Here is a quantified experiment of this w2v-coupled method (with fixed embeddings, since ONMT currently doesn’t want to update vec layers in the second part):
Having a stable training enables several possibilities that were very hard, or impossible, before without facing the bad over-fitting behaviour of NMT:
- long-training, that could bring much more finalized models than with an early-stopping procedure
- mixing N copies of a small in-domain data set with 1 copy of a large generic data set, so that, each epoch of the 1/N mixed data set is equivalent to 1 epoch of the generic data set and N epochs of the specific one. With N low, the in-domain data are not enough represented in front of the generic ones. With N high, each short-training is equivalent to a long-training with the in-domain data
- using of a much more large network that can handle more finely numerous long and complex formulations
I did this test on a FR->EN “food & cooking” data set:
- 59319 sentences in the training set
- 14829 sentences in the validation set
Of course, all double-pairs were removed.
10 copies of this training set were mixed with 2007723 Europarl sentences. The whole in-domain set is then almost 30% of the Europarl set. On the curve below, 8 epochs are equivalent to 80 epochs on the F&C training set.
ONMT config:
- vector size 200
- 2 layers of size 1000
Here is the current training curve (I will update it when next epochs will be done):
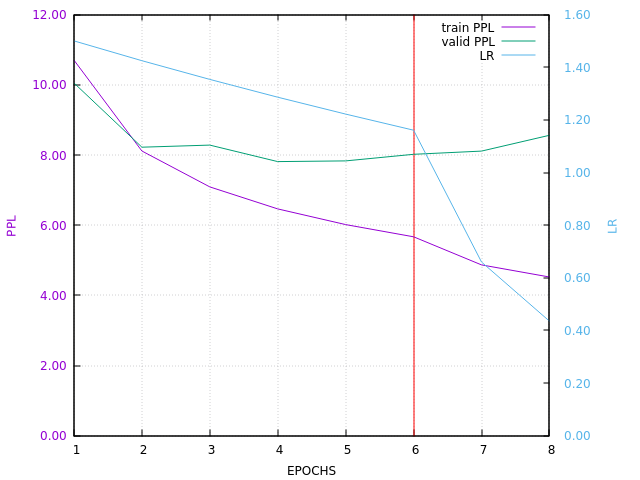
Keep in mind that the validation PPL is not pertinent, as said here:
The BLEU evaluation also is not perfect, but here it is, done on the validation set:
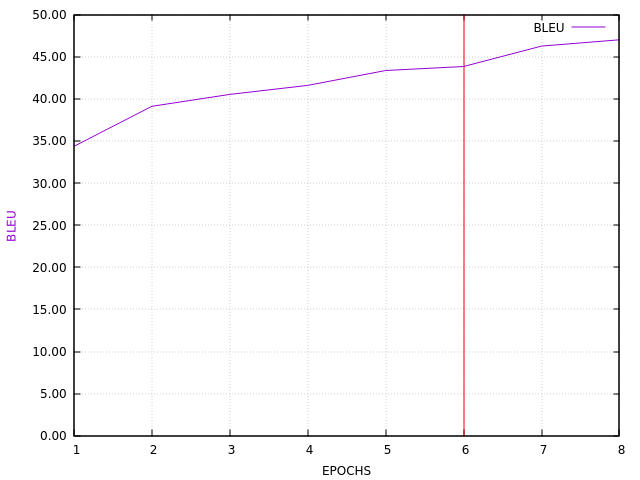
Here are some translation samples (note that there are also errors in the original data):
SRC: Mettez au frigo en attente , mais ne servez pas trop froids .
REF: Refrigerate until needed , but do not serve too cold .
ONMT: Keep in the fridge , but not serve too cold .
SRC: Servir en entrée ou en accompagnement d’ une viande grillée.variante :
REF: Serve as an appetizer or as a side dish for grilled meat.variation :
ONMT: Serve as an appetizer or as a side dish for grilled meat :
SRC: Commencez par éplucher les pommes de terre puis coupez les selon la forme souhaitée .
REF: Start by peeling the potatoes and cutting them into the desired shape .
ONMT: Start by peeling the potatoes and cut them into the desired form .
SRC: saumons destinés à la fabrication de pâté ou de pâte à tartiner
REF: salmon for manufacture into pastes or spreads
ONMT: salmon destined for the manufacture of pâté or batter
SRC: Cuire au four pendant 12 minutes ou jusqu ’ à ce que les asperges soient cuites , mais toujours croquantes .
REF: Bake for 12 minutes , or until asparagus is cooked but still crisp .
ONMT: Bake for 12 minutes or until asparagus is cooked , but still crisp .
SRC: 1 kg de myrtilles sauvages , 400 g de sucre , 1/4 de citron non traité , avec sa peau .
REF: 1 kg fresh blueberries 150 ml water 350 g granulated sugar ¼ unwaxed lemon with peel on
ONMT: 1 kg of wild blueberries , 400 g granulated sugar a knob of butter ( optional )
SRC: Le vent sèche le dessus de l’ eau très concentrée en sel ( qui deviendras plus tard du sel de mer ) et donne des cristaux très fins : la fleur de sel .
REF: The wind dries the surface of the water which has a high salt concentration ( this will later become sea salt ) producing thin flaky crystals .
ONMT: The dry wind of very concentrated water in salt ( who later comes to sea salt ) and gives very thin crystal : the flower flower .
SRC: L’ activité d’ une antitoxine ou d’ un antisérum doit être déterminée par une méthode acceptable et , lorsqu ’ il y a lieu , l’ unité d’ activité doit être l’ unité internationale .
REF: The potency of an antitoxin or antiserum shall be determined by an acceptable method and where applicable the unit of potency shall be the International Unit .
ONMT: The potency of antitoxin or antiserum shall be determined by an acceptable method and , the unit of potency must be the International Unit .
SRC: Après les avoir bien blanchies , on fait confire tout doucement des lanières d’ écorce de pamplemousse .
REF: After soakiing , strips of grapefruit skin are cooked very slowly to conservethem in sugar .
ONMT: After having blanched well , you can cook it with strips of grapefruit peel .
SRC: 1 heure Mettez cette pâte en forme de galette , entourez la de film étirable et mettez au frigo pour 1 heure ou 2 .
REF: 1 hour Form the dough into a flat cake and wrap in stretch plastic film . Put in the fridge for 1 or 2 hours .
ONMT: 1 hour Put this dough into a flat cake and wrap in stretch plastic film . Refrigerate for 1 or 2 hours .




