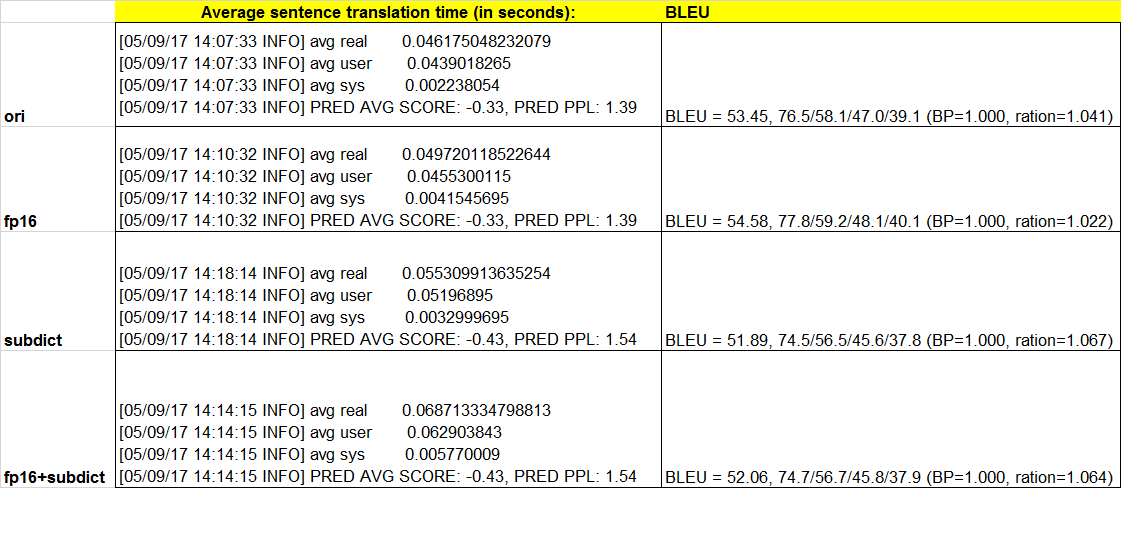
target_subdict is to be used when using a large vocabulary (I would say over 50k). Then it accelerates your decoding - to initialize it, you can use a phrase table and be very generous when picking up target words. For a 100k target vocabulary, and regular network size, if you provide ~30k target words in the sub-dictionary, you will get about 2x throughput.
You might lose a little bit in quality - but it should not be very low if you extract enough target candidates.