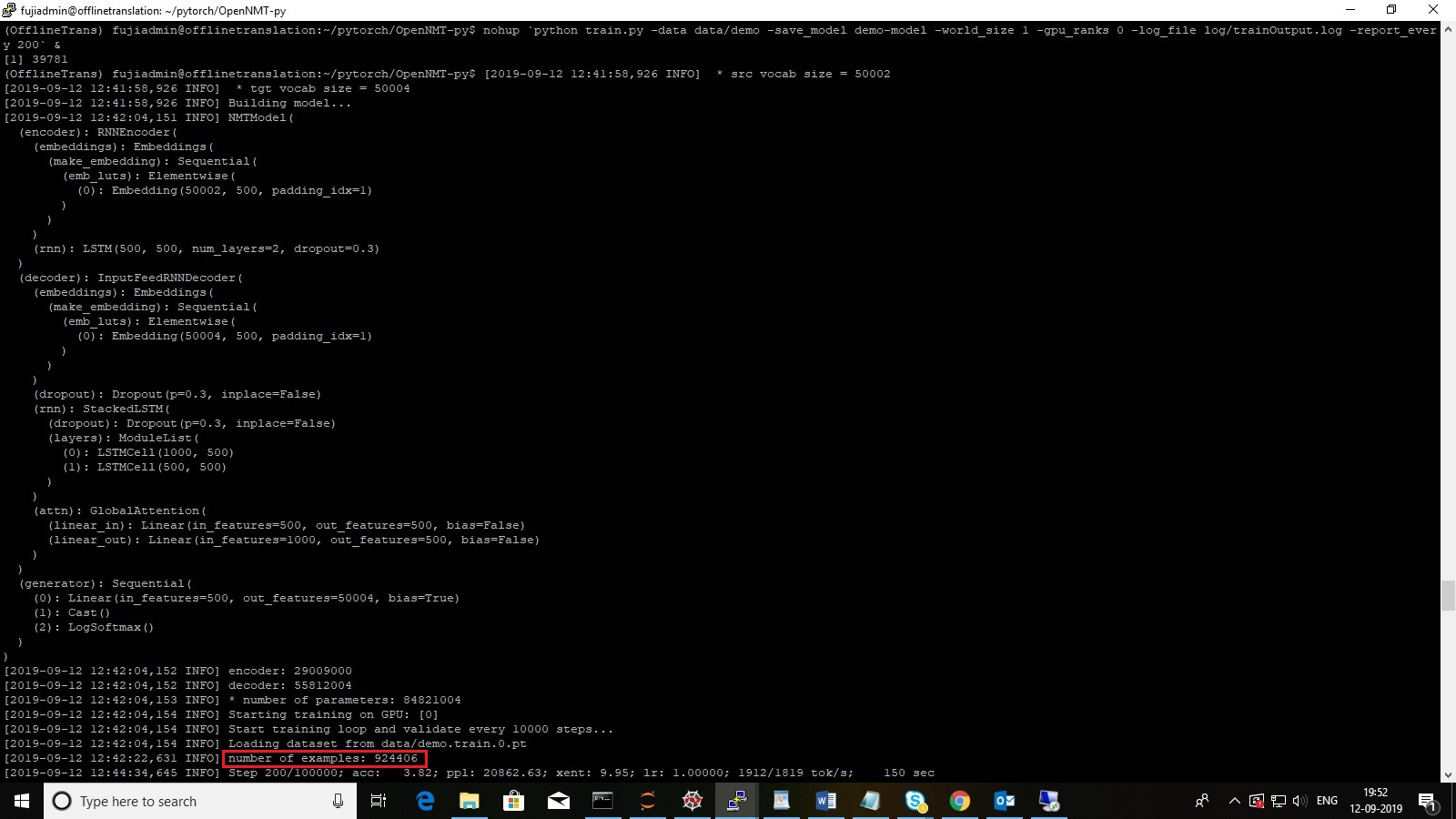
number of examples: 924406 as marked in RED
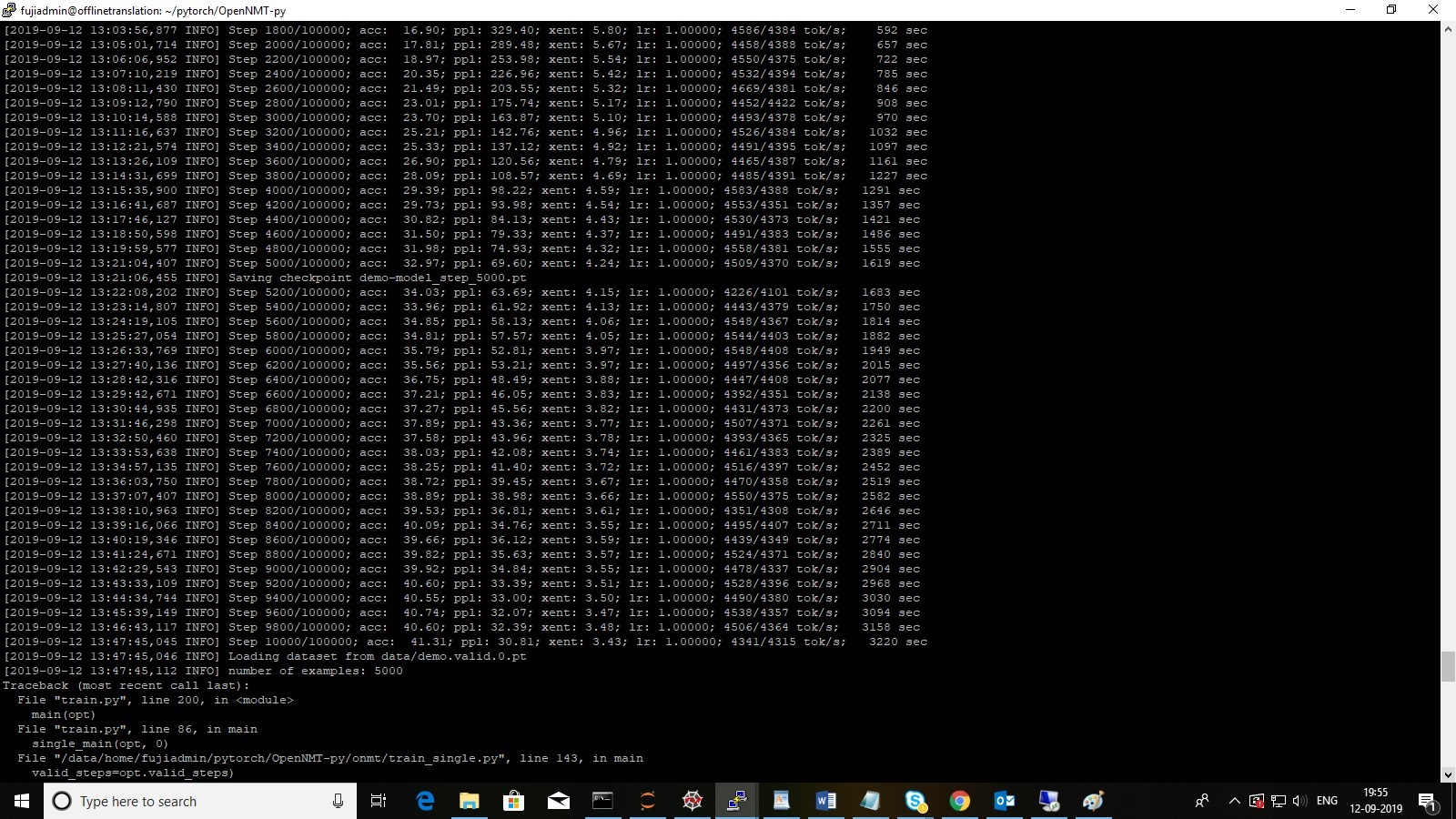
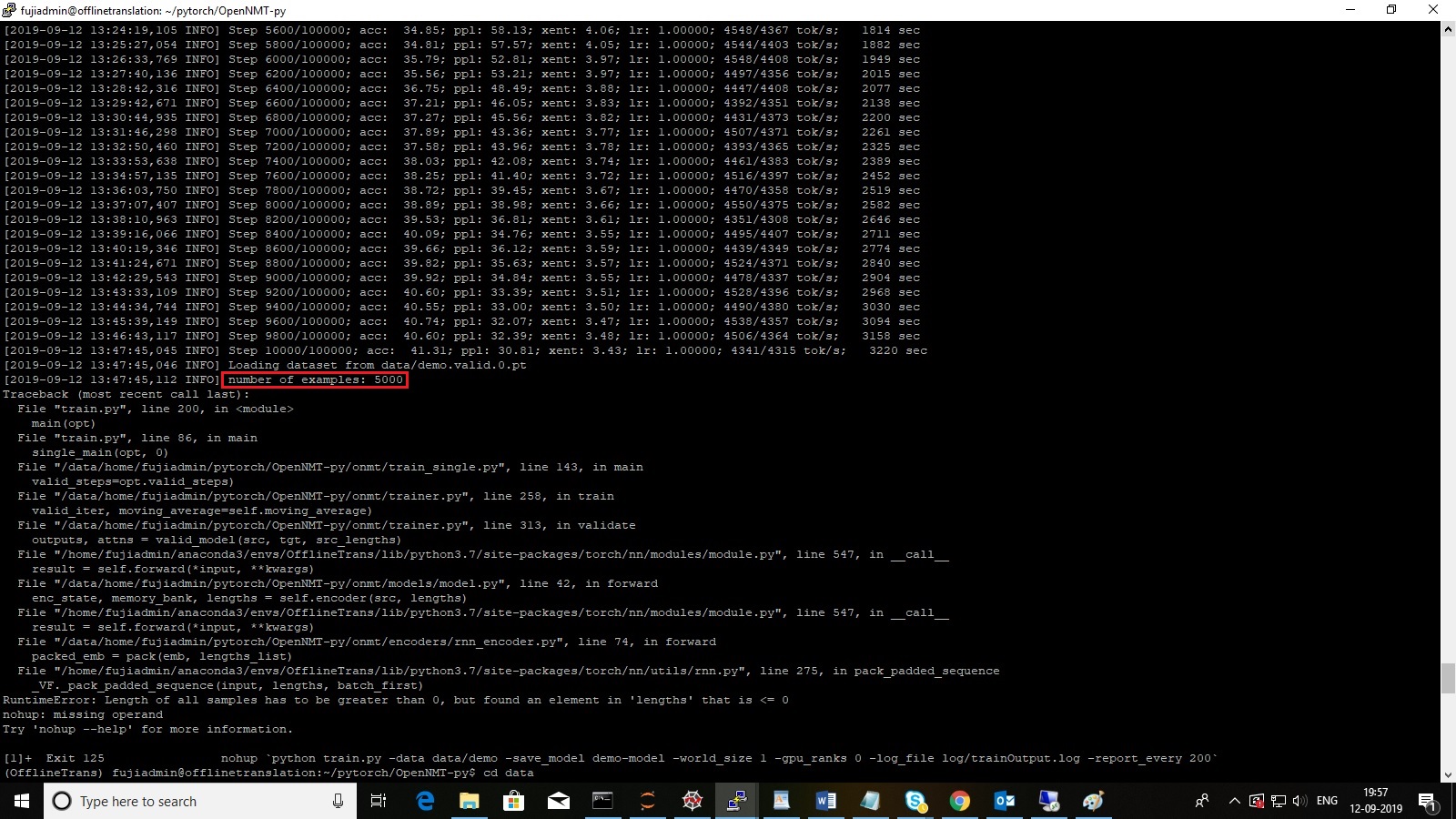
** number of examples: 5000** as marked in RED
Could someone please assist me in resolving this issue ?
Thank You,
Kishor.