I’m reffering to a script that is not merged yet, see PR#398
Using vocabularies from OpenNMT-py preprocessing outputs, embeddings_to_torch.py generate encoder and decoder embeddings initialized with GloVe’s values.
the script is a slightly modified version of ylhsieh’s one.
Thank you for the tutorial!
I wanted to know what happens to words that are not found in the pre-trained embeddings? Are they considered as OOV/unk when training?
Not really. Word that aren’t found in pre-trained embeddings just wont be initialized i.e. 0 valued tensor.
In fact, I’m not sure what a different initialization would do. You should then let the model train the embedding (not fixing it) in order to fill the gaps.
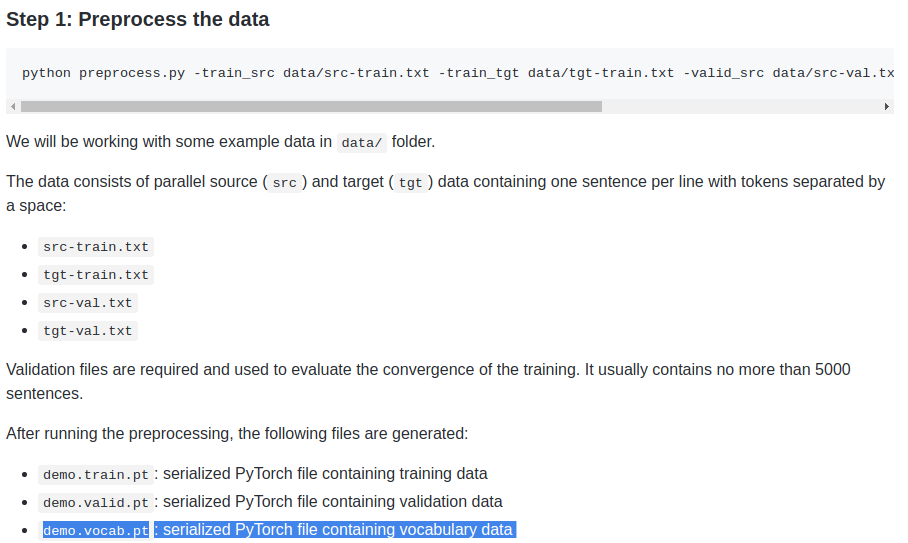
Thank you for the tutorial. On Step 3, you set the dictionary file as a parameter which ends in a ‘.pt’. After I run the preprocess.py script, I receive two dictionary files as output ending in ‘.dict’. These files have the following format:
you 4
the 5
to 6
a 7
of 8
I 9
that 10
…
What is the format of the lines within ‘data.vocab.pt’? Is there a way I can derive that file from the two .dict files I have?
Thanks
Preprocessing construct vocabularies (source, and target), and create numerical representation of source/target by mapping words with the corresponding vocabulary id.
Then, the train.pt (resp valid.pt) contain tensors that represents both source and target training (resp. valid) sequences. The vocabularies are built from the training dataset, and stored in vocab.pt.
Thx for the detail explanation, pltrdy. But when you say “the train.pt (resp valid.pt) contain tensors that represents both source and target training (resp. valid) sequences”. Tensors here mean the vocabulary id, right?
Hey! I was wondering what happens when one does the translation from say German->English and wants to use GloVe word embeddings. I couldn’t find pretrained GloVe word embeddings for German language.
If I only want to use English word embeddings, how to load it for my custom vocabulary. Say I have a vocabulary of 10000 English words, how to load this weight to initialize Embedding weight?
preprocess.py requires -train_tgt, -valid_src and so on…
If I only have a captions.txt, which contains captions line by line. I want to process it to a vocab(index to word mapping or word to index mapping) and corresponding Embedding weight, how to process it? can you give me a example or which opts should I set?
I am getting the following error, any idea how to fix it please?
‘’’
(cheny) [cheny@elgato-login OpenNMT-py]$ ./tools/embeddings_to_torch.py -emb_file “/extra/cheny/glove.840B.300d.txt” -dict_file “/extra/cheny/gpu.vocab.pt” -output_file "data/grammar_checker/embeddings"
From: /extra/cheny/gpu.vocab.pt
* source vocab: 50002 words
* target vocab: 50004 words
Traceback (most recent call last):
File “./tools/embeddings_to_torch.py”, line 94, in
main()
File “./tools/embeddings_to_torch.py”, line 63, in main
embeddings = get_embeddings(opt.emb_file)
File “./tools/embeddings_to_torch.py”, line 39, in get_embeddings
embs[l_split[0]] = [float(em) for em in l_split[1:]]
File “./tools/embeddings_to_torch.py”, line 39, in
embs[l_split[0]] = [float(em) for em in l_split[1:]]
ValueError: could not convert string to float: ‘.’
I figure out what goes wrong now. It is caused by the bug of the pre-trained word-embedding vectors.
Let word-embedding vectors be ‘l’.
get_embeddings(file) assumes elements in l[1:] is numerical string (that can be ‘floated’). This is not always true. Many time l[1] or l[2] may be ‘.’.
> def get_embeddings(file):
> embs = dict()
> for l in open(file, 'rb').readlines():
> l_split = l.decode('utf8').strip().split()
> if len(l_split) == 2:
> continue
> embs[l_split[0]] = [float(em) for em in l_split[1:]]
> print("Got {} embeddings from {}".format(len(embs), file))
>
> return embs
What are the best strategies to deal with this error? Fix the word-embedding file separately, or define extra steps in get_embeddings(file) to detect and fix or ignore the error vector on the fly?
@lucien0410 solved this by changing the unicode character used to split the characters in l_split = l.decode(‘utf8’).strip().split() make sure the embeddings file uses the same unicode character to separate the vector components.
@pltrdy can you check the issue I posted here? I even get good results after changing the provided embeddings_to_torch.py script?