Hi, I have a very strange behavior with the bi-directional RNN network. I trained my translation model with 100k sentence pairs and after some steps, the evaluation loss is increasing.
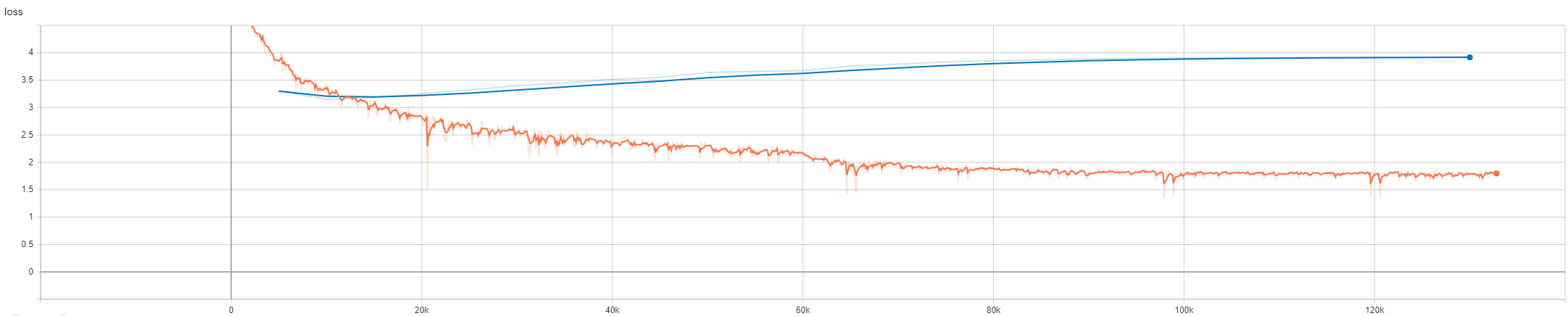
However, when I test the model with my test dataset at checkpoint step 40k, I get the BLEU of 16.54. I did the same with the model at checkpoint step 100k and I get BLEU of 18.25.
To my knowledge, evaluation loss increases means the model is overfitting and should perform worse when the model meet new sentences. Somehow the model in this experiment can perform even better although evaluation loss is increasing.
Is this behavior normal?
This is my config file for my experiment
model_dir: model
data:
eval_features_file: cv.dev.cn
eval_labels_file: cv.dev.vn
source_words_vocabulary: src-vocab.txt
target_words_vocabulary: tgt-vocab.txt
train_features_file: cv.train.cn
train_labels_file: cv.train.vn
eval:
batch_size: 32
eval_delay: 0
exporters: last
infer:
batch_size: 32
bucket_width: 0
params:
average_loss_in_time: true
beam_width: 5
learning_rate: 0.001
clip_gradients: 5
label_smoothing: 0.1
length_penalty: 0
gradients_accum: 1
optimizer: AdamOptimizer
optimizer_params:
beta1: 0.9
beta2: 0.999
decay_type: exponential_decay
decay_params:
decay_rate: 0.5
decay_steps: 10000
staircase: true
decay_step_duration: 1
start_decay_steps: 50000
score:
batch_size: 64
train:
average_last_checkpoints: 8
batch_size: 4096
batch_type: tokens
keep_checkpoint_max: 8
maximum_features_length: 50
maximum_labels_length: 50
sample_buffer_size: -1
save_checkpoints_steps: 5000
save_summary_steps: 100
train_steps: 200000
And my model
import tensorflow as tf
import opennmt as onmt
def model():
return onmt.models.SequenceToSequence(
source_inputter=onmt.inputters.WordEmbedder(
vocabulary_file_key="source_words_vocabulary",
embedding_size=512
),
target_inputter=onmt.inputters.WordEmbedder(
vocabulary_file_key="target_words_vocabulary",
embedding_size=512
),
encoder=onmt.encoders.BidirectionalRNNEncoder(
num_layers=2,
num_units=512,
reducer=onmt.layers.ConcatReducer(),
cell_class=tf.nn.rnn_cell.LSTMCell,
dropout=0.2,
residual_connections=False
),
decoder=onmt.decoders.AttentionalRNNDecoder(
num_layers=2,
num_units=512,
bridge=onmt.layers.CopyBridge(),
attention_mechanism_class=tf.contrib.seq2seq.LuongAttention,
cell_class=tf.contrib.rnn.LSTMCell,
dropout=0.2,
residual_connections=False))