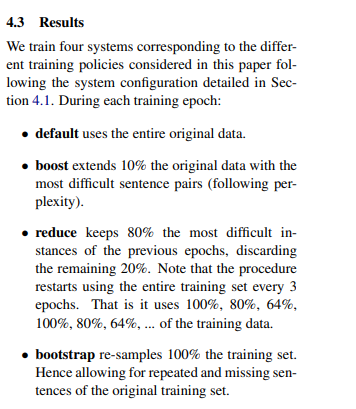
This paper says it used OpenNMT to implement ‘boosting’ techniques to improve the performance of NMT systems, such as removing some of the easiest sentences each epoch/training step based on sentence perplexity.
These are the full details on the techniques they used:
How could these techniques be implemented via OpenNMT?
I would have added an extra step between step 2 and 3:
Calculate BLEU score between training data and the training data translated by the model. Filter out those with really poor BLEU score and with a predict score high. These cases are most likely wrong translation/ incorrect alignment.