Hello,
Training with OpenNMT-tf I’m using tensorboard to keep an eye on progress.
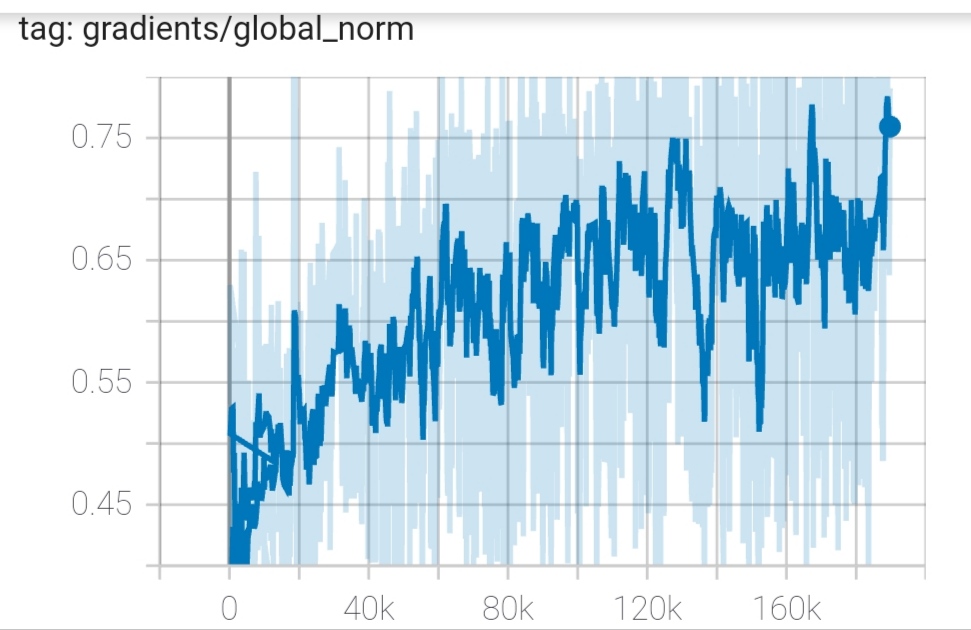
Using back-translation, it’s giving me unusual charts. The BLEU score climbed for 0.5-1 point after 189k training steps.
Could someone interpret these charts and maybe have an insight what is going on?!

Hi,
Is it the increasing evaluation loss that you find unusual?
Gradient I find it unusual, training with just the parallel corpus it used to go down but now it’s going the opposite direction, it’s climbing up!
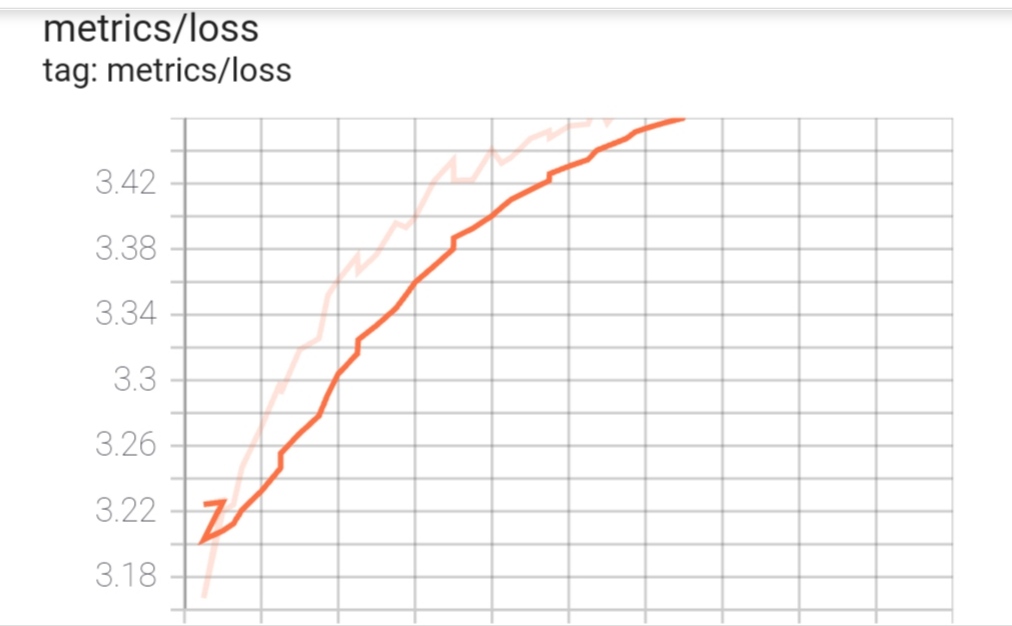
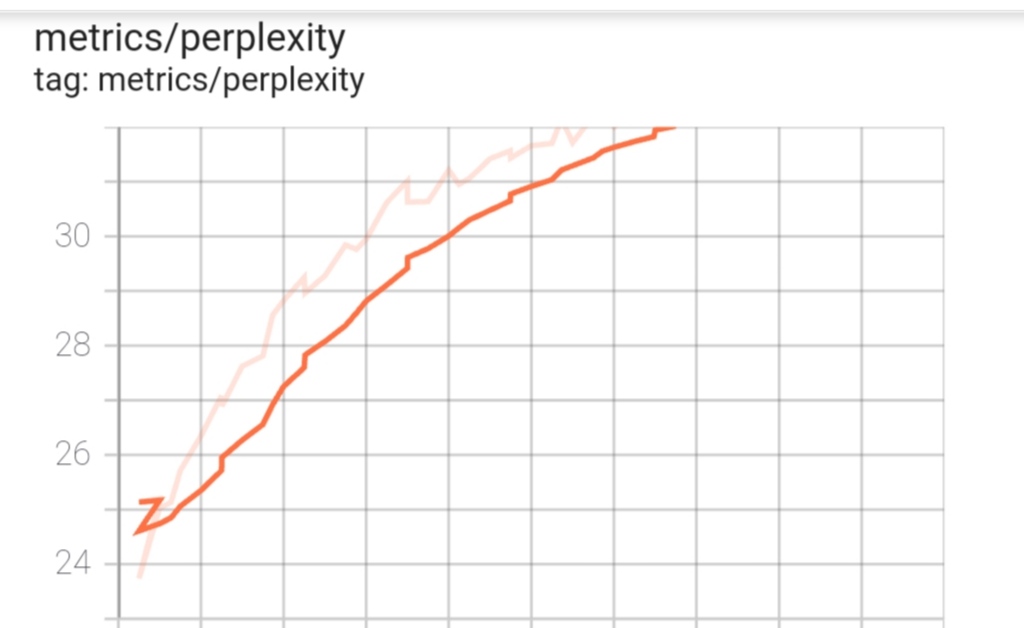
And yes loss and perplexity are also climbing up even though I’m getting a better BLEU score.
There are two charts for loss one is climbing up and the other is climbing down!
Blue lines are coming from the training and orange lines are coming from the evaluation (see the legend on the left in TensorBoard).
Can you post the full training logs?
I’m training with Kaggle, it doesn’t show the full log, but here is what I can get quickly.
This is data.yml, training data 200k, monolingual cynthatic data 470k:
model_dir: /kaggle/working/run
data:
train_features_file:
- /kaggle/input/abrudata/tgt-train.txt
- …/input/process-mono/mono_ru.txt
train_labels_file:
- /kaggle/input/abrudata/src-train.txt
- …/input/process-mono/mono_ab.txt
train_files_weights:
- 0.8
- 0.2
eval_features_file: /kaggle/input/abrudata/tgt-val.txt
eval_labels_file: /kaggle/input/abrudata/src-val.txt
source_vocabulary: /kaggle/input/abrudata/tgt-vocab.txt
target_vocabulary: /kaggle/input/abrudata/src-vocab.txt
train:
sample_buffer_size: 3000000
maximum_features_length: 500
maximum_labels_length: 500
save_checkpoints_steps: 12500
keep_checkpoint_max: 1
max_step: 200000
This is the log that I could get from Kaggle:
2020-10-13 22:56:46.865185: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1
2020-10-13 22:56:51.262009: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcuda.so.1
2020-10-13 22:56:51.621960: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-10-13 22:56:51.622755: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1716] Found device 0 with properties:
pciBusID: 0000:00:04.0 name: Tesla P100-PCIE-16GB computeCapability: 6.0
coreClock: 1.3285GHz coreCount: 56 deviceMemorySize: 15.90GiB deviceMemoryBandwidth: 681.88GiB/s
2020-10-13 22:56:51.622820: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1
2020-10-13 22:56:51.744104: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcublas.so.10
2020-10-13 22:56:51.794706: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcufft.so.10
2020-10-13 22:56:51.806070: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcurand.so.10
2020-10-13 22:56:51.914007: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcusolver.so.10
2020-10-13 22:56:51.926480: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcusparse.so.10
2020-10-13 22:56:52.117721: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudnn.so.7
2020-10-13 22:56:52.118196: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-10-13 22:56:52.119891: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-10-13 22:56:52.120600: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1858] Adding visible gpu devices: 0
2020-10-13 22:56:52.987448: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN)to use the following CPU instructions in performance-critical operations: AVX2 AVX512F FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2020-10-13 22:56:52.994601: I tensorflow/core/platform/profile_utils/cpu_utils.cc:104] CPU Frequency: 2000175000 Hz
2020-10-13 22:56:52.994889: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x5566008a6fa0 initialized for platform Host (this does not guarantee that XLA will be used). Devices:
2020-10-13 22:56:52.994932: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version
2020-10-13 22:56:53.117815: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-10-13 22:56:53.118725: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x556600882780 initialized for platform CUDA (this does not guarantee that XLA will be used). Devices:
2020-10-13 22:56:53.118764: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Tesla P100-PCIE-16GB, Compute Capability 6.0
2020-10-13 22:56:53.120143: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-10-13 22:56:53.120865: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1716] Found device 0 with properties:
pciBusID: 0000:00:04.0 name: Tesla P100-PCIE-16GB computeCapability: 6.0
coreClock: 1.3285GHz coreCount: 56 deviceMemorySize: 15.90GiB deviceMemoryBandwidth: 681.88GiB/s
2020-10-13 22:56:53.120943: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1
2020-10-13 22:56:53.121004: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcublas.so.10
2020-10-13 22:56:53.121031: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcufft.so.10
2020-10-13 22:56:53.121056: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcurand.so.10
2020-10-13 22:56:53.121081: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcusolver.so.10
2020-10-13 22:56:53.121105: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcusparse.so.10
2020-10-13 22:56:53.121136: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudnn.so.7
2020-10-13 22:56:53.121270: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-10-13 22:56:53.122041: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-10-13 22:56:53.122678: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1858] Adding visible gpu devices: 0
2020-10-13 22:56:53.122741: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1
2020-10-13 22:56:53.932294: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1257] Device interconnect StreamExecutor with strength 1 edge matrix:
2020-10-13 22:56:53.932356: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1263] 0
2020-10-13 22:56:53.932371: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1276] 0: N
2020-10-13 22:56:53.932722: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-10-13 22:56:53.933626: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-10-13 22:56:53.934326: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1402] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 14951 MB memory) -> physical GPU (device: 0, name: Tesla P100-PCIE-16GB, pci bus id: 0000:00:04.0, compute capability: 6.0)
2020-10-13 22:57:58.801861: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcublas.so.10
2020-10-13 22:58:08.521585: I tensorflow/core/kernels/data/shuffle_dataset_op.cc:172] Filling up shuffle buffer (this may take a while): 725731 of 3000000
2020-10-13 22:58:18.521592: I tensorflow/core/kernels/data/shuffle_dataset_op.cc:172] Filling up shuffle buffer (this may take a while): 1549125 of 3000000
2020-10-13 22:58:28.521599: I tensorflow/core/kernels/data/shuffle_dataset_op.cc:172] Filling up shuffle buffer (this may take a while): 2426457 of 3000000
2020-10-13 22:58:35.245545: I tensorflow/core/kernels/data/shuffle_dataset_op.cc:221] Shuffle buffer filled.
2020-10-13 22:58:36.877456: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudnn.so.7
Hello everyone,
I’m training with back-translation.
Each training session lasts for 9 hours (10k steps), at the beginning of each session the loss drops drastically, then keeps climbing up to the highest loss at the end of each session.
Any idea why I’m seeing this behaviour?

Is it still the same configuration that you posted above?
What is the command that you are launching to start each training session?
It’s possible that I found out the problem, I added the wrongs tags to the synthetic corpus.
It’s a different configuration:
train_files_weights:
- 0.3 (parallel corpus 200K)
- 0.05 (parallel corpus without punctuation 200K)
- 0.12 (synthetic corpus 4.25M)
- 0.12 (synthetic corpus 4.25M)
- 0.12 (synthetic corpus 4.25M)
- 0.12 (synthetic corpus 4.25M)
- 0.12 (synthetic corpus 4.25M)
- 0.05 (copy from target to source 7M)
source_vocabulary: …/input/abrudata/v6-v10-v3/src-tgt-vocab.txt
target_vocabulary: …/input/abrudata/v6-v10-v3/src-tgt-vocab.txt
train:
sample_buffer_size: 2000000
maximum_features_length: 800
maximum_labels_length: 800
save_checkpoints_steps: “”" + str(steps) + “”"
keep_checkpoint_max: 1
max_step: “”" + str(found) + “”"
“”"
The command line I am using to start each session:
!onmt-main --model_type TransformerRelative --config data.yml \
--auto_config train