I have a nice occasion to test such a procedure. I have a in-domain data set D with 184K sentences, FR->DE. These data are very particular:
- a lot of in-domain specific (technical) words. Some sentences, or part of sentences, are ordinary formulations, while others are quite specific.
- many sentences are uppercased with or without diacritics. Some of them are present in several copies with different forms.
Due to the small size of the set, I need to train with generic sentences, to get general vocab and general formulations. The in-domain data are certainly not sufficient to get a good model. But:
- in-domain specific words are OOV for the generic model
- words without diacritics are also OOV, even if their well formed forms are in the generic model
- fully uppercased sentences are confusing for the feature part of a training done with a generic model
First of all, I took 2K sentences V from D for the validation set. To avoid any kind of overlapping, I built training set T from D by removing all sentences similar to the one of V when converted as lowercased, without diacritic, and all numbers replaced by a single “8”. T is then 130K sentences. I finally took 2K sentences from T to build a checking set C.
1) mixing with 2M Europarl set E
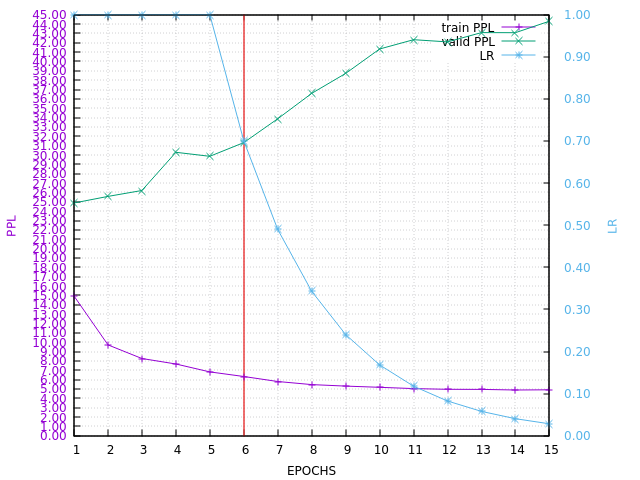
I mixed 5 x T with E, so that in-domain data are around 30% of Europarl data. I made 5 epochs at LR=1, then 10 epochs decreasing it with a 0.7 factor each.
50K words in vocabs = all possible in-domain words + a complement from Europarl vocab (highest occurrences first).
DURATION=57H
Here is the PPL learning curve:
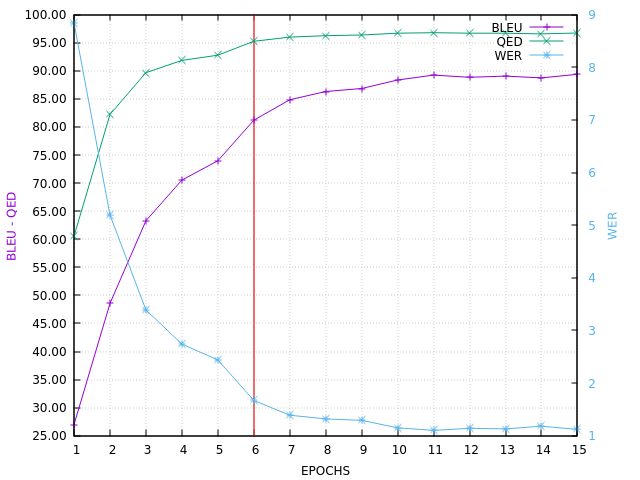
Here is the CHECK BLEU curve, ending with BLEU=89.36 on in-domain set C
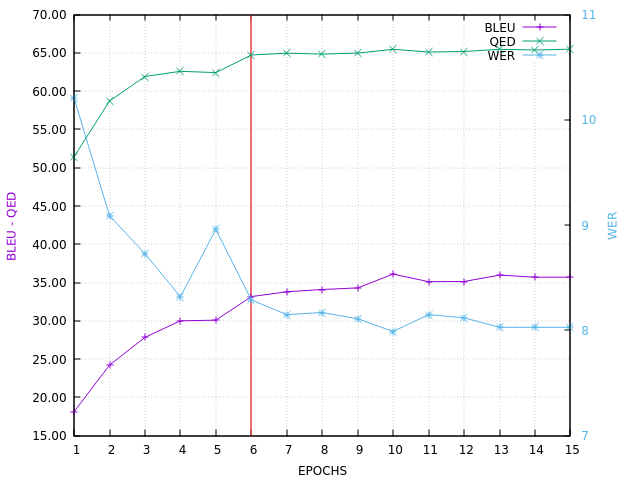
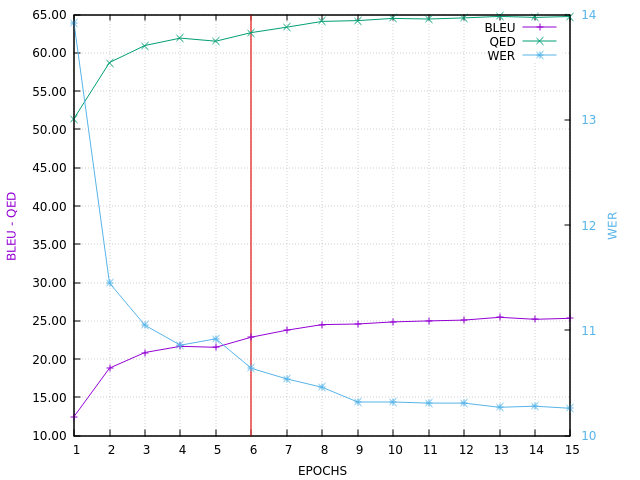
Here is the VALID BLEU curve, ending with BLEU=35.7 on in-domain set V
2) Europarl alone
I built a checking set Ce of 2K sentences from Europarl training set E.
50K words in vocabs = 40K words from from Europarl vocab + 10K UNDEFn words.
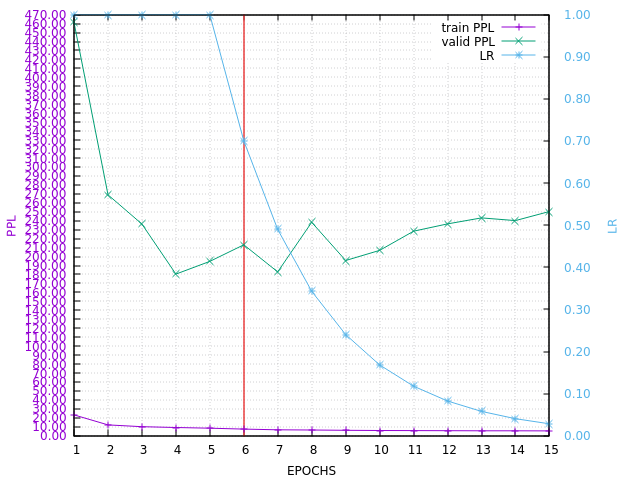
Same learning strategy with 2M E as learning set.
DURATION=51H
Here is the PPL learning curve (of course huge in-domain valid PPL !):
Here is the CHECK BLEU curve, ending with BLEU=25.33 on Europarl set Ce
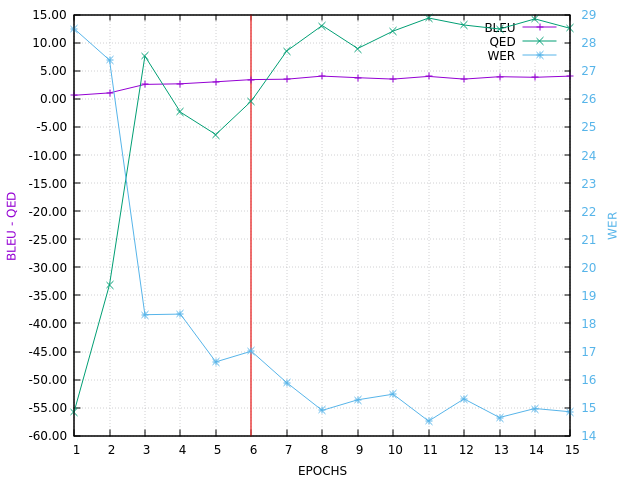
Here is the VALID BLEU curve, ending with (AWFUL !) BLEU=4.04 on in-domain set V (QED can be negative in such a situation):
3) updating Europarl model with in-domain retraining
50K words in vocabs = update of the step 2 vocabs where 10k UNDEFn words were replaced by in-domain vocab (highest occurrences first)
Same learning strategy, but starting with step 2 model, with 130K T as training set.
DURATION=73MN
Of course, Europarl training is supposed to be done only once for many training…
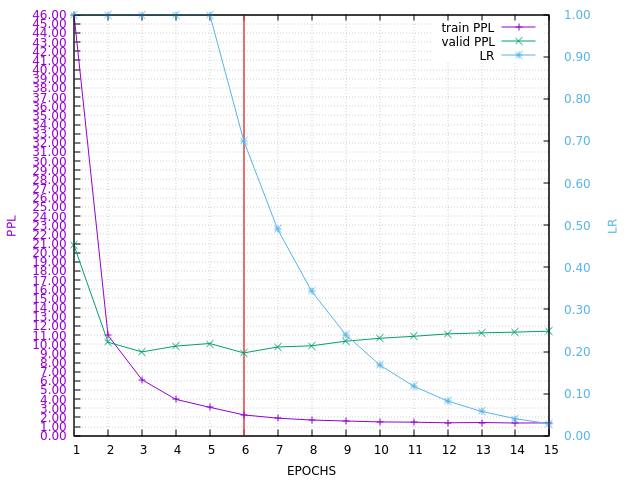
Here is the PPL learning curve:
Here is the CHECK BLEU curve, ending with BLEU=71.16 on in-domain set C
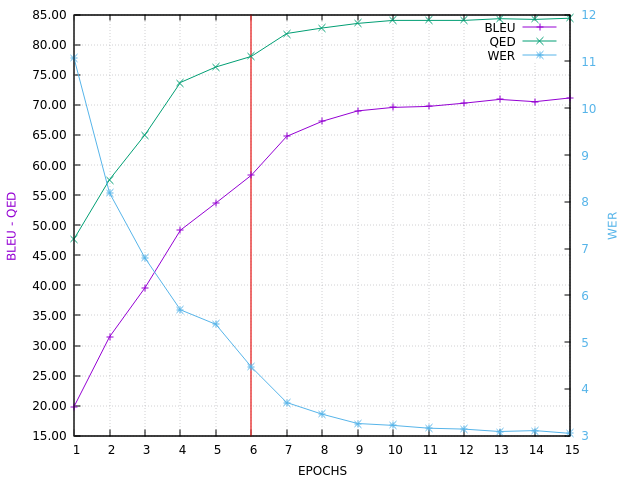
Here is the VALID BLEU curve, ending with BLEU=34.0 on in-domain set V
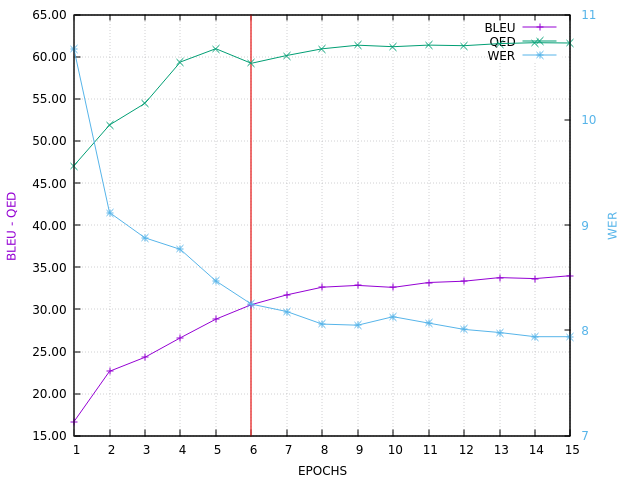
34.0 is quite near from the 35.7 obtain at step 1. Certainly something better could be done, for example by mixing few copies of T together (like it’s the case in step 1) or increasing the number of epochs. Also, more than 10K UNDEFn words, replaced later by more in-domain words, can be used…
This 34.0 was obtained in 73MN, comparing to 57H for the 35.7…
Just a first experimentation…









